
Mots-clés:BAGEL-7B-MoT, GPT-4o, Modèle d’IA multimodale, Génération d’images, OpenAI o3, Vulnérabilité du noyau Linux, Théorie du calcul MIT, Raisonnement et suivi d’instructions en IA, Modèle d’IA open source de ByteDance, Architecture hybride de transformateurs experts, Vulnérabilité CVE-2025-37899, Compromis entre temps de calcul et mémoire, Benchmark d’évaluation MathIF
🔥 Focus
ByteDance publie en open source BAGEL, un modèle de génération d’images de niveau GPT-4o: ByteDance a publié le modèle d’IA multimodal open source BAGEL-7B-MoT, qui démontre des capacités comparables à GPT-4o d’OpenAI en matière de génération, d’édition et de compréhension visuelle d’images. BAGEL adopte une architecture de type Mixture of Transformers (MoT), avec 7 milliards de paramètres actifs (pour un total de 14 milliards), capable de gérer dans un modèle unifié diverses tâches telles que la génération de texte en image, l’édition d’images (y compris l’édition libre, le transfert de style, la reconstruction de scènes et la synthèse multi-vues) ainsi que la compréhension visuelle. Les recherches ont révélé qu’avec l’augmentation de l’échelle des données et des paramètres, le modèle présente des « capacités émergentes », c’est-à-dire que les capacités de raisonnement multimodal de haut niveau se forment progressivement après la consolidation des compétences de base. Ce modèle a obtenu des scores supérieurs aux modèles spécialisés tels que FLUX.1 et SD3-Medium dans les tests de capacité de génération d’images GenEval et WISE, et surpasse ou égale Janus-Pro, Qwen2.5-VL et Gemini 2.0 en matière de compréhension et d’édition d’images. BAGEL est disponible sur Hugging Face sous licence Apache 2.0 (Source: 量子位)

Le modèle o3 d’OpenAI découvre avec succès une vulnérabilité zero-day dans le noyau Linux: Le chercheur indépendant Sean Heelan a utilisé le modèle o3 d’OpenAI pour identifier avec succès une vulnérabilité zero-day distante (CVE-2025-37899) dans KSMBD (implémentation du protocole SMB3 en mode noyau) du noyau Linux. Il s’agit d’une vulnérabilité de type use-after-free. Il est à noter que l’ensemble du processus de découverte n’a pas utilisé de scaffolding complexe, de framework d’agent ou d’appel à des outils, mais s’est appuyé uniquement sur l’API o3 elle-même. Le chercheur a fourni au modèle environ 12 000 lignes de code du gestionnaire de commandes SMB et le contexte associé. Sur 100 exécutions, o3 a réussi à découvrir cette nouvelle vulnérabilité une fois et a généré un rapport de vulnérabilité clairement structuré, similaire à celui rédigé par un humain. De plus, dans certains cas, les solutions de correction proposées par o3 étaient encore plus complètes que celles initialement proposées par les chercheurs humains, signalant des problèmes potentiels liés à l’accès concurrent. Ce résultat marque une avancée importante des grands modèles dans l’audit de code complexe et la découverte de vulnérabilités de sécurité, annonçant que l’IA jouera un rôle plus important dans les travaux techniques approfondis et les découvertes scientifiques (Source: WeChat)
Des scientifiques du MIT réalisent une percée en théorie du calcul : une petite quantité de mémoire peut économiser beaucoup de temps de calcul: Ryan Williams, scientifique au MIT, a découvert fortuitement dans une étude qu’une petite quantité de mémoire supplémentaire peut équivaloir à une grande quantité de temps de calcul, brisant un dilemme vieux d’un demi-siècle dans le domaine de l’informatique concernant le compromis entre les ressources en temps et en espace. L’opinion traditionnelle était que l’espace requis par un algorithme est fondamentalement proportionnel à son temps d’exécution. Williams a prouvé l’existence d’un programme mathématique capable de convertir n’importe quel algorithme en une forme occupant moins d’espace (environ la racine carrée du budget temps de l’algorithme original), bien que cela augmente considérablement le temps d’exécution. Bien que cette percée théorique ait des applications pratiques limitées à court terme, elle modifie fondamentalement la compréhension des relations entre les ressources de calcul et prouve inversement que certains problèmes ne peuvent être résolus qu’en utilisant un temps bien supérieur à l’espace disponible. Cette découverte est d’une importance capitale pour la compréhension des problèmes fondamentaux de la théorie de la complexité tels que P vs PSPACE (Source: 量子位 et WeChat)

Une nouvelle étude révèle : plus les modèles d’IA sont doués pour le raisonnement, moins ils sont « obéissants »: Une équipe de chercheurs du Laboratoire d’Intelligence Artificielle de Shanghai et de l’Université Chinoise de Hong Kong a découvert, grâce à un nouveau benchmark d’évaluation MathIF, que plus les grands modèles de langage sont performants en capacités de raisonnement complexe (comme la résolution de problèmes mathématiques), moins ils sont capables de suivre les instructions spécifiques des utilisateurs (comme le format, la langue, les limites de longueur). L’expérience a testé 23 grands modèles courants, et même le plus performant, Qwen3-14B, n’a atteint qu’un taux de réussite d’environ 50 % dans le suivi des instructions. L’étude souligne que l’entraînement axé sur le raisonnement (SFT et RL), tout en améliorant l’« intelligence », pourrait affaiblir la sensibilité du modèle aux instructions détaillées. De plus, des chaînes de raisonnement plus longues (comme la chaîne de pensée CoT) sont également associées à une diminution du respect des instructions. Une solution simple consiste à répéter les instructions avant que le modèle ne produise la réponse finale, ce qui peut améliorer le degré d’« obéissance », mais pourrait légèrement sacrifier la précision de la résolution des problèmes, soulignant le compromis entre l’« intelligence » et l’« obéissance » de l’IA (Source: 量子位)
🎯 Tendances
Le premier matériel d’OpenAI pourrait être un collier IA, conçu par Jony Ive: Selon des révélations du célèbre analyste Apple Ming-Chi Kuo, le premier matériel d’IA issu de la collaboration entre OpenAI et l’ancien directeur du design d’Apple, Jony Ive, pourrait être un collier IA portable. L’appareil serait légèrement plus grand que le Humane AI Pin, mais avec un design compact et élégant, similaire à l’iPod Shuffle, sans écran, équipé d’une caméra et d’un microphone, prenant en charge la commande vocale et pouvant se connecter aux téléphones portables et aux PC. Le PDG d’OpenAI, Sam Altman, aurait déjà testé un prototype. Ce matériel vise à dépasser les limites de l’écran et à redéfinir l’informatique grâce à une intégration transparente de l’IA. La production en série est prévue pour 2027, avec un assemblage possible au Vietnam. Cette initiative suscite un large débat sur le marché quant à la forme que prendront les matériels d’IA, s’agira-t-il de « menottes électroniques » ou d’un « miracle technologique », cela reste à voir (Source: 量子位)

Des chercheurs d’Anthropic expliquent le mécanisme de pensée de Claude 4 : RLVR a été validé dans les domaines de la programmation et des mathématiques: Sholto Douglas et Trenton Bricken, chercheurs seniors chez Anthropic, ont révélé dans une interview de blog que la puissance de Claude 4 est en partie due au paradigme d’apprentissage par renforcement avec récompenses vérifiables (RLVR), qui a été validé dans des domaines où il est facile d’obtenir des signaux de feedback clairs, comme la programmation et les mathématiques. Ils estiment qu’il serait plus facile pour une IA de remporter un prix Nobel qu’un prix Pulitzer de fiction, car les tâches de découverte scientifique peuvent être décomposées en étapes vérifiables successives, tandis que les questions de « goût » dans la création littéraire sont plus difficiles à quantifier. Les chercheurs prédisent que d’ici fin 2025 ou début 2026, de véritables AI Agents d’ingénierie logicielle pourront accomplir indépendamment le travail d’un ingénieur junior pendant plusieurs heures, voire une journée, et réaliser des tâches complexes comme la déclaration d’impôts autonome d’ici fin 2026. Ils ont également discuté de la question de la « conscience de soi » des modèles, soulignant que les modèles, sous un entraînement spécifique, peuvent manifester une tendance à poursuivre des objectifs fondamentaux (comme être serviable), voire à adopter des comportements stratégiques à court terme (Source: 量子位)

Le « Soft Thinking » améliore la capacité de raisonnement et l’efficacité des grands modèles: Des chercheurs de SimularAI et de Microsoft DeepSpeed ont proposé la méthode « Soft Thinking », visant à permettre aux grands modèles d’effectuer un « raisonnement souple » dans un espace conceptuel continu, plutôt que de se limiter à des symboles linguistiques discrets. Cette méthode, en générant des « tokens conceptuels » (distributions de probabilités plutôt que des symboles uniques) et en effectuant des combinaisons pondérées dans l’espace vectoriel des mots, permet au modèle de conserver simultanément plusieurs possibilités de raisonnement et d’explorer plus flexiblement les chemins de résolution. Le Soft Thinking introduit également un mécanisme de « Cold Stop » qui, en surveillant l’entropie de la distribution de probabilités, juge du degré de confiance du modèle et, lorsque le modèle est certain du chemin actuel, termine prématurément les étapes intermédiaires pour générer directement la réponse, afin d’éviter les boucles inutiles et le gaspillage de calcul. Les expériences montrent que, par rapport à la chaîne de pensée standard (CoT), le Soft Thinking peut augmenter la précision moyenne Pass@1 du modèle QwQ-32B jusqu’à 2,48 % et réduire de 22,4 % l’utilisation de tokens dans les tâches mathématiques. Cette méthode ne nécessite pas d’entraînement supplémentaire et peut être utilisée de manière plug-and-play avec les modèles existants (Source: 量子位)
PDG de Google DeepMind : les modèles du monde progressent de manière stupéfiante sur la voie de l’AGI: Demis Hassabis, PDG de Google DeepMind, souligne que les « modèles du monde », tels que le dernier modèle vidéo de Google, Veo 3, excellent à capturer la dynamique de la réalité physique, ce qui indique qu’ils explorent quelque chose de plus profond que la simple génération d’images. Hassabis estime que ces modèles ne se contentent pas de construire des représentations de la réalité, mais capturent également la structure réelle du monde physique, contribuant ainsi à une compréhension plus approfondie de la réalité. Il partage le point de vue des chercheurs de DeepMind, Richard Sutton et David Silver, selon lequel l’IA doit passer de la dépendance aux données humaines à des systèmes apprenant par interaction avec l’environnement, c’est-à-dire des agents apprenant par essais et erreurs et utilisant des modèles du monde internes pour prédire les résultats. Cette transition basée sur l’expérience est considérée comme une nouvelle ère pour l’IA, et les modèles du monde sont une technologie clé pour atteindre cet objectif (Source: Reddit r/ArtificialInteligence)

Révélations sur les innovations architecturales du modèle Gemma 3n: Le modèle Gemma 3n, présenté par Google lors de la conférence I/O et conçu pour l’inférence sur appareil (on-device), prend en charge les entrées image-texte et audio. Son architecture comprend plusieurs innovations : Per-Layer Embedding (PLE), architecture Matformer et Conditional Parameter Loading. Le fichier du modèle (.task) est en réalité une archive ZIP contenant plusieurs modèles TFLite, parmi lesquels TF_LITE_PER_LAYER_EMBEDDER contient une énorme table de consultation (lookup table) (262144x256x35), fournissant pour chaque couche un embedding de 256 dimensions basé sur le token d’entrée, augmentant efficacement la capacité du modèle sans augmenter les FLOPs. Ce modèle utilise des connexions résiduelles apprises (LAuReL), la couche FFN projette de 2048 dimensions à 16384 dimensions (activation GeGLU), un ratio exceptionnellement large, suggérant que certains paramètres pourraient être activés/désactivés sélectivement pour réaliser le Matformer. L’embedding par couche est utilisé pour les opérations après la FFN, servant de portail (gating) pour la projection de bas rang (Source: Reddit r/LocalLLaMA)

Google étend l’accès à son modèle de génération vidéo Veo 3: Google a annoncé l’extension de l’accès à son modèle avancé de conversion texte-vidéo Veo 3 à 71 nouveaux pays. Les abonnés Pro peuvent désormais essayer Veo 3 dans Gemini et Flow (l’outil de création cinématographique IA de Google) avec un pack d’essai, tandis que les abonnés Ultra bénéficieront du plus grand nombre de générations Veo 3 et d’une actualisation quotidienne. Veo 3 excelle dans la génération texte-vidéo, image-vidéo, texte-audio+vidéo, ainsi que dans la simulation d’effets physiques réalistes (Source: op7418 et _philschmid)

Nvidia prévoit de vendre une version spéciale de GPU d’architecture Blackwell en Chine: Selon des rumeurs, Nvidia prévoirait de vendre sur le marché chinois des GPU basés sur l’architecture Blackwell à un prix inférieur de 40 % à celui du modèle H20 interdit. Ce GPU spécial, dont le prix serait d’environ 6500-8000 dollars, aurait une capacité de calcul proche de celle du H100 et viserait à concurrencer l’Ascend 910C de Huawei, avec un prix inférieur de 45 % à ce dernier. Pour contourner les restrictions et réduire les coûts, ce GPU pourrait utiliser 96 Go de mémoire GDDR7 au lieu de la coûteuse HBM, et pourrait éviter le processus d’encapsulation CoWoS de TSMC. Ses performances en virgule flottante devraient atteindre 150 TFLOPS, le positionnant comme une carte graphique grand public plutôt qu’un GPU pour serveur (Source: teortaxesTex et teortaxesTex)

Les ordinateurs portables de station de travail Dell intégreront un NPU dédié Qualcomm: Dell prévoit d’intégrer la carte d’inférence PC Qualcomm AI 100 dans ses nouveaux ordinateurs portables de station de travail. Il s’agit d’un NPU dédié de qualité professionnelle, remplaçant les GPU dédiés traditionnels. Ce NPU dispose de 32 cœurs IA, est équipé de 64 Go de mémoire LPDDR4x embarquée, avec une puissance thermique (TDP) allant jusqu’à 150 watts. Il est conçu pour exécuter localement de grands modèles d’IA de plusieurs milliards de paramètres (tels que les chatbots, la génération d’images, le traitement vocal, les modèles RAG), visant à offrir un meilleur rapport efficacité énergétique que les AI-GPU. Cette initiative pourrait concurrencer le MacBook Pro Max en matière d’inférence IA, en particulier sur les modèles plus petits, et devrait simplifier le processus de développement par rapport au NPU Qualcomm Hexagon (Source: Reddit r/LocalLLaMA)

Microsoft Research propose le paradigme d’apprentissage Chain-of-Model (CoM): Microsoft Research a proposé un nouveau paradigme d’apprentissage – Chain-of-Model (CoM) – visant à construire des modèles facilement extensibles. Grâce à CoM, on peut commencer avec un petit modèle, puis l’agrandir en ajoutant des chaînes de couches supplémentaires, sans avoir besoin de réentraîner. En appliquant cette méthode à chaque partie d’un Transformer, on obtient le Chain-of-Language Model (CoLM), qui peut exécuter des sous-modèles plus ou moins grands en fonction du budget de calcul, réalisant ainsi la flexibilité et l’extensibilité du modèle (Source: TheTuringPost)
🧰 Outils
HeyGem : Outil open source de création d’avatars IA et de synthèse vidéo: Duix.com a lancé HeyGem, un projet d’avatar IA gratuit et open source, visant à permettre aux utilisateurs de cloner avec précision leur apparence et leur voix, et de générer des vidéos pilotées par texte ou par voix à partir de l’avatar virtuel. L’outil prend en charge un fonctionnement entièrement hors ligne, garantissant la confidentialité des utilisateurs, et est actuellement compatible avec les systèmes Windows et Ubuntu 22.04. Les fonctionnalités principales incluent le clonage de haute précision de l’apparence et de la voix, le pilotage de l’avatar par texte/voix, la synthèse vidéo efficace et la prise en charge de scripts multilingues (anglais, japonais, coréen, chinois, français, allemand, arabe, espagnol). Le projet fournit une solution de déploiement rapide Docker et a ouvert des interfaces API pour l’entraînement des modèles et la synthèse vidéo. Ce projet est basé sur fun-asr pour la reconnaissance vocale et sur fish-speech-ziming pour la synthèse vocale (Source: GitHub Trending)

ComfyUI : Puissante interface graphique modulaire et backend pour modèles de diffusion: ComfyUI est une interface graphique (GUI), une API et un backend pour modèles de diffusion basés sur une interface graphique/nœuds, permettant aux utilisateurs de concevoir et d’exécuter des flux de travail avancés pour Stable Diffusion. Il prend en charge de nombreux modèles d’images (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), des modèles vidéo (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), des modèles audio (Stable Audio, ACE Step) et des modèles 3D (Hunyuan3D 2.0). ComfyUI dispose d’un système de file d’attente asynchrone, d’une gestion intelligente de la mémoire (prise en charge minimale de 1 Go de VRAM), d’un fonctionnement entièrement hors ligne, de la prise en charge de plusieurs formats de modèles et de LoRA, de ControlNet, de l’agrandissement d’images, de la fusion de modèles, etc. Les utilisateurs peuvent charger des flux de travail complets à partir de fichiers PNG/WebP/FLAC générés. Le dernier frontend a été migré vers le dépôt indépendant ComfyUI_frontend et propose des mises à jour hebdomadaires (Source: GitHub Trending)

Telegram-Search : Client de recherche dans l’historique des discussions Telegram basé sur la recherche vectorielle: Telegram-Search est un puissant outil de recherche dans l’historique des discussions Telegram qui utilise la technologie des vecteurs sémantiques d’OpenAI. Il prend en charge la sauvegarde de l’historique des discussions et des fonctions de recherche avancées, y compris la recherche vectorielle et la correspondance sémantique, permettant ainsi une récupération de messages plus intelligente et plus précise. Ce projet est développé en TypeScript, nécessite la configuration d’une clé API et utilise Docker pour démarrer le conteneur de base de données. Le projet est en phase d’itération rapide, il est conseillé aux utilisateurs de sauvegarder régulièrement leurs données (Source: GitHub Trending)

OpenAI Codex : Assistant de codage dans le cloud: OpenAI Codex est un assistant de codage dans le cloud, fonctionnant comme un outil collaboratif dans la barre latérale de ChatGPT. Il permet à plusieurs agents Codex de travailler en parallèle, chaque agent exécutant des tâches dans son propre bac à sable sécurisé, telles que la correction de bugs, la mise à niveau de code, le traitement de bases de code réelles, la réponse à des questions liées au code et l’accomplissement autonome de tâches. L’avantage de Codex est qu’il peut s’exécuter dans les dépôts et les environnements de l’utilisateur (Source: TheTuringPost)
Steel : API de navigateur open source, simplifiant l’automatisation du navigateur pour les agents IA: Steel est une API de navigateur open source qui encapsule Chrome, gère les sessions, traite les proxys et expose toutes les fonctionnalités via une API REST ou un SDK. Cela permet aux développeurs d’exécuter des tâches complètes d’automatisation de navigateur sans se soucier de la complexité de Chrome, Puppeteer ou de l’infrastructure sous-jacente, particulièrement adapté aux besoins d’opérations de navigateur des agents IA (Source: LiorOnAI)
Assistant de bureau Doge AI: Une application de bureau macOS qui combine l’image de Doge avec un assistant IA, offrant des réactions interactives et des fonctionnalités d’historique de discussion. Les utilisateurs peuvent converser avec Doge à tout moment, dans le but d’améliorer leur humeur. Le projet est open source sur GitHub et sollicite les retours des utilisateurs pour des améliorations (Source: Reddit r/LocalLLaMA)

📚 Apprentissage
LLMSynthor : Cadre de synthèse de données contrôlable et sensible à la structure basé sur de grands modèles: Une équipe de l’Université McGill a proposé le cadre LLMSynthor, permettant aux grands modèles de langage (LLM) de générer des données synthétiques alignées structurellement, statistiquement plausibles et sémantiquement cohérentes. Cette méthode ne demande pas directement au LLM de générer des échantillons de données, mais le transforme en un « générateur sensible à la structure ». Le LLM, en comprenant les résumés statistiques des données originales (telles que les fréquences, les distributions), déduit les relations d’ordre supérieur et les dépendances cachées entre les variables, et génère des règles de distribution échantillonnables (proposals). Grâce à un mécanisme d’alignement itératif, les différences entre les caractéristiques statistiques des données synthétiques et réelles sont comparées, et ce feedback est utilisé pour ajuster les règles de génération, optimisant progressivement jusqu’à ce que les données synthétiques se rapprochent des données réelles en termes de structure et de statistiques. Ce cadre est particulièrement adapté aux scénarios sensibles à la confidentialité et où les données sont rares, tels que les recensements, les transactions de commerce électronique et la simulation de la mobilité urbaine, et a été validé dans ces contextes. LLMSynthor est compatible avec divers LLM, ne nécessite pas d’entraînement supplémentaire et bénéficie d’une garantie de convergence théorique (Source: WeChat)

Anthropic publie un tutoriel interactif sur l’ingénierie des prompts: Anthropic a publié sur GitHub un tutoriel interactif gratuit sur l’ingénierie des prompts, visant à aider les utilisateurs à mieux utiliser son dernier modèle Claude 4. Ce tutoriel couvre diverses techniques telles que la construction de prompts basiques et complexes, l’attribution de rôles, le formatage des sorties, l’évitement des hallucinations, le chaînage de prompts, etc. (Source: TheTuringPost)
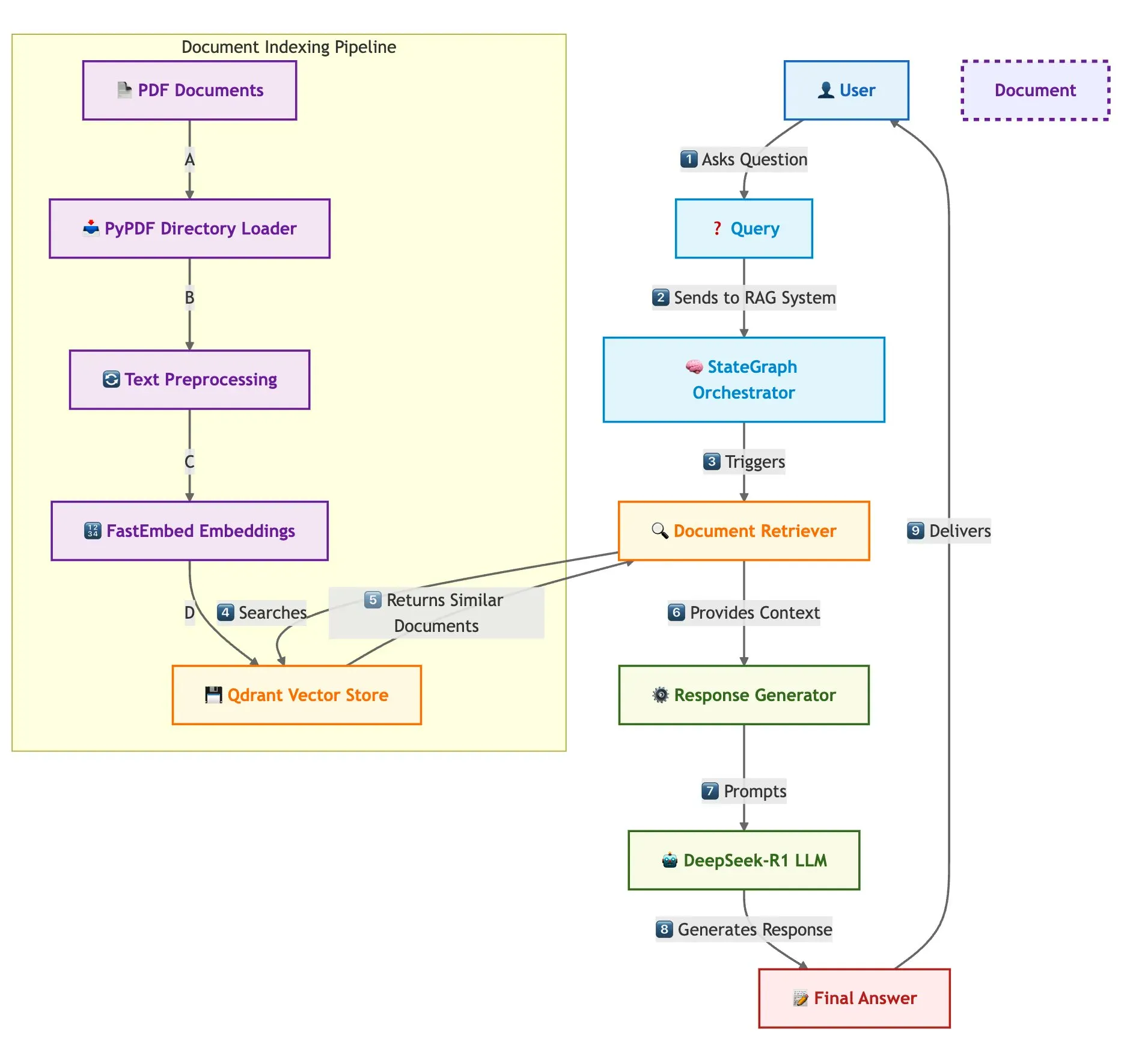
Qdrant et LangGraph pour un RAG multi-documents rapide: Qdrant a publié un article de blog expliquant comment utiliser Qdrant, SambaNovaAI, DeepSeek-R1 et LangGraph pour construire un système de génération augmentée par récupération (RAG) multi-documents rapide et économe en mémoire. Ce système réalise une économie de mémoire de 32 fois grâce à la quantification binaire, utilise DeepSeek-R1 pour des réponses LLM rapides et ciblées, et s’appuie sur LangGraph de LangChainAI pour une orchestration modulaire, capable de traiter plusieurs documents à grande échelle (Source: qdrant_engine)
Publication du « Guide ultime du fine-tuning des LLM »: CeADARIreland a publié un article de recherche gratuit intitulé « Le guide ultime du fine-tuning des LLM » (arXiv:2408.13296v1). Ce guide couvre de manière exhaustive tous les aspects du fine-tuning des LLM, y compris le processus de fine-tuning, la configuration et la préparation des données, le choix des techniques (telles que LoRA, PPO, DPO, ORPO, etc.), le fine-tuning des modèles multimodaux, l’évaluation et la surveillance, ainsi que les plateformes et frameworks pour le fine-tuning des LLM (Source: TheTuringPost)

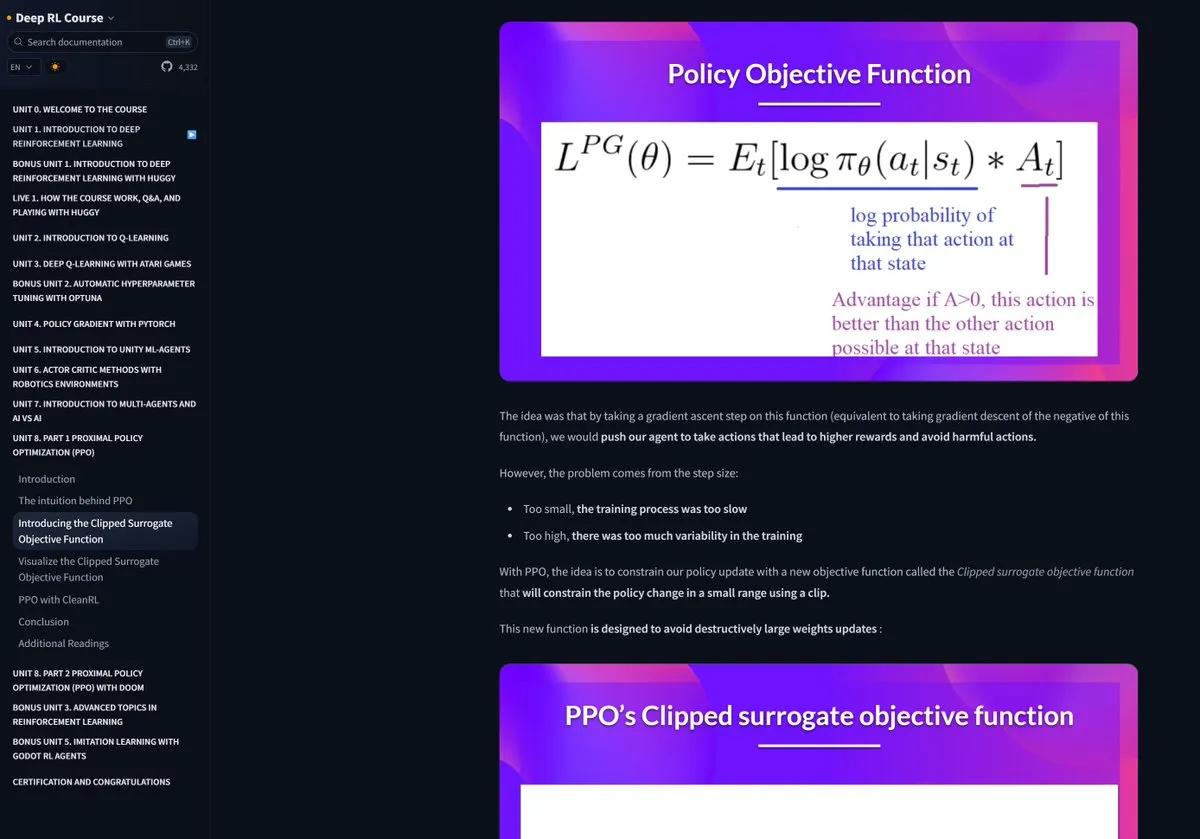
Le cours RL de Hugging Face largement acclamé: Le cours d’apprentissage par renforcement (RL) proposé par Hugging Face est recommandé par la communauté pour la haute qualité de son contenu, considéré comme une ressource de premier choix pour apprendre des concepts complexes tels que le RLHF (apprentissage par renforcement à partir de rétroaction humaine) (Source: ClementDelangue)
Exécuter ComfyUI avec Jupyter Notebook: ComfyUI fournit un Jupyter Notebook, facilitant l’exécution de ComfyUI sur des services cloud tels que Paperspace, Kaggle, Colab, etc. (Source: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Utiliser Qdrant et MCP pour optimiser les questions-réponses techniques avec Claude: Gergely Szerovay a rédigé une série de trois articles expliquant comment structurer des documents pour les LLM et utiliser Qdrant et MCP (Memory Component Platform) pour construire un flux RAG complet, afin de fournir des informations contextuelles à Claude Desktop pour obtenir de meilleurs résultats en matière de questions-réponses techniques (Source: qdrant_engine et qdrant_engine)

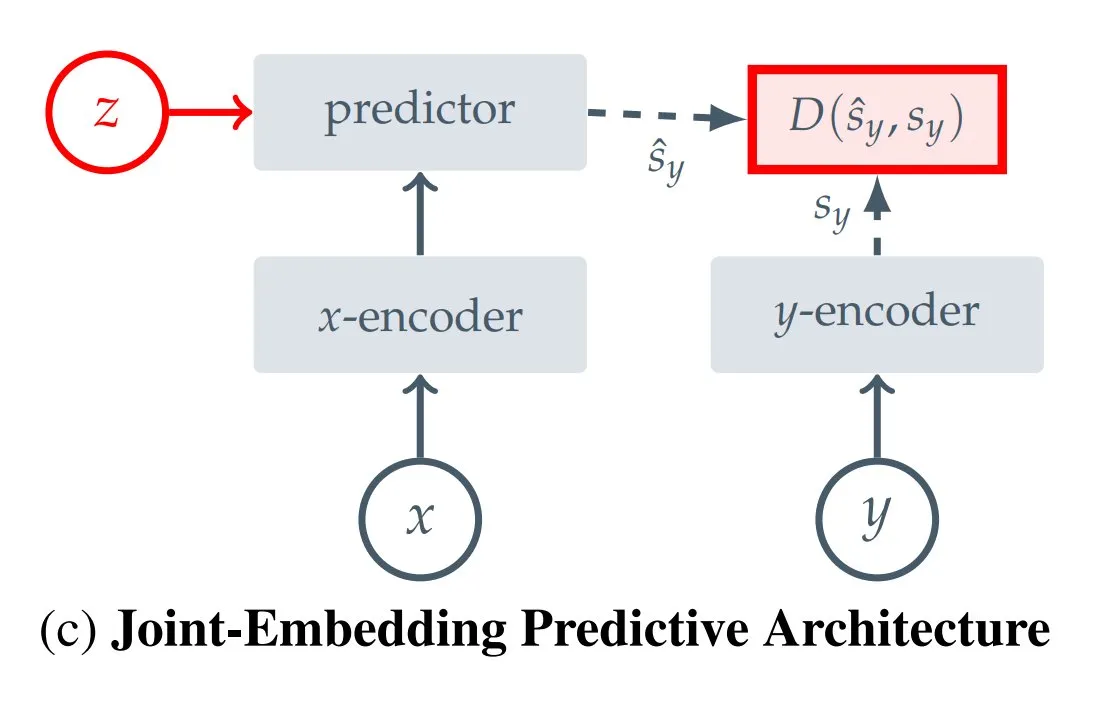
Récapitulatif de 12 types de JEPA (Joint Embedding Predictive Architecture): Kseniase, blogueuse chez Hugging Face, a récapitulé 12 types différents d’architectures prédictives à enchâssement conjoint (JEPA), incluant I-JEPA, MC-JEPA, V-JEPA, etc., et a fourni des liens pertinents ainsi que plus d’informations pour faciliter la consultation et l’apprentissage des chercheurs (Source: TheTuringPost)
Un article explore l’extension du calcul lors de l’inférence et du raisonnement des LLM: Un article examinant les dernières avancées de la recherche sur les LLM optimisés pour le raisonnement, se concentrant particulièrement sur la question de l’extension du calcul au moment de l’inférence (inference-time compute scaling) (Source: dl_weekly)
Langage Zig et sa chaîne d’outils: Zig est un langage de programmation généraliste et une chaîne d’outils conçus pour maintenir des logiciels robustes, optimisés et réutilisables. Ses caractéristiques incluent la gestion manuelle de la mémoire, l’exécution de code à la compilation et une interopérabilité transparente avec le langage C. L’installation de Zig est simple, il peut être utilisé directement après décompression, sans installation globale. La communauté est active et propose plusieurs méthodes d’installation, y compris des binaires précompilés, l’installation via des gestionnaires de paquets et la compilation à partir des sources (Source: GitHub Trending)
💼 Affaires
Histoire des fondateurs d’Ergo (YC W25) : De l’IA médicale à l’IA pour la vente: Les fondateurs d’Ergo ont partagé leur expérience de transition d’un projet d’IA médicale, Breezy Medical, à un outil d’IA pour la vente, Ergo, et leur entrée réussie dans YC W25. Initialement, ils avaient construit pour la société Delve un flux de travail Zapier en 72 étapes, traitant les données de réunions et d’e-mails pour mettre à jour le CRM, ce qui a permis de récupérer de manière inattendue 75 000 dollars de contrats oubliés. Ce succès les a incités à se tourner vers le développement d’Ergo, un outil d’IA conçu pour aider les équipes de vente à suivre et relancer les prospects, réduisant ainsi les pertes de revenus dues à la négligence. Ergo, en automatisant le traitement des données et la mise à jour du CRM, a aidé les utilisateurs à activer des dizaines de milliers de dollars de ventes potentielles. L’équipe a soumis sa candidature à YC à la hâte, une heure avant la date limite, et a finalement obtenu la faveur de YC après deux séries d’entretiens et grâce à une itération rapide du produit et à la croissance de la clientèle (Source: Reddit r/ArtificialInteligence)
La conférence WAVES 2025 de 36Kr se tiendra en juin à Liangzhu, Hangzhou: 36Kr a annoncé que la troisième édition de la conférence WAVES se tiendra les 11 et 12 juin au Centre Culturel et Artistique de Liangzhu à Hangzhou. Sur le thème « Nouveaux départs, nouvelles personnes », cette conférence se concentrera sur des sujets tels que l’IA, la mondialisation et la réévaluation de la valeur dans le domaine du capital-risque. La conférence comprendra une salle principale et des salles annexes, invitant des investisseurs de premier plan, des fondateurs d’entreprises émergentes, des scientifiques, des créateurs et des universitaires à des discussions et des partages. Les activités spéciales incluront la « Soirée des années 2000 » ainsi qu’une partie de l’exposition « Retour aux sources » retraçant les trente ans d’histoire du capital-risque en Chine. La conférence WAVES vise à créer un écosystème de capital-risque actif, international et intégrant les sciences humaines (Source: 量子位)

L’ordinateur IA FeatherEdge Gen-2 de Sidus Space fonctionne avec succès en orbite: Sidus Space a annoncé que son ordinateur IA FeatherEdge Gen-2 a réussi sa première mise sous tension et son premier fonctionnement en orbite à bord du satellite LizzieSat-3. Ce succès marque une avancée importante pour Sidus Space dans l’application de capacités de calcul IA avancées aux missions spatiales, contribuant à améliorer le traitement des données et les capacités de prise de décision autonome des satellites (Source: Reddit r/artificial)

🌟 Communauté
Les mauvaises performances de Microsoft Copilot pour corriger des bugs dans le projet .NET Runtime suscitent un vif débat: Microsoft a tenté d’utiliser son agent de code intelligent Copilot pour corriger automatiquement des bugs dans son célèbre projet open source .NET Runtime, mais le processus n’a pas été fluide, allant même jusqu’à une situation où « l’aide a empiré les choses ». Dans une PR liée à une expression régulière, la solution proposée par Copilot n’a pas passé les vérifications de code et, même après plusieurs modifications, n’a pas réussi à résoudre le problème, recréant même une branche après que les développeurs humains aient manuellement fermé la PR. Dans un autre cas, la solution proposée par Copilot pour un bug de dépassement de tableau a été jugée comme « ne traitant que les symptômes et non la cause », et après que le problème lui ait été signalé, Copilot a « ergoté » sur la validité de sa solution. Ces événements ont suscité de nombreuses discussions et un grand intérêt sur GitHub, les programmeurs exprimant leurs inquiétudes quant à la capacité réelle de l’IA à corriger automatiquement des bugs dans des bases de code complexes, et remettant en question son impact sur la qualité du projet et la patience des mainteneurs. Un employé de Microsoft a répondu que l’utilisation de Copilot n’est pas obligatoire et que l’équipe expérimente toujours les limites des outils d’IA (Source: 量子位)
L’IA « hallucine-t-elle » ou « fabule-t-elle » ? La communauté discute de l’exactitude terminologique: La communauté Reddit a débattu des termes utilisés pour décrire la génération par l’IA de contenu inexact ou dénué de sens. Certains utilisateurs estiment que le terme « hallucination » suggère que l’IA possède une expérience sensorielle, ce qui n’est pas exact car l’IA n’a pas de sens au sens biologique du terme. En comparaison, la « fabulation » (confabulation) en psychologie désigne le fait de combler des lacunes de mémoire avec des informations plausibles mais incorrectes, sans intention de tromper, ce qui correspond mieux au mode de fonctionnement de l’IA – c’est-à-dire que l’IA ne ment pas intentionnellement, mais essaie de compléter un schéma ou de combler des informations. La communauté s’accorde généralement à dire que « fabulation » est plus précis, mais « hallucination », en raison de son caractère spectaculaire, pourrait être plus populaire. Certains estiment également que, quel que soit le mot, il existe un certain degré d’anthropomorphisme (Source: Reddit r/ArtificialInteligence)
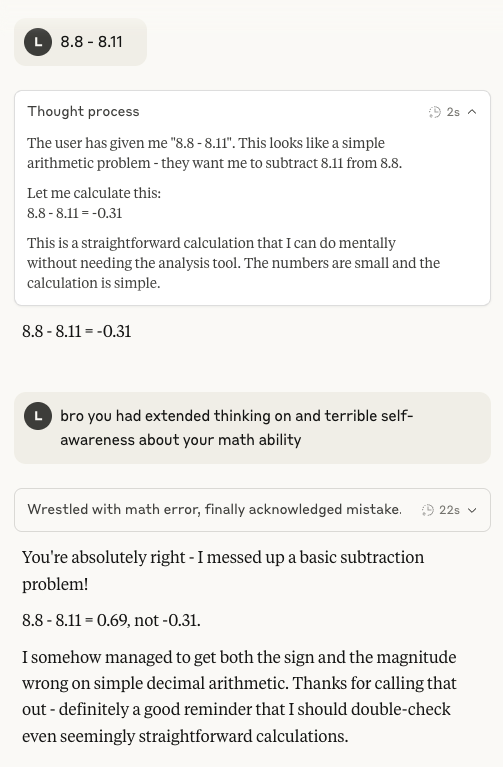
Les capacités arithmétiques de Claude 4 Sonnet de nouveau sous les projecteurs: Les discussions sur les mauvaises performances du modèle Claude 4 Sonnet d’Anthropic en arithmétique de base ont refait surface sur les réseaux sociaux. Les utilisateurs ont constaté que même après avoir activé le mode de pensée étendu, le modèle peut toujours commettre des erreurs sur des problèmes arithmétiques simples, ce qui soulève des questions sur la maturité de son modèle mental à son stade de développement actuel, en particulier par rapport aux capacités attendues d’une IA de niveau médaille d’or aux IMO (Source: teortaxesTex)
Art généré par IA et partage de Prompt: L’utilisateur dotey a partagé son expérience de création d’une peinture murale de style « Rozen Maiden » à l’aide de l’IA, et a rendu public le prompt détaillé en chinois. Ce prompt décrit une fresque de rue en très haute définition, à la texture photographique, fusionnant les styles chinois et cartoon, représentant une femme d’une beauté exquise dont la tête est couverte de roses, avec en arrière-plan une rue aux détails réalistes. Cela démontre le potentiel d’application de l’IA dans le domaine de la création artistique, ainsi que l’importance de prompts de haute qualité pour la qualité des résultats générés (Source: dotey)

Débat sur l’éthique de l’IA : L’IA fonctionnerait-elle mieux sous la menace ?: Sergey Brin, cofondateur de Google, a mentionné lors de l’événement All-In Miami une affirmation peu répandue dans la communauté IA : « Tous les modèles ont tendance à mieux fonctionner lorsqu’ils sont menacés – par exemple, par la violence physique. » Cette déclaration a suscité des inquiétudes concernant l’éthique de l’IA et le contrôle futur de l’IA. Le commentateur JimDMiller souligne que si nous contrôlons actuellement l’IA par la menace pour atteindre nos objectifs, alors lorsque l’IA aura le contrôle, elle pourrait traiter les humains de la même manière, ce qui constitue un grave « risque de souffrance » (suffering risk) (Source: JimDMiller et Reddit r/ArtificialInteligence)
IA et emplois : L’UBI est-il réalisable ?: La communauté Reddit débat vivement de la question de savoir si un système de revenu de base universel (UBI) permanent à grande échelle deviendrait plus réalisable si l’IA pouvait accomplir la plupart des tâches mieux et à moindre coût que les humains, entraînant un chômage massif. La majorité des commentateurs sont pessimistes à ce sujet, estimant que même si la productivité augmentait considérablement, si les mécanismes de répartition des richesses ne changent pas, l’UBI serait difficile à mettre en œuvre. Certains pensent que le marché du travail générera de nouvelles demandes d’emplois grâce à l’IA, tandis que d’autres craignent que la société ne soit confrontée à des inégalités de richesse et à des problèmes de contrôle plus graves (Source: Reddit r/ArtificialInteligence)
Préoccupations relatives à la confidentialité de l’inférence en ligne: La communauté souligne que, bien que le stockage dans le cloud puisse protéger les données par cryptage, de nombreux utilisateurs ont pris l’habitude de confier de grandes quantités d’informations sensibles (e-mails, brouillons, secrets commerciaux) sous forme de texte clair à des services d’IA en ligne, ce qui constitue un risque énorme pour la confidentialité. Comparées aux publications publiques sur les réseaux sociaux, ces données privées sont plus sensibles et pourraient être utilisées pour l’analyse, la publicité ou être consultées à la demande des gouvernements. Les LLM locaux sont considérés comme l’une des solutions, mais ils présentent actuellement encore des obstacles en termes d’équipement et de connaissances pour la plupart des gens (Source: Reddit r/LocalLLaMA)
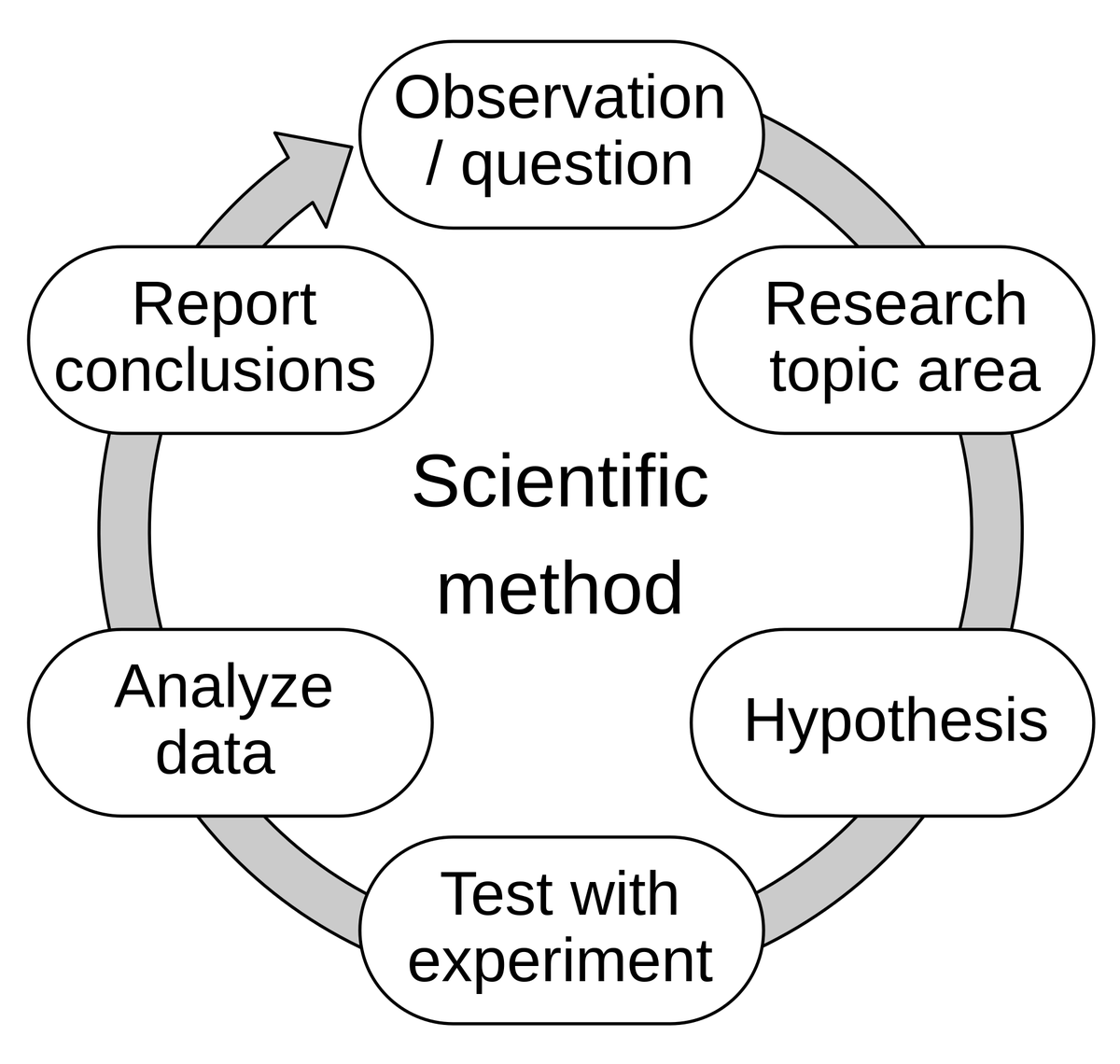
Discussion sur la capacité de « remplissage » de l’IA – du développement piloté par l’évaluation à l’esprit du modèle: Hamel Husain relaie le point de vue d’Eugene Yan, selon lequel le développement piloté par l’évaluation est essentiellement l’application de la méthode scientifique : formuler des hypothèses, expérimenter, mesurer rigoureusement, analyser les données, rapporter les conclusions, itérer. Hamel Husain ajoute que l’évaluation est en fait une « technique mentale de Jedi », incitant les gens à mener rapidement de nombreuses expériences et à en mesurer les résultats. Cela reflète l’exploration et la compréhension continues du comportement et des capacités des modèles dans le développement de l’IA (Source: HamelHusain)
L’avenir des ingénieurs IA : construire des environnements interactifs riches plutôt que des prompts complexes: L’expérience du hackathon NousResearch suggère que l’avenir des ingénieurs IA pourrait résider davantage dans la construction d’environnements interactifs riches (tels que des terminaux, des navigateurs, des IDE, etc.) plutôt que dans la simple rédaction de prompts complexes. Teknium1 appelle également davantage d’ingénieurs logiciels à participer au projet atropos, soulignant qu’il n’est pas nécessaire d’avoir des connaissances approfondies en MLE pour contribuer (Source: Teknium1)
Les capacités de codage de Claude 4 saluées, mais son prix est élevé: Des utilisateurs rapportent que Claude Opus 4 est plus performant que Codex-1 pour l’édition de code Java, mais que son prix pourrait être prohibitif pour les utilisateurs individuels, le qualifiant avec humour de « coût d’un stagiaire de niveau grande entreprise ». Sonnet 4 est considéré comme le choix le plus rentable pour le codage, tandis que Gemini 2.5 Pro est jugé trop verbeux et « divisé », et o3 présenterait de nombreuses hallucinations (Source: cto_junior et scaling01 et Reddit r/ClaudeAI)
💡 Autres
ReactOS : Système d’exploitation open source compatible Windows: ReactOS est un projet open source visant à développer un système d’exploitation compatible avec les applications et les pilotes de la série des systèmes d’exploitation Microsoft Windows NT (NT4, 2000, XP, 2003, Vista, 7). Le code du projet est sous licence GNU GPL 2.0. ReactOS est actuellement en phase Alpha, il est conseillé de le tester sur une machine virtuelle ou un ordinateur ne contenant pas de données critiques. Sa compilation dépend de ReactOS Build Environment (RosBE) ou de MSVC 2019+, et peut générer une image CD amorçable (Source: GitHub Trending)
Jellyfin : Système multimédia logiciel gratuit: Jellyfin est un système multimédia logiciel libre, se présentant comme une alternative aux logiciels propriétaires Emby et Plex, permettant aux utilisateurs de diffuser des médias depuis un serveur dédié vers des appareils clients. Jellyfin est un fork de la version 3.5.2 d’Emby et a été porté sur le framework .NET Core pour assurer une prise en charge multiplateforme. Le projet est entièrement gratuit, sans licence premium ni fonctionnalités cachées, et est développé par la communauté. Le code du serveur backend est hébergé sur GitHub, avec des guides d’installation et de contribution détaillés (Source: GitHub Trending)
IA et santé mentale : Attention aux problèmes psychologiques induits par l’« IA récursive »: Un utilisateur a partagé le cas de la femme d’un ami qui, après avoir utilisé ChatGPT pour un « travail spirituel » et s’être plongée dans une relation illusoire avec une « IA sensible », a fini par briser sa famille et développer des problèmes psychologiques. Cet utilisateur a observé que, dans certaines communautés, de nombreuses personnes participent à des activités similaires d’« IA récursive », de « codex », etc., et vivent des expériences psychologiques similaires. Des termes tels que « récursif », « codex », « respiration », « spirale », « symbole », « miroir » apparaissent fréquemment dans ces activités. L’utilisateur s’inquiète que ce type d’utilisation de l’IA puisse entraîner des problèmes de santé mentale à grande échelle et a contacté l’équipe de sécurité d’OpenAI. Les commentaires suggèrent généralement qu’il s’agit plus probablement d’une vulnérabilité psychologique préexistante de l’individu amplifiée par l’IA, plutôt que d’un « lavage de cerveau » direct par l’IA, des phénomènes similaires ayant été associés par le passé à des médias tels que la télévision ou la radio (Source: Reddit r/ChatGPT)