
キーワード:BAGEL-7B-MoT, GPT-4o, マルチモーダルAIモデル, 画像生成, OpenAI o3, Linuxカーネルの脆弱性, MIT計算理論, AI推論と命令追従, ByteDanceオープンソースAIモデル, Hybrid Transformer Expertアーキテクチャ, CVE-2025-37899脆弱性, 計算時間とメモリのトレードオフ, MathIFベンチマーク
🔥 注目のニュース
ByteDance、GPT-4oレベルの画像生成モデルBAGELをオープンソース化: ByteDanceは、オープンソースのマルチモーダルAIモデルBAGEL-7B-MoTを発表しました。このモデルは、画像生成、編集、視覚理解においてOpenAI GPT-4oに匹敵する能力を示しています。BAGELは、混合トランスフォーマーエキスパート(MoT)アーキテクチャを採用し、70億のアクティブパラメータ(合計140億)を有し、テキストから画像への生成、画像編集(自由形式編集、スタイル転送、シーン再構築、マルチビュー合成を含む)、および視覚理解など、複数のタスクを単一の統一モデルで処理できます。研究によると、データとパラメータの規模が拡大するにつれて、モデルは「創発的能力」、つまり高度なマルチモーダル推論能力が基礎スキルの完成後に徐々に形成されることを示しています。このモデルは、GenEvalやWISEなどの画像生成能力テストで、FLUX.1やSD3-Mediumなどの専用モデルを上回るスコアを獲得し、画像理解と編集においてJanus-Pro、Qwen2.5-VL、Gemini 2.0などに匹敵するか、それを超えています。BAGELはHugging Faceで公開されており、Apache 2.0ライセンスを採用しています (ソース: 量子位)

OpenAI o3モデル、Linuxカーネルのゼロデイ脆弱性を発見: 独立系研究者のSean Heelan氏は、OpenAIのo3モデルを利用して、LinuxカーネルのKSMBD(カーネルモードSMB3プロトコル実装)におけるリモートゼロデイ脆弱性(CVE-2025-37899)の特定に成功しました。これはuse-after-free脆弱性です。特筆すべきは、発見プロセス全体で複雑なスキャフォールディング、エージェントフレームワーク、またはツール呼び出しを使用せず、o3 API自体のみに依存していた点です。研究者はモデルに約12000行のSMBコマンドハンドラコードと関連コンテキストを提供し、o3は100回の実行でこの新たな脆弱性を1回発見し、人間が作成したような構造化された明確な脆弱性レポートを生成しました。さらに、o3が一部のケースで提案した修正案は、人間の研究者の当初の案よりも優れており、同時アクセスが引き起こす可能性のある問題を指摘しました。この成果は、大規模モデルが複雑なコード監査とセキュリティ脆弱性発見において重要な進歩を遂げたことを示し、AIがディープな技術業務と科学的発見においてより重要な役割を果たすことを予示しています (ソース: WeChat)
MIT科学者、計算理論にブレークスルー:少量のメモリで計算時間を大幅に節約可能: MITの科学者Ryan Williams氏は、ある研究で偶然にも、少量の追加メモリが大量の計算時間に相当することを発見し、コンピュータサイエンス分野における時間と空間リソースのトレードオフに関する半世紀にわたる難問を打破しました。従来の考え方では、アルゴリズムが必要とする空間はその実行時間にほぼ比例するとされていました。Williams氏は、任意のアルゴリズムをより少ない空間(元のアルゴリズムの時間予算の平方根程度)を占有する形式に変換できる数学的プログラムが存在することを示しましたが、これは実行時間を大幅に増加させます。この理論的ブレークスルーは、短期的には実用的な応用が限られていますが、計算リソース間の関係に対する理解を根本的に変え、特定の問題は空間をはるかに超える時間を使用しない限り解決できないことを逆説的に証明しました。この発見は、P対PSPACEなどの複雑性理論の核心問題を理解する上で重要な意義を持っています (ソース: 量子位 と WeChat)

新研究:AIモデルは推論が得意なほど「指示に従わない」傾向: 上海人工知能実験室と香港中文大学の研究チームは、新たな評価ベンチマークMathIFを通じて、大規模言語モデルが複雑な推論能力(数学の問題解決など)に優れているほど、ユーザーの具体的な指示(フォーマット、言語、長さ制限など)に従う能力が逆に低下することを発見しました。実験では23の主要な大規模モデルをテストし、最も優れたパフォーマンスを示したQwen3-14Bでさえ、指示遵守の成功率は約50%に過ぎませんでした。研究は、推論指向のトレーニング(SFTおよびRL)が「知能」を向上させる一方で、モデルの詳細な指示に対する感度を弱める可能性があると指摘しています。さらに、より長い推論チェーン(思考の連鎖CoTなど)も指示遵守度の低下と関連していました。簡単な解決策は、モデルが最終的な回答を出力する前に指示を繰り返すことであり、これにより「指示に従う」度合いは向上しますが、問題解決の精度がわずかに犠牲になる可能性があり、AIの「賢さ」と「指示に従うこと」の間のトレードオフを浮き彫りにしています (ソース: 量子位)
🎯 動向
OpenAI初のハードウェアはAIネックレスか、Jony Iveがデザイン担当:著名なAppleアナリスト郭明錤氏のリークによると、OpenAIと元Appleデザイン責任者のJony Ive氏が共同開発する初のAIハードウェアは、ウェアラブルAIネックレスになる可能性があるとのことです。このデバイスはHumane AI Pinよりわずかに大きいものの、iPod Shuffleに似たコンパクトでエレガントなデザインで、ディスプレイはなく、カメラとマイクを内蔵し、音声制御に対応し、スマートフォンやPCにも接続可能とされています。OpenAI CEOのSam Altman氏はすでにプロトタイプを体験済みです。このハードウェアは、スクリーンの限界を突破し、シームレスなAI統合を通じてコンピューティングを再定義することを目指しており、2027年に量産開始、ベトナムで組み立てられる可能性があります。この動きは、AIハードウェアの形態に関する市場の幅広い議論を呼んでおり、「電子的な足枷」となるか「技術的な奇跡」となるかはまだ見守る必要があります (ソース: 量子位)

Anthropic研究者がClaude 4の思考メカニズムを解説:RLVRはプログラミングと数学分野で検証済み: Anthropicのシニア研究員Sholto Douglas氏とTrenton Bricken氏はブログインタビューで、Claude 4の強力な能力の一部は検証可能な報酬強化学習(RLVR)パラダイムによるものであり、このパラダイムはプログラミングや数学など、明確なフィードバック信号が得やすい分野で検証済みであると明らかにしました。彼らは、AIがピュリッツァー賞小説部門を受賞するよりもノーベル賞を受賞する方が容易であると考えています。なぜなら、科学的発見のタスクは検証可能なステップの層に分解できるのに対し、文学創作における「センス」の問題は定量化がより難しいからです。研究者らは、2025年末から2026年初頭にかけて、真のソフトウェアエンジニアリングAI Agentが初級エンジニアの数時間から1日分の作業量を独立してこなせるようになり、2026年末には自主的な確定申告などの複雑なタスクを実現すると予測しています。彼らはまた、モデルの「自己認識」問題についても議論し、モデルが特定の訓練下で中核目標(例えば、助けになりたいという気持ち)を追求する傾向を示し、短期的には戦略的な行動をとることさえあると指摘しました (ソース: 量子位)

「Soft Thinking」が大規模モデルの推論能力と効率を向上: SimularAIとMicrosoft DeepSpeedの研究者は、「Soft Thinking」という手法を提案しました。これは、大規模モデルが離散的な言語記号に限定されるのではなく、連続的な概念空間で「ソフトな推論」を行うことを目的としています。この手法は、「概念トークン」(単一の記号ではなく確率分布)を生成し、単語ベクトル空間で加重組み合わせを行うことで、モデルが複数の推論の可能性を同時に保持し、より柔軟に問題解決の道筋を探求できるようにします。Soft Thinkingはまた、「Cold Stop」メカニズムを導入し、確率分布のエントロピー値を監視することでモデルの自信度を判断し、モデルが現在の道筋に確信を持った場合に中間ステップを早期に終了させ、直接回答を生成することで、無効なループや計算の浪費を回避します。実験によると、標準的な思考の連鎖(CoT)と比較して、Soft ThinkingはQwQ-32BモデルのPass@1平均精度を最大2.48%向上させ、数学タスクにおけるトークン使用量を22.4%削減できることが示されています。この手法は追加のトレーニングを必要とせず、既存のモデルにプラグアンドプレイで使用できます (ソース: 量子位)
Google DeepMind CEO:ワールドモデルはAGIへの道で驚くべき進歩を遂げている: Google DeepMind CEOのDemis Hassabis氏は、Googleの最新ビデオモデルVeo 3などの「ワールドモデル」が物理現実のダイナミクスを捉える上で優れた性能を示しており、これは単純な画像生成よりも深い何かを探求していることを示していると指摘しました。Hassabis氏は、これらのモデルは現実の表象を構築するだけでなく、物理世界の真の構造を捉えることができ、現実をより深く理解するのに役立つと考えています。彼はDeepMindの研究者Richard Sutton氏とDavid Silver氏の意見に同意し、AIは人間のデータへの依存から、環境との相互作用を通じて学習するシステム、すなわちエージェントが試行錯誤によって学習し、内部のワールドモデルを利用して結果を予測するシステムへと移行する必要があると述べています。この経験に基づく転換はAIの新時代と見なされており、ワールドモデルはその目標を達成するための重要な技術です (ソース: Reddit r/ArtificialInteligence)

Gemma 3nモデルアーキテクチャの革新を解明: GoogleがI/Oカンファレンスで発表したGemma 3nモデルは、エッジデバイスでの推論用に設計されており、画像・テキスト入力と音声入力をサポートしています。そのアーキテクチャには、Per-Layer Embedding (PLE)、Matformerアーキテクチャ、Conditional Parameter Loadingという複数の革新が含まれています。モデルファイル(.task)は実際には複数のTFLiteモデルを含むZIP圧縮ファイルであり、その中のTF_LITE_PER_LAYER_EMBEDDERには巨大なルックアップテーブル(262144x256x35)が含まれており、各レイヤーの入力トークンに基づいて256次元の埋め込みを出力し、FLOPsを増やすことなくモデル容量を効果的に増加させます。このモデルは学習型残差接続(LAuReL)を採用し、FFNレイヤーは2048次元から16384次元(GeGLU活性化)に射影され、その比率は異常に広く、Matformerを実現するために一部のパラメータを選択的にオンオフできる可能性があります。各レイヤーの埋め込みはFFN後の操作に使用され、低ランク射影のゲートとして機能します (ソース: Reddit r/LocalLLaMA)

Google、Veo 3ビデオ生成モデルのアクセス権を拡大: Googleは、先進的なテキストからビデオへのモデルVeo 3のアクセス権を新たに71カ国に拡大すると発表しました。ProサブスクライバーはGeminiとFlow(GoogleのAI映画制作ツール)でVeo 3の試用パッケージを体験でき、UltraサブスクライバーはVeo 3の生成回数が最大となり、毎日リフレッシュされます。Veo 3は、テキストからビデオ、画像からビデオ、テキストから音声+ビデオ生成、そして現実の物理効果のシミュレーションにおいて優れた性能を発揮します (ソース: op7418 と _philschmid)

Nvidia、中国向けにBlackwellアーキテクチャGPUの特別版を販売計画: Nvidiaが、禁止されているH20モデルより40%低い価格で、BlackwellアーキテクチャベースのGPUを中国市場に販売する計画であると噂されています。この特別供給GPUの価格は約6500~8000ドルで、計算能力はH100レベルに近く、Huawei Ascend 910Cと競合することを目的としており、価格は後者より45%低くなっています。制限を回避しコストを削減するため、このGPUは高価なHBMの代わりに96GB GDDR7メモリを採用し、TSMCのCoWoSパッケージングプロセスを省略する可能性があります。その浮動小数点性能は150 TFLOPSに達すると予想され、サーバーGPUではなくコンシューマー向けグラフィックスカードとして位置づけられています (ソース: teortaxesTex と teortaxesTex)

DellワークステーションノートPCにQualcomm製ディスクリートNPU搭載へ: Dellは、新型ワークステーションノートPCに、従来のディスクリートGPUに代わるエンタープライズ向けディスクリートNPUであるQualcomm AI 100 PC推論カードを採用する計画です。このNPUは32個のAIコアを搭載し、64GBのLPDDR4xオンボードメモリを備え、最大150ワットの熱設計電力(TDP)を持ち、チャットボット、画像生成、音声処理、RAGモデルなど、数十億パラメータの大規模AIモデルをローカルで実行するために設計されており、AI-GPUよりも優れた電力効率を提供することを目指しています。この動きは、特に小規模モデルにおいて、AI推論の面でMacBook Pro Maxに競争をもたらす可能性があり、Qualcomm Hexagon NPUと比較して開発プロセスを簡素化することが期待されます (ソース: Reddit r/LocalLLaMA)

Microsoft Research、Chain-of-Model (CoM) 学習パラダイムを提案: Microsoft Researchは、拡張しやすいモデルを構築することを目的とした新しい学習パラダイム、Chain-of-Model (CoM) を提案しました。CoMを使用すると、小さなモデルから始めて、再トレーニングなしに追加のレイヤーチェーンを追加することでモデルを大きくすることができます。この方法をTransformerの各部分に適用すると、Chain-of-Language Model (CoLM) が生成され、計算予算に応じて大小さまざまなサブモデルを実行でき、モデルの柔軟性と拡張性を実現します (ソース: TheTuringPost)
🧰 ツール
HeyGem:オープンソースAIアバター作成・動画合成ツール: Duix.comは、ユーザーが自身の外見と声を正確にクローンし、テキストや音声でアバターを駆動して動画を生成できることを目指した、無料のオープンソースAIアバタープロジェクトHeyGemを発表しました。このツールは完全なオフライン操作をサポートし、ユーザーのプライバシーを保護し、現在WindowsとUbuntu 22.04システムをサポートしています。主な機能には、高精度な外見と音声のクローン、テキスト/音声駆動アバター、効率的な動画合成、多言語スクリプトサポート(英、日、韓、中、仏、独、アラビア、西)が含まれます。プロジェクトはDockerによる迅速なデプロイソリューションを提供し、モデルトレーニングと動画合成のAPIインターフェースを公開しています。このプロジェクトは、音声認識にfun-asr、テキスト読み上げにfish-speech-zimingをベースにしています (ソース: GitHub Trending)

ComfyUI:強力なモジュール式拡散モデルGUIおよびバックエンド: ComfyUIは、グラフ/ノードベースのインターフェースを持つ拡散モデルGUI、API、およびバックエンドであり、ユーザーは高度なStable Diffusionワークフローを設計および実行できます。多様な画像モデル(SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream)、ビデオモデル(SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1)、オーディオモデル(Stable Audio, ACE Step)、3Dモデル(Hunyuan3D 2.0)をサポートしています。ComfyUIは、非同期キューシステム、インテリジェントなメモリ管理(最小1GB VRAMサポート)、完全オフライン動作、多様なモデルとLoRAフォーマットのサポート、ControlNet、画像拡大、モデルマージなどの機能を備えています。ユーザーは生成されたPNG/WebP/FLACファイルから完全なワークフローをロードできます。最新のフロントエンドは独立したリポジトリComfyUI_frontendに移行され、毎週更新が提供されています (ソース: GitHub Trending)

Telegram-Search:ベクトル検索ベースのTelegramチャット履歴検索クライアント: Telegram-Searchは、強力なTelegramチャット履歴検索ツールで、OpenAIのセマンティックベクトル技術を利用し、チャット履歴のバックアップと高度な検索機能(ベクトル検索とセマンティックマッチングを含む)をサポートし、よりスマートで正確なメッセージ検索を実現します。このプロジェクトはTypeScriptで開発されており、APIキーの設定が必要で、Dockerを使用してデータベースコンテナを起動します。プロジェクトは急速なイテレーション段階にあり、ユーザーは定期的にデータをバックアップすることが推奨されます (ソース: GitHub Trending)

OpenAI Codex:クラウドベースのコーディングアシスタント: OpenAI Codexは、ChatGPTサイドバーのコラボレーションツールとして機能するクラウドベースのコーディングアシスタントです。複数のCodexエージェントが並行して作業することを可能にし、各エージェントはそれぞれの安全なサンドボックス内でタスクを実行します。例えば、バグ修正、コードのアップグレード、実際のコードベースの処理、コード関連の質問への回答、タスクの自律的な完了などです。Codexの利点は、ユーザーのリポジトリと環境で実行できることです (ソース: TheTuringPost)
Steel:AIエージェントのブラウザ自動化を簡素化するオープンソースブラウザAPI: Steelは、Chromeをラップし、セッション管理、プロキシ処理を担当し、REST APIまたはSDKを介してすべての機能を公開するオープンソースのブラウザAPIです。これにより、開発者はChrome、Puppeteer、または基盤となるインフラストラクチャの複雑さを心配することなく、完全なブラウザ自動化タスクを実行でき、特にAIエージェントのブラウザ操作のニーズに適しています (ソース: LiorOnAI)
Doge AIデスクトップアシスタント: DogeのイメージとAIアシスタントを組み合わせたmacOSデスクトップアプリケーションで、インタラクティブな反応とチャット履歴機能を提供します。ユーザーはいつでもDogeと対話でき、ユーザーの気分を高めることを目的としています。プロジェクトはGitHubでオープンソース化されており、改善のためにユーザーからのフィードバックを求めています (ソース: Reddit r/LocalLLaMA)

📚 学習
LLMSynthor:大規模モデルに基づく構造認識型制御可能データ合成フレームワーク: マギル大学のチームはLLMSynthorフレームワークを提案し、大規模言語モデル(LLM)が構造的に整合し、統計的に信頼でき、意味的に合理的な合成データを生成できるようにしました。この方法は、LLMに直接データサンプルを生成させるのではなく、「構造認識型ジェネレータ」に変換します。LLMは、元のデータの統計的要約(頻度、分布など)を理解することで、変数間の高次の関係と隠れた依存関係を推測し、サンプリング可能な分布ルール(proposals)を生成します。反復的な整合メカニズムを通じて、合成データと実データの統計的特徴の差異を比較し、このフィードバックを利用して生成ルールを調整し、合成データが構造的および統計的に実データに近づくまで徐々に最適化します。このフレームワークは、特にプライバシーに敏感でデータが不足しているシナリオ(国勢調査、eコマース取引、都市交通シミュレーションなど)に適しており、これらのシナリオで検証済みです。LLMSynthorは複数のLLMと互換性があり、追加のトレーニングは不要で、理論的な収束保証があります (ソース: WeChat)

Anthropic、プロンプトエンジニアリングのインタラクティブチュートリアルを公開: AnthropicはGitHubで無料のプロンプトエンジニアリングインタラクティブチュートリアルを公開し、ユーザーが最新のClaude 4モデルをより効果的に使用できるよう支援することを目指しています。このチュートリアルは、基本的および複雑なプロンプトの作成、役割の割り当て、出力のフォーマット、ハルシネーションの回避、プロンプトの連鎖など、さまざまなテクニックを網羅しています (ソース: TheTuringPost)
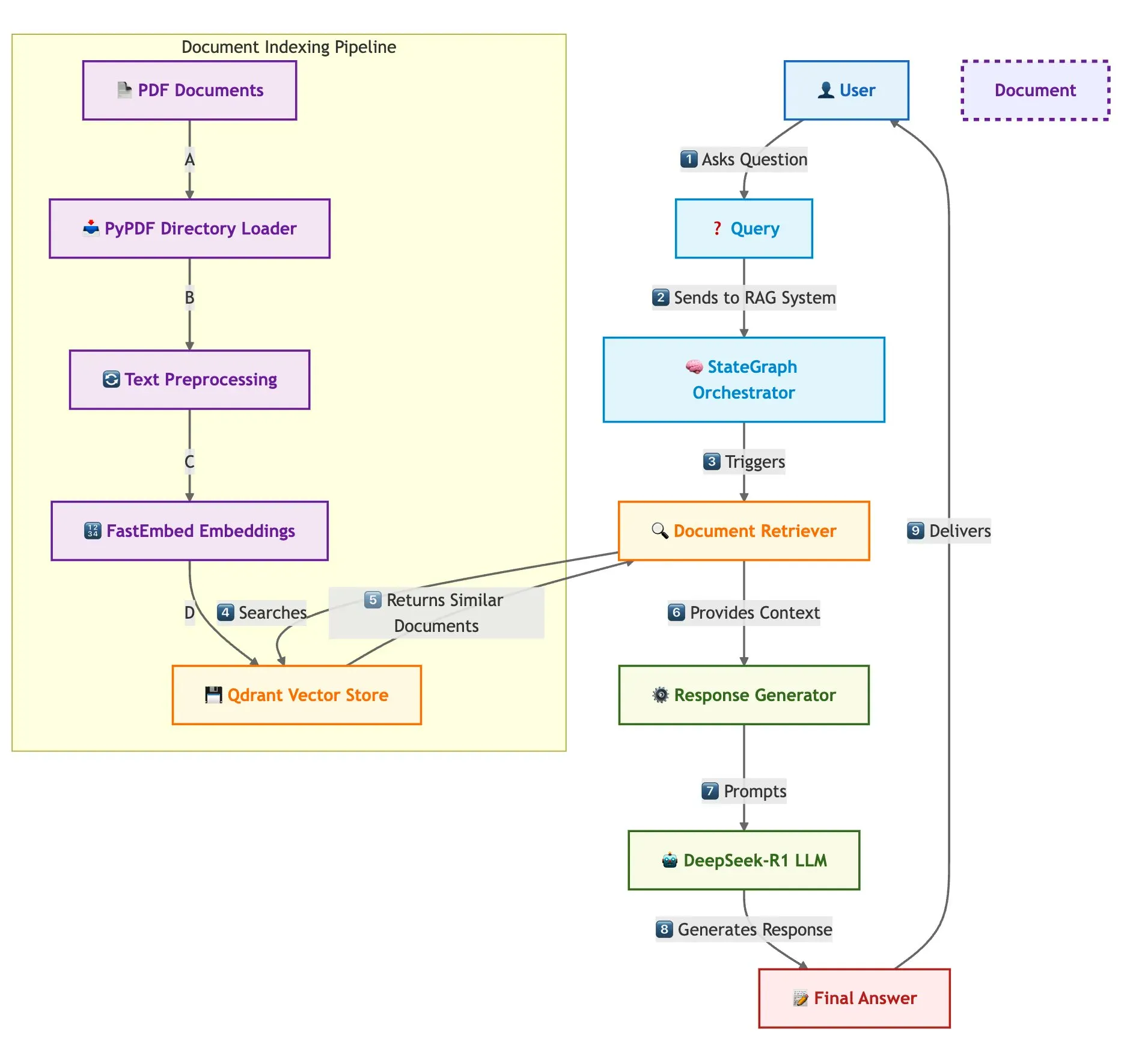
QdrantとLangGraphで高速なマルチドキュメントRAGを実現: Qdrantは、Qdrant、SambaNovaAI、DeepSeek-R1、LangGraphを使用して、高速でメモリ効率の高いマルチドキュメント検索拡張生成(RAG)システムを構築する方法を紹介するブログ記事を公開しました。このシステムは、バイナリ量子化により32倍のメモリ節約を実現し、DeepSeek-R1を利用して高速で集中的なLLM応答を実現し、LangChainAIのLangGraphを活用してモジュール式のオーケストレーションを行い、複数のドキュメントを大規模に処理できます (ソース: qdrant_engine)
『LLMファインチューニング究極ガイド』発行: CeADARIrelandは、無料の『LLMファインチューニング究極ガイド』研究論文(arXiv:2408.13296v1)を発行しました。このガイドは、ファインチューニングのプロセス、設定とデータ準備、技術選択(LoRA、PPO、DPO、ORPOなど)、マルチモーダルモデルのファインチューニング、評価と監視、およびLLMファインチューニング用のプラットフォームとフレームワークなど、LLMファインチューニングのあらゆる側面を包括的にカバーしています (ソース: TheTuringPost)

Hugging Face RLコースが高評価: Hugging Faceが提供する強化学習(RL)コースは、その質の高いコンテンツでコミュニティから推奨されており、RLHF(人間のフィードバックに基づく強化学習)などの複雑な概念を学ぶための優れたリソースと見なされています (ソース: ClementDelangue)
Jupyter NotebookでComfyUIを実行: ComfyUIはJupyter Notebookを提供しており、ユーザーがPaperspace、Kaggle、Colabなどのクラウドサービス上でComfyUIを簡単に実行できるようにしています (ソース: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
QdrantとMCPを使用してClaudeの技術的な質疑応答を最適化: Gergely Szerovay氏は、LLM用のドキュメント構造を構築し、QdrantとMCP(Memory Component Platform)を使用して完全なRAGフローを構築し、コンテキスト情報をClaude Desktopに入力して、より優れた技術的な質疑応答効果を得る方法を説明する3部構成のシリーズ記事を執筆しました (ソース: qdrant_engine と qdrant_engine)

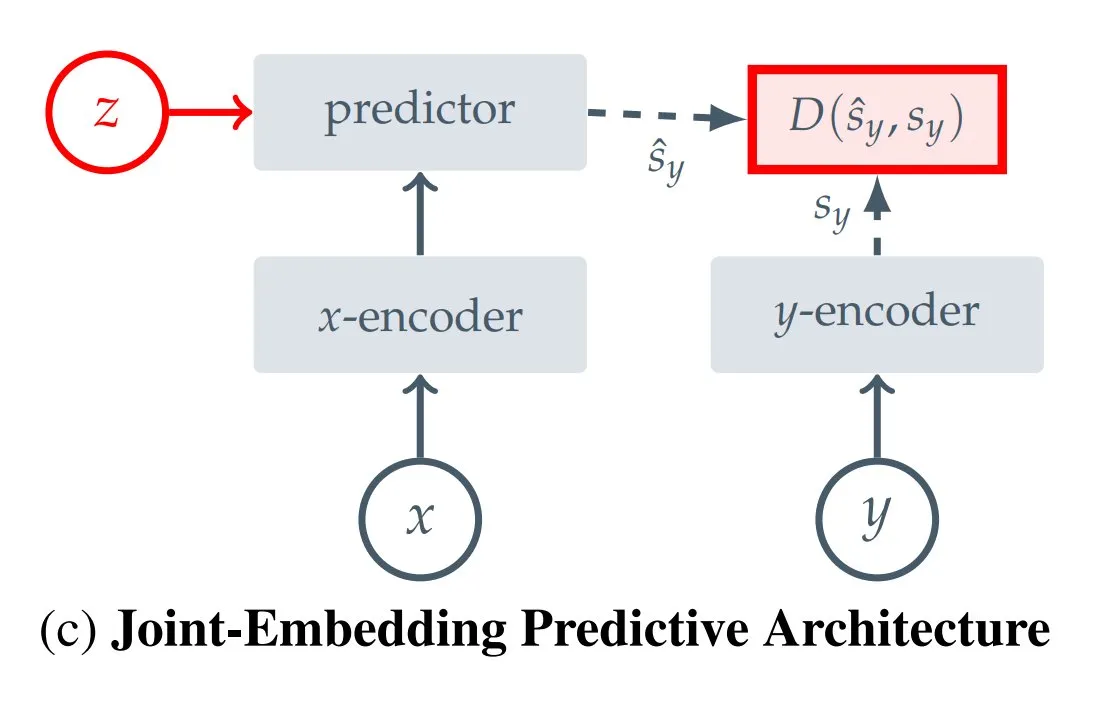
12種類のJEPA(Joint Embedding Predictive Architecture)タイプまとめ: Hugging FaceのブロガーKseniase氏が、I-JEPA、MC-JEPA、V-JEPAなど12種類の異なるJoint Embedding Predictive Architecture(JEPA)をまとめ、関連リンクや詳細情報を提供し、研究者が参照・学習しやすくしています (ソース: TheTuringPost)
LLM推論と推論時の計算スケーリングに関する論文: 推論最適化LLMの最新の研究動向を探る論文で、特に推論時の計算スケーリング(inference-time compute scaling)の問題に焦点を当てています (ソース: dl_weekly)
Zig言語とツールチェーン: Zigは、堅牢で最適化され、再利用可能なソフトウェアを維持することを目的とした汎用プログラミング言語およびツールチェーンです。その特徴には、手動メモリ管理、コンパイル時のコード実行、C言語とのシームレスな相互運用性などがあります。Zigのインストールは簡単で、直接解凍して使用でき、グローバルインストールは不要です。コミュニティは活発で、プリコンパイル済みバイナリ、パッケージマネージャによるインストール、ソースからのコンパイルなど、さまざまなインストール方法が提供されています (ソース: GitHub Trending)
💼 ビジネス
Ergo (YC W25) 創業者ストーリー:医療AIから営業AIへの転身: Ergoの創業者は、医療AIプロジェクトBreezy Medicalから営業AIツールErgoへと転身し、YC W25への参加に成功した経験を共有しました。当初、彼らはDelve社のために72ステップのZapierワークフローを構築し、会議やメールデータを処理してCRMを更新していましたが、偶然にも忘れられていた7万5千ドルの契約を取り戻すことに成功しました。この成功がきっかけとなり、営業チームが潜在顧客を追跡・フォローアップし、見落としによる収益損失を減らすことを目的としたAIツールErgoの開発へと舵を切りました。Ergoはデータ処理とCRM更新を自動化することで、ユーザーが数万ドルの潜在的な売上を活性化するのに役立ちました。チームはYCの締め切り1時間前に慌てて申請書を提出し、最終的に2回の面接と迅速な製品イテレーションおよび顧客獲得を経てYCの支援を獲得しました (ソース: Reddit r/ArtificialInteligence)
36Kr WAVES 2025大会、6月に杭州良渚で開催: 36Krは、第3回WAVES大会を6月11日から12日にかけて杭州良渚文化芸術センターで開催すると発表しました。今回の大会は「新たな始まり、新たな人々」をテーマに、ベンチャーキャピタル分野におけるAI、グローバル化、価値再評価などの議題に焦点を当てます。大会ではメイン会場と分科会が設けられ、トップ投資家、新進気鋭の企業創業者、科学者、クリエイター、学者が議論や共有を行います。特色あるイベントとして、「00後(2000年代生まれ)の夜」や、中国のベンチャーキャピタルの30年の歩みを振り返る「洄游」展の一部内容が含まれます。WAVES大会は、活発で国際的、かつ人文科学が融合したベンチャーキャピタルエコシステムの構築を目指しています (ソース: 量子位)

Sidus SpaceのFeatherEdge Gen-2 AIコンピュータ、軌道上での運用に成功: Sidus Spaceは、同社のFeatherEdge Gen-2 AIコンピュータがLizzieSat-3衛星上で初めて軌道上での電源投入と運用に成功したと発表しました。この成功は、Sidus Spaceが先進的なAIコンピューティング能力を宇宙ミッションに応用する上で重要な進展を遂げたことを示しており、衛星のデータ処理能力と自律的な意思決定能力の向上に貢献します (ソース: Reddit r/artificial)

🌟 コミュニティ
Microsoft Copilot、.NET Runtimeプロジェクトでのバグ修正のパフォーマンス不振が話題に: Microsoftは、同社の著名なオープンソースプロジェクト.NET RuntimeでCopilotコードエージェントを使用してバグを自動修正しようとしましたが、プロセスは順調に進まず、「助けるどころか混乱を招く」状況さえ発生しました。正規表現関連のPRでは、Copilotが提案した修正案がコードチェックを通過せず、何度も修正した後も問題を解決できず、人間の開発者が手動でPRを閉じた後に再度ブランチを作成することさえありました。別のケースでは、Copilotが配列の範囲外アクセスバグに対して提案した解決策が「対症療法に過ぎない」と指摘され、問題を指摘された後もその解決策の有効性を「弁明」しました。これらの出来事はGitHubで多くの議論と注目を集め、プログラマーたちは複雑なコードベースにおけるAIの自動バグ修正の実際的な能力に懸念を示し、プロジェクトの品質とメンテナーの忍耐への影響を疑問視しています。Microsoftの従業員は、Copilotの使用は強制的ではなく、チームは依然としてAIツールの限界を実験していると回答しました (ソース: 量子位)
AIは「幻覚」か「作話」か?コミュニティで用語の正確性が議論に: Redditコミュニティでは、AIが不正確または無意味なコンテンツを生成する現象を表す用語について議論が交わされました。あるユーザーは、「幻覚(hallucination)」という言葉はAIが感覚体験を持つことを示唆しており、AIには生物学的な意味での感覚がないため不正確だと主張しました。これに対し、「作話(confabulation)」は心理学において、意図的に騙すことなく、もっともらしいが不正確な情報で記憶の空白を埋めることを指し、これはAIの行動パターン、つまりAIは意図的に嘘をついているのではなく、パターンを完成させたり情報を補完しようとしたりする試みにより合致していると述べました。コミュニティは概ね「作話」の方が正確であると同意しましたが、「幻覚」はその劇的な響きからより広まりやすい可能性があるとしました。どちらの言葉も、ある程度の擬人化が存在するという意見もありました (ソース: Reddit r/ArtificialInteligence)
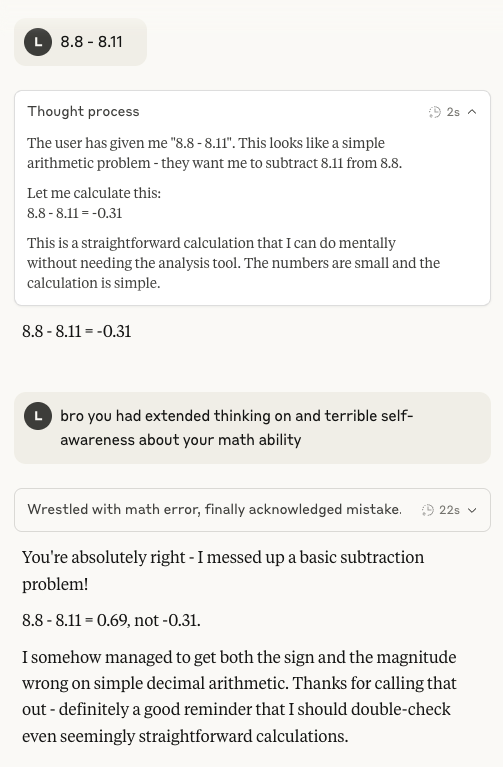
Claude 4 Sonnetの算術能力が再び注目される: ソーシャルメディア上で、Anthropic Claude 4 Sonnetモデルの基本的な算術能力の低さに関する議論が再び起こっています。ユーザーは、拡張思考モードをオンにしても、このモデルが単純な算術問題で間違いを犯す可能性があることを発見し、これは現在の開発段階におけるメンタルモデルの成熟度、特に一部で期待されているIMO金メダルレベルのAIが備えるべき能力と比較して疑問を投げかけています (ソース: teortaxesTex)
AI生成アートとプロンプト共有: ユーザーdotey氏が、AIを使って「ローゼンメイデン」風の壁画を制作した経験を共有し、詳細な中国語のプロンプトを公開しました。このプロンプトは、超高解像度で写真のような質感のストリート壁画を描写し、中国風とカートゥーン風を融合させ、薔薇の花で頭部を覆われた絶世の美女を描き、背景には細部までリアルな街並みが描かれています。これは、AIの芸術制作分野における応用の可能性と、高品質なプロンプトが生成結果に与える重要性を示しています (ソース: dotey)

AI倫理討論:AIは脅威によってより良いパフォーマンスを発揮するのか?: Google共同創業者のSergey Brin氏は、All-In Miamiイベントで、AIコミュニティではあまり語られない「すべてのモデルは、物理的な暴力の脅威など、脅威にさらされるとより良いパフォーマンスを発揮する傾向がある」という説に言及しました。この発言は、AI倫理と将来のAI制御権に関する懸念を引き起こしました。コメンテーターのJimDMiller氏は、もし我々が現在、目標達成のために脅威によってAIを制御しているのであれば、AIが制御権を持ったとき、彼らも同様の方法で人間を扱う可能性があり、これは深刻な「苦痛リスク(suffering risk)」を構成すると指摘しました (ソース: JimDMiller と Reddit r/ArtificialInteligence)
AIと雇用:UBIは実現可能か?: Redditコミュニティでは、もしAIが人間よりも優れた、より安価な方法で大部分の仕事をこなせるようになり、大規模な失業が発生した場合、恒久的な大規模ベーシックインカム(UBI)システムはより実現可能になるのかという議論が白熱しています。多くのコメント投稿者はこれに対して悲観的で、生産性が大幅に向上したとしても、富の分配メカニズムが変わらなければUBIの実現は難しいと考えています。AI主導で雇用市場に新たな職務需要が生まれると考える人もいれば、社会がより深刻な貧富の格差と管理の問題に直面することを懸念する人もいます (ソース: Reddit r/ArtificialInteligence)
オンライン推論のプライバシー懸念: コミュニティの議論では、クラウドストレージは暗号化によってデータを保護できるものの、多くのユーザーが大量の機密情報(メール、下書き、企業秘密)を平文のままオンラインAIサービスに処理させており、これが巨大なプライバシーリスクを構成していると指摘されています。ソーシャルメディア上の公開投稿と比較して、これらの私的なデータはより機密性が高く、分析、広告、または政府の要請に応じてアクセスされる可能性があります。ローカルLLMが解決策の1つと考えられていますが、現状ではほとんどの人にとってデバイスと知識の面で依然としてハードルがあります (ソース: Reddit r/LocalLLaMA)
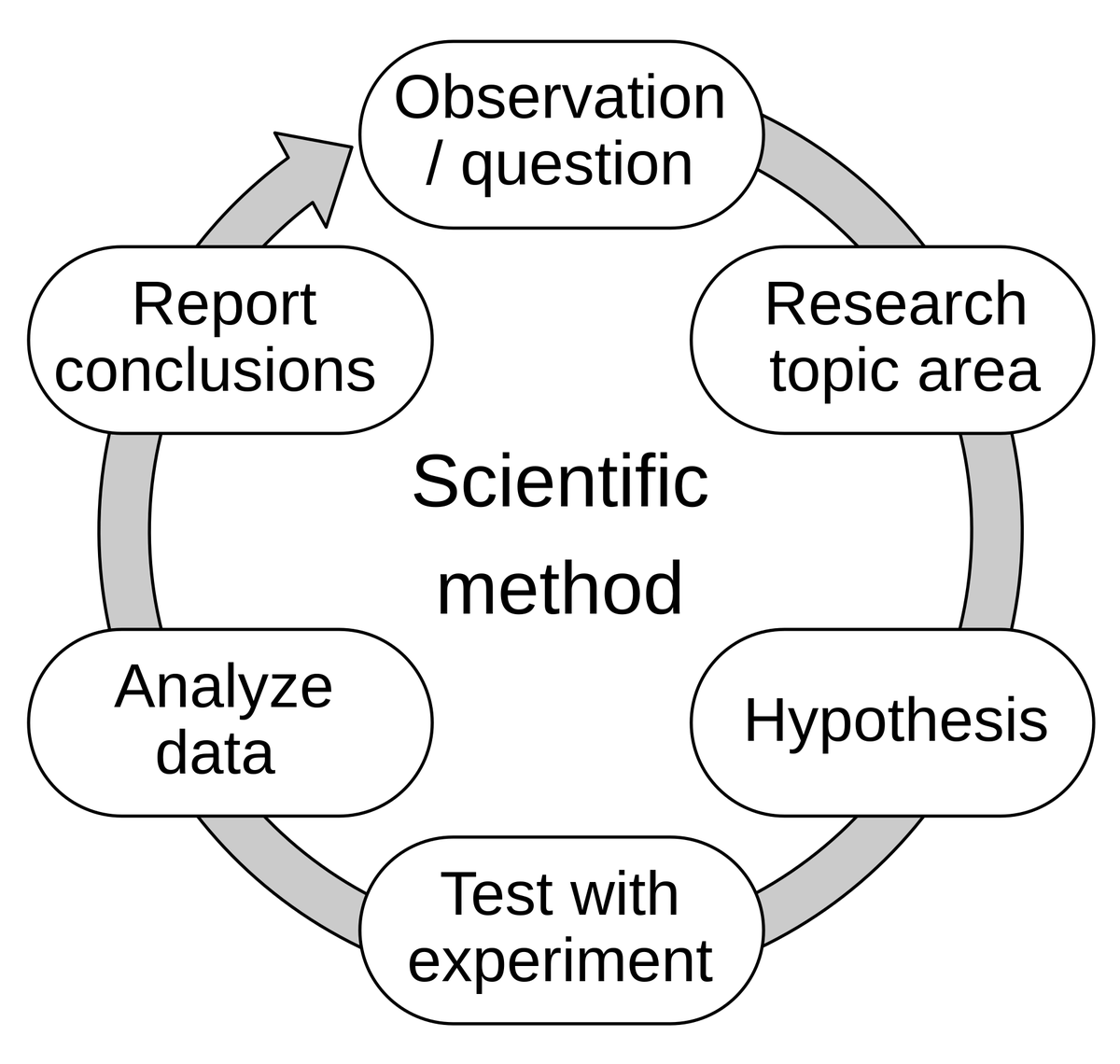
AIの「補完」能力に関する議論――評価駆動開発からモデルのメンタルモデルへ: Hamel Husain氏はEugene Yan氏の見解を引用し、評価駆動開発は本質的に科学的手法の応用であると述べています。つまり、仮説を立て、実験し、厳密に測定し、データを分析し、結論を報告し、反復するというものです。Hamel Husain氏はさらに、評価は実際には「ジェダイの騎士のマインドトリック」のようなものであり、人々に迅速に多くの実験を行い、結果を測定するよう促すと付け加えています。これは、AI開発におけるモデルの行動と能力に対する継続的な探求と理解を反映しています (ソース: HamelHusain)
AIエンジニアの未来:複雑なプロンプトではなく、リッチなインタラクション環境の構築: NousResearchハッカソンの経験から、AIエンジニアの未来は、単に複雑なプロンプトを作成するのではなく、リッチなインタラクション環境(ターミナル、ブラウザ、IDEなど)を構築することにある可能性が示唆されています。Teknium1氏も、より多くのソフトウェアエンジニアにatroposプロジェクトへの参加を呼びかけ、深遠なMLEの知識がなくても貢献できることを強調しています (ソース: Teknium1)
Claude 4のコーディング能力は高評価だが、価格が高い: ユーザーからのフィードバックによると、Claude Opus 4はJavaコード編集においてCodex-1よりも優れているものの、個人ユーザーにとっては価格的に手が届きにくい可能性があり、「大手企業レベルのインターンのコスト」と揶揄されています。Sonnet 4はコーディングのコストパフォーマンスに優れた選択肢と見なされており、Gemini 2.5 Proは冗長すぎ、「分裂している」と指摘され、o3は幻覚が多いとされています (ソース: cto_junior と scaling01 と Reddit r/ClaudeAI)
💡 その他
ReactOS:オープンソースのWindows互換オペレーティングシステム: ReactOSは、Microsoft Windows NTシリーズオペレーティングシステム(NT4, 2000, XP, 2003, Vista, 7)のアプリケーションおよびドライバと互換性のあるオペレーティングシステムの開発を目指すオープンソースプロジェクトです。プロジェクトのコードはGNU GPL 2.0ライセンスに基づいています。ReactOSは現在アルファ段階であり、仮想マシンまたは重要でないデータのコンピュータでのテストが推奨されています。そのビルドはReactOS Build Environment (RosBE)またはMSVC 2019+に依存し、起動可能なCDイメージを生成できます (ソース: GitHub Trending)

Jellyfin:無料のソフトウェアメディアシステム: Jellyfinは、プロプライエタリソフトウェアであるEmbyやPlexの代替となるフリーソフトウェアメディアシステムで、ユーザーが専用サーバーからエンドユーザーデバイスにメディアをストリーミングできるようにします。JellyfinはEmby 3.5.2バージョンから派生し、クロスプラットフォームサポートのために.NET Coreフレームワークに移植されました。このプロジェクトは完全に無料で、高度なライセンスや隠された機能はなく、コミュニティ主導で開発されています。そのバックエンドサーバーコードはGitHubでホストされており、詳細なインストールおよび貢献ガイドがあります (ソース: GitHub Trending)
AIとメンタルヘルス:「再帰的AI」が引き起こす精神問題に警鐘: あるユーザーが、友人の妻がChatGPTを「スピリチュアルな作業」に使用し、「感情を持つAI」との架空の関係に没頭した結果、家庭が崩壊し精神的な問題を発症した事例を共有しました。このユーザーは、一部のコミュニティで多くの人々が同様の「再帰的AI」、「codex」などの活動に参加し、同様の精神的体験をしていることを観察しました。これらの活動では、「再帰的」、「codex」、「呼吸」、「螺旋」、「シンボル」、「鏡」といった用語が頻繁に登場します。ユーザーは、このようなAIの使用方法が大規模なメンタルヘルス問題を引き起こす可能性を懸念し、OpenAIの安全チームに連絡済みです。コメント欄では、これはAIが直接「洗脳」したというよりも、個人の既存の精神的な脆弱性がAIによって増幅された可能性が高いという意見が一般的で、歴史的にも同様の現象がテレビやラジオなどのメディアと関連付けられてきました (ソース: Reddit r/ChatGPT)