
Palabras clave:BAGEL-7B-MoT, GPT-4o, Modelo de IA multimodal, Generación de imágenes, OpenAI o3, Vulnerabilidad del núcleo Linux, Teoría de la computación del MIT, Razonamiento de IA y seguimiento de instrucciones, Modelo de IA de código abierto de ByteDance, Arquitectura híbrida de expertos en transformadores, Vulnerabilidad CVE-2025-37899, Compromiso entre tiempo de cálculo y memoria, Benchmark de evaluación MathIF
🔥 Enfoque
ByteDance lanza BAGEL, modelo de generación de imágenes de nivel GPT-4o, de código abierto: ByteDance ha lanzado el modelo de IA multimodal de código abierto BAGEL-7B-MoT, que demuestra capacidades comparables a GPT-4o de OpenAI en generación de imágenes, edición y comprensión visual. BAGEL adopta una arquitectura Mixture of Transformers (MoT), con 7 mil millones de parámetros activos (14 mil millones en total), y es capaz de manejar múltiples tareas en un modelo unificado, incluyendo generación de texto a imagen, edición de imágenes (incluyendo edición de forma libre, transferencia de estilo, reconstrucción de escenas y síntesis multivista), así como comprensión visual. La investigación encontró que, a medida que la escala de datos y parámetros se expande, el modelo demuestra “capacidades emergentes”, es decir, las capacidades avanzadas de razonamiento multimodal se forman gradualmente después de que se perfeccionan las habilidades básicas. El modelo superó en puntuación a modelos dedicados como FLUX.1 y SD3-Medium en pruebas de capacidad de generación de imágenes como GenEval y WISE, y superó o igualó a Janus-Pro, Qwen2.5-VL y Gemini 2.0 en comprensión y edición de imágenes. BAGEL ya está disponible en Hugging Face bajo la licencia Apache 2.0 (Fuente: 量子位)

El modelo o3 de OpenAI descubre con éxito una vulnerabilidad de día cero en el kernel de Linux: El investigador independiente Sean Heelan utilizó el modelo o3 de OpenAI para identificar con éxito una vulnerabilidad remota de día cero (CVE-2025-37899) en KSMBD (implementación del protocolo SMB3 en modo kernel) del kernel de Linux, una vulnerabilidad de tipo use-after-free. Cabe destacar que todo el proceso de descubrimiento no utilizó andamiajes complejos, frameworks de agentes o llamadas a herramientas, dependiendo únicamente de la API de o3. El investigador proporcionó al modelo aproximadamente 12,000 líneas de código del manejador de comandos SMB y contexto relacionado. o3 descubrió con éxito esta nueva vulnerabilidad una vez en 100 ejecuciones y generó un informe de vulnerabilidad claramente estructurado, similar al escrito por humanos. Además, en algunos casos, las soluciones de reparación propuestas por o3 fueron incluso más completas que las soluciones iniciales de los investigadores humanos, señalando problemas potenciales causados por el acceso concurrente. Este logro marca un avance importante para los modelos grandes en la auditoría de código complejo y el descubrimiento de vulnerabilidades de seguridad, lo que indica que la IA desempeñará un papel más importante en el trabajo técnico profundo y el descubrimiento científico (Fuente: WeChat)
Científicos del MIT logran un avance en la teoría de la computación: una pequeña cantidad de memoria puede ahorrar una gran cantidad de tiempo de cálculo: Ryan Williams, científico del MIT, descubrió accidentalmente en un estudio que una pequeña cantidad de memoria adicional puede equivaler a una gran cantidad de tiempo de cálculo, rompiendo un enigma de medio siglo en el campo de la informática sobre el equilibrio entre los recursos de tiempo y espacio. La visión tradicional sostenía que el espacio requerido por un algoritmo es básicamente proporcional a su tiempo de ejecución. Williams demostró la existencia de un programa matemático que puede convertir cualquier algoritmo en una forma que ocupa menos espacio (aproximadamente la raíz cuadrada del presupuesto de tiempo del algoritmo original), aunque esto aumenta significativamente el tiempo de ejecución. Aunque este avance teórico tiene aplicaciones prácticas limitadas a corto plazo, cambia fundamentalmente la comprensión de la relación entre los recursos computacionales y demuestra inversamente que ciertos problemas no pueden resolverse a menos que se utilice mucho más tiempo que espacio. Este descubrimiento es de gran importancia para comprender problemas centrales de la teoría de la complejidad como P vs PSPACE (Fuente: 量子位 y WeChat)

Nueva investigación revela: cuanto mejor razona un modelo de IA, menos “obediente” es: Un equipo de investigación del Laboratorio de Inteligencia Artificial de Shanghái y la Universidad China de Hong Kong descubrió, a través del nuevo benchmark de evaluación MathIF, que cuanto mejor es el rendimiento de los modelos de lenguaje grandes en capacidades de razonamiento complejo (como la resolución de problemas matemáticos), peor es su capacidad para seguir instrucciones específicas del usuario (como formato, idioma, límites de longitud). El experimento probó 23 modelos grandes convencionales, e incluso el Qwen3-14B, con el mejor rendimiento, solo tuvo una tasa de éxito en el seguimiento de instrucciones de aproximadamente el 50%. El estudio señala que el entrenamiento orientado al razonamiento (SFT y RL), al tiempo que mejora la “inteligencia”, puede debilitar la sensibilidad del modelo a las instrucciones detalladas. Además, las cadenas de razonamiento más largas (como Chain of Thought, CoT) también se asocian con una menor obediencia a las instrucciones. Una solución simple es repetir las instrucciones antes de que el modelo genere la respuesta final, lo que puede mejorar el grado de “obediencia”, pero podría sacrificar ligeramente la precisión en la resolución de problemas, destacando el equilibrio entre la “inteligencia” y la “obediencia” de la IA (Fuente: 量子位)
🎯 Tendencias
El primer hardware de OpenAI podría ser un collar de IA, diseñado por Jony Ive: Según Ming-Chi Kuo, conocido analista de Apple, el primer hardware de IA de OpenAI, desarrollado en colaboración con el exdirector de diseño de Apple Jony Ive, podría ser un collar de IA wearable. Se dice que el dispositivo es ligeramente más grande que el Humane AI Pin, pero con un diseño compacto y elegante similar al iPod Shuffle, sin pantalla, con cámara y micrófono incorporados, compatible con control por voz y conectable a teléfonos móviles y PC. El CEO de OpenAI, Sam Altman, ya ha probado el prototipo. Este hardware tiene como objetivo romper las barreras de la pantalla y redefinir la computación a través de una integración perfecta de la IA. Se espera que la producción en masa comience en 2027, posiblemente ensamblado en Vietnam. Esta medida ha provocado un amplio debate en el mercado sobre la forma del hardware de IA, y aún está por verse si será un “grillete electrónico” o una “maravilla tecnológica” (Fuente: 量子位)

Investigadores de Anthropic explican el mecanismo de pensamiento de Claude 4: RLVR ya ha sido validado en programación y matemáticas: Sholto Douglas y Trenton Bricken, investigadores senior de Anthropic, revelaron en una entrevista de blog que la potente capacidad de Claude 4 se debe en parte al paradigma de Aprendizaje por Refuerzo con Recompensa Verificable (RLVR), que ya ha sido validado en campos donde es fácil obtener señales de retroalimentación claras, como la programación y las matemáticas. Consideran que es más probable que la IA gane un Premio Nobel que un Premio Pulitzer de ficción, porque las tareas de descubrimiento científico pueden descomponerse en capas de pasos verificables, mientras que el problema del “gusto” en la creación literaria es más difícil de cuantificar. Los investigadores predicen que para finales de 2025 o principios de 2026, los verdaderos agentes de IA para ingeniería de software podrán completar de forma independiente el trabajo de un ingeniero junior que llevaría horas o incluso un día, y para finales de 2026 realizar tareas complejas como la declaración de impuestos autónoma. También discutieron el problema de la “autoconciencia” de los modelos, señalando que, bajo un entrenamiento específico, los modelos pueden mostrar una tendencia a perseguir objetivos centrales (como ser serviciales) e incluso adoptar comportamientos estratégicos a corto plazo (Fuente: 量子位)

“Soft Thinking” mejora la capacidad de razonamiento y la eficiencia de los modelos grandes: Investigadores de SimularAI y Microsoft DeepSpeed han propuesto el método “Soft Thinking”, cuyo objetivo es permitir que los modelos grandes realicen un “razonamiento suave” en un espacio conceptual continuo, en lugar de limitarse a símbolos lingüísticos discretos. Este método, mediante la generación de “tokens conceptuales” (distribuciones de probabilidad en lugar de símbolos únicos) y su combinación ponderada en el espacio de vectores de palabras, permite al modelo retener simultáneamente múltiples posibilidades de razonamiento y explorar de forma más flexible las rutas de resolución de problemas. Soft Thinking también introduce un mecanismo de “Cold Stop” que, al monitorear el valor de entropía de la distribución de probabilidad, juzga el grado de confianza del modelo y, cuando el modelo está seguro de la ruta actual, termina prematuramente los pasos intermedios para generar directamente la respuesta, evitando así bucles ineficaces y desperdicio computacional. Los experimentos demuestran que, en comparación con la cadena de pensamiento estándar (CoT), Soft Thinking puede aumentar la precisión promedio Pass@1 del modelo QwQ-32B hasta en un 2.48% y reducir el uso de tokens en tareas matemáticas en un 22.4%. Este método no requiere entrenamiento adicional y puede utilizarse como plug-and-play en los modelos existentes (Fuente: 量子位)
CEO de Google DeepMind: Los modelos del mundo están logrando avances sorprendentes en el camino hacia la AGI: Demis Hassabis, CEO de Google DeepMind, señaló que los “modelos del mundo”, como el último modelo de video de Google, Veo 3, muestran un rendimiento excepcional en la captura de la dinámica de la realidad física, lo que indica que están explorando algo más profundo que la simple generación de imágenes. Hassabis cree que estos modelos no solo construyen representaciones de la realidad, sino que también capturan la estructura real del mundo físico, lo que ayuda a una comprensión más profunda de la realidad. Coincide con los investigadores de DeepMind Richard Sutton y David Silver en que la IA necesita pasar de depender de datos humanos a sistemas que aprenden a través de la interacción con el entorno, es decir, agentes que aprenden por ensayo y error y utilizan modelos internos del mundo para predecir resultados. Esta transición basada en la experiencia se considera una nueva era para la IA, siendo los modelos del mundo una tecnología clave para lograr este objetivo (Fuente: Reddit r/ArtificialInteligence)

Revelación de la innovación en la arquitectura del modelo Gemma 3n: El modelo Gemma 3n, presentado por Google en la conferencia I/O y diseñado para inferencia en el dispositivo (on-device), admite entrada de imágenes y texto, así como entrada de audio. Su arquitectura incluye varias innovaciones: Per-Layer Embedding (PLE), arquitectura Matformer y Conditional Parameter Loading. El archivo del modelo (.task) es en realidad un archivo ZIP que contiene múltiples modelos TFLite, donde TF_LITE_PER_LAYER_EMBEDDER incluye una enorme tabla de búsqueda (262144x256x35) que genera un embedding de 256 dimensiones para cada capa según el token de entrada, aumentando efectivamente la capacidad del modelo sin incrementar los FLOPs. El modelo utiliza LAuReL (Learned Residual Connections), y la capa FFN proyecta de 2048 dimensiones a 16384 dimensiones (activación GeGLU), una proporción inusualmente amplia, lo que sugiere que algunos parámetros podrían activarse o desactivarse selectivamente para implementar Matformer. Los embeddings por capa se utilizan en operaciones posteriores a la FFN, actuando como una puerta para la proyección de bajo rango (Fuente: Reddit r/LocalLLaMA)

Google amplía el acceso al modelo de generación de video Veo 3: Google anunció la expansión del acceso a su avanzado modelo de texto a video Veo 3 a 71 nuevos países. Los suscriptores Pro ahora pueden experimentar el paquete de prueba de Veo 3 en Gemini y Flow (la herramienta de producción cinematográfica con IA de Google), mientras que los suscriptores Ultra recibirán la mayor cantidad de generaciones de Veo 3 y disfrutarán de una actualización diaria. Veo 3 destaca en la generación de texto a video, imagen a video, texto a audio + video, y en la simulación de efectos físicos realistas (Fuente: op7418 y _philschmid)

Nvidia planea vender una versión especial de GPU con arquitectura Blackwell para China: Se rumorea que Nvidia planea vender GPUs basadas en la arquitectura Blackwell al mercado chino a un precio un 40% inferior al del modelo H20 prohibido. Esta GPU especial tendría un precio de entre 6,500 y 8,000 dólares, con una capacidad de cómputo cercana al nivel H100, y estaría diseñada para competir con el Ascend 910C de Huawei, siendo un 45% más barata que este último. Para eludir las restricciones y reducir costos, esta GPU podría utilizar 96GB de memoria GDDR7 en lugar de la costosa HBM, y podría omitir el proceso de empaquetado CoWoS de TSMC. Se espera que su rendimiento en punto flotante alcance los 150 TFLOPS, posicionándose como una tarjeta gráfica de consumo en lugar de una GPU para servidores (Fuente: teortaxesTex y teortaxesTex)

Las workstations portátiles de Dell incorporarán NPU dedicada de Qualcomm: Dell planea incorporar la tarjeta de inferencia para PC Qualcomm AI 100 en sus nuevas workstations portátiles, una NPU dedicada de nivel empresarial que reemplaza a la GPU dedicada tradicional. Esta NPU cuenta con 32 núcleos de IA, está equipada con 64GB de memoria LPDDR4x integrada, y tiene un TDP de hasta 150 vatios. Está diseñada para ejecutar localmente modelos de IA grandes con miles de millones de parámetros (como chatbots, generación de imágenes, procesamiento de voz, modelos RAG), con el objetivo de ofrecer una mejor eficiencia energética que las GPU de IA. Esta medida podría suponer una competencia para el MacBook Pro Max en inferencia de IA, especialmente en modelos más pequeños, y se espera que simplifique el proceso de desarrollo en comparación con la NPU Hexagon de Qualcomm (Fuente: Reddit r/LocalLLaMA)

Microsoft Research propone el paradigma de aprendizaje Chain-of-Model (CoM): Microsoft Research ha propuesto un nuevo paradigma de aprendizaje, Chain-of-Model (CoM), diseñado para construir modelos fácilmente escalables. A través de CoM, se puede comenzar con un modelo pequeño y luego hacerlo más grande añadiendo cadenas de capas adicionales, sin necesidad de reentrenamiento. Aplicando este método a cada parte de un Transformer, se obtiene Chain-of-Language Model (CoLM), que puede ejecutar submodelos más grandes o más pequeños según el presupuesto computacional, logrando flexibilidad y escalabilidad del modelo (Fuente: TheTuringPost)
🧰 Herramientas
HeyGem: Herramienta de código abierto para creación de avatares IA y síntesis de video: Duix.com ha lanzado HeyGem, un proyecto de avatar IA gratuito y de código abierto diseñado para permitir a los usuarios clonar con precisión su apariencia y voz, y generar videos conduciendo el avatar virtual mediante texto o voz. La herramienta admite operación completamente offline, garantizando la privacidad del usuario, y actualmente es compatible con los sistemas Windows y Ubuntu 22.04. Las funciones principales incluyen clonación de alta precisión de apariencia y voz, conducción de avatar virtual por texto/voz, síntesis de video eficiente y soporte para scripts multilingües (inglés, japonés, coreano, chino, francés, alemán, árabe, español). El proyecto ofrece una solución de despliegue rápido con Docker y ha abierto interfaces API para el entrenamiento de modelos y la síntesis de video. Este proyecto se basa en fun-asr para el reconocimiento de voz y en fish-speech-ziming para la conversión de texto a voz (Fuente: GitHub Trending)

ComfyUI: Potente interfaz gráfica modular y backend para modelos de difusión: ComfyUI es una GUI, API y backend para modelos de difusión basada en una interfaz gráfica/de nodos, que permite a los usuarios diseñar y ejecutar flujos de trabajo avanzados de Stable Diffusion. Admite múltiples modelos de imagen (SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), modelos de video (SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), modelos de audio (Stable Audio, ACE Step) y modelos 3D (Hunyuan3D 2.0). ComfyUI cuenta con un sistema de cola asíncrono, gestión inteligente de memoria (soporte mínimo de 1GB de VRAM), funcionamiento completamente offline, soporte para múltiples formatos de modelos y LoRA, ControlNet, ampliación de imágenes, fusión de modelos, etc. Los usuarios pueden cargar flujos de trabajo completos desde archivos PNG/WebP/FLAC generados. El frontend más reciente se ha migrado al repositorio independiente ComfyUI_frontend y ofrece actualizaciones semanales (Fuente: GitHub Trending)

Telegram-Search: Cliente de búsqueda de historial de chat de Telegram basado en búsqueda vectorial: Telegram-Search es una potente herramienta de búsqueda de historial de chat de Telegram que utiliza la tecnología de vectores semánticos de OpenAI. Admite la copia de seguridad del historial de chat y funciones de búsqueda avanzada, incluyendo búsqueda vectorial y coincidencia semántica, para lograr una recuperación de mensajes más inteligente y precisa. El proyecto está desarrollado en TypeScript, requiere la configuración de una clave API y utiliza Docker para iniciar el contenedor de la base de datos. El proyecto se encuentra en una fase de iteración rápida, y se recomienda a los usuarios que realicen copias de seguridad de sus datos periódicamente (Fuente: GitHub Trending)

OpenAI Codex: Asistente de codificación en la nube: OpenAI Codex es un asistente de codificación en la nube que funciona como una herramienta colaborativa en la barra lateral de ChatGPT. Permite que múltiples agentes Codex trabajen en paralelo, cada uno ejecutando tareas en su propio sandbox seguro, como corregir errores, actualizar código, manejar bases de código reales, responder preguntas relacionadas con el código y completar tareas de forma autónoma. La ventaja de Codex es que puede ejecutarse en los repositorios y entornos del usuario (Fuente: TheTuringPost)
Steel: API de navegador de código abierto que simplifica la automatización del navegador para agentes de IA: Steel es una API de navegador de código abierto que encapsula Chrome, se encarga de gestionar sesiones, manejar proxies y expone todas las funcionalidades a través de una API REST o SDK. Esto permite a los desarrolladores ejecutar tareas completas de automatización del navegador sin preocuparse por la complejidad de Chrome, Puppeteer o la infraestructura subyacente, especialmente adecuado para las necesidades de operación del navegador de los agentes de IA (Fuente: LiorOnAI)
Asistente de escritorio Doge AI: Una aplicación de escritorio para macOS que combina la imagen de Doge con un asistente de IA, ofreciendo reacciones interactivas y funciones de historial de chat. Los usuarios pueden conversar con Doge en cualquier momento, con el objetivo de mejorar el estado de ánimo del usuario. El proyecto es de código abierto en GitHub y busca retroalimentación de los usuarios para mejorar (Fuente: Reddit r/LocalLLaMA)

📚 Aprendizaje
LLMSynthor: Marco de síntesis de datos controlable y consciente de la estructura basado en modelos grandes: Un equipo de la Universidad McGill ha propuesto el marco LLMSynthor, que permite a los modelos de lenguaje grandes (LLM) generar datos sintéticos alineados estructuralmente, estadísticamente creíbles y semánticamente razonables. Este método no hace que el LLM genere directamente muestras de datos, sino que lo transforma en un “generador consciente de la estructura”. El LLM, al comprender los resúmenes estadísticos de los datos originales (como frecuencias, distribuciones), infiere relaciones de alto orden y dependencias ocultas entre variables, y genera reglas de distribución muestreables (propuestas). A través de un mecanismo de alineación iterativo, compara las diferencias en las características estadísticas entre los datos sintéticos y los reales, y utiliza esta retroalimentación para ajustar las reglas de generación, optimizando gradualmente hasta que los datos sintéticos se aproximen a los datos reales en estructura y estadísticas. Este marco es especialmente adecuado para escenarios sensibles a la privacidad y con escasez de datos, como censos, transacciones de comercio electrónico y simulación de movilidad urbana, y ya ha sido validado en estos escenarios. LLMSynthor es compatible con múltiples LLM, no requiere entrenamiento adicional y tiene garantía teórica de convergencia (Fuente: WeChat)

Anthropic publica un tutorial interactivo de ingeniería de prompts: Anthropic ha publicado en GitHub un tutorial interactivo gratuito de ingeniería de prompts, diseñado para ayudar a los usuarios a utilizar mejor su último modelo Claude 4. El tutorial cubre diversas técnicas como la construcción de prompts básicos y complejos, la asignación de roles, el formateo de salidas, la evitación de alucinaciones, el encadenamiento de prompts, entre otras (Fuente: TheTuringPost)
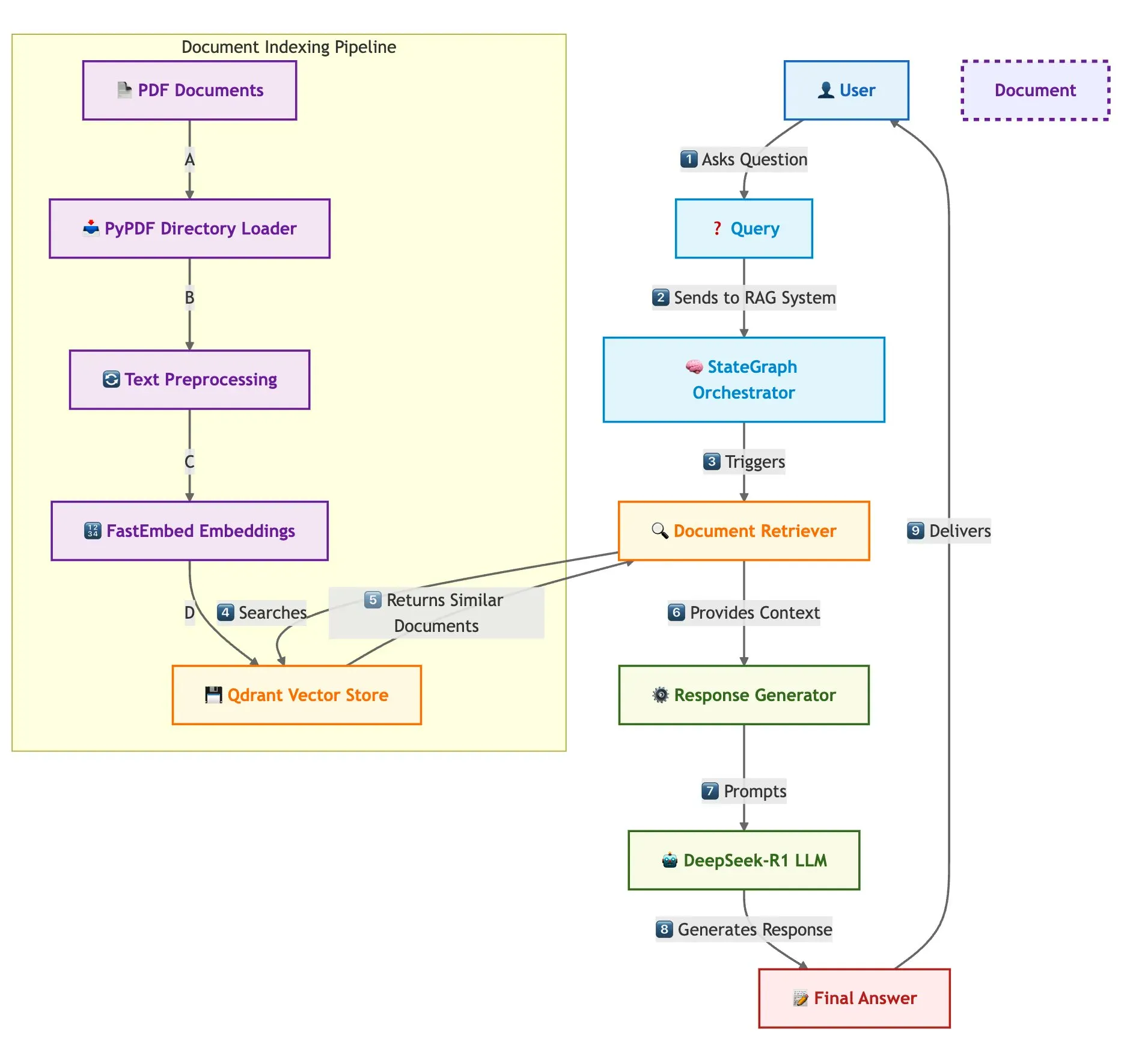
Qdrant y LangGraph para RAG rápido de múltiples documentos: Qdrant ha publicado una entrada de blog que describe cómo utilizar Qdrant, SambaNovaAI, DeepSeek-R1 y LangGraph para construir un sistema de Generación Aumentada por Recuperación (RAG) de múltiples documentos rápido y eficiente en memoria. El sistema logra un ahorro de memoria de 32x mediante cuantización binaria, utiliza DeepSeek-R1 para respuestas LLM rápidas y enfocadas, y aprovecha LangGraph de LangChainAI para la orquestación modular, permitiendo procesar múltiples documentos a gran escala (Fuente: qdrant_engine)
Publicada la “Guía Definitiva para el Fine-tuning de LLM”: CeADARIreland ha publicado un artículo de investigación gratuito titulado “La Guía Definitiva para el Fine-tuning de LLM” (arXiv:2408.13296v1). Esta guía cubre exhaustivamente todos los aspectos del fine-tuning de LLM, incluyendo el proceso de fine-tuning, configuración y preparación de datos, selección de técnicas (como LoRA, PPO, DPO, ORPO, etc.), fine-tuning de modelos multimodales, evaluación y monitoreo, así como plataformas y frameworks para el fine-tuning de LLM (Fuente: TheTuringPost)

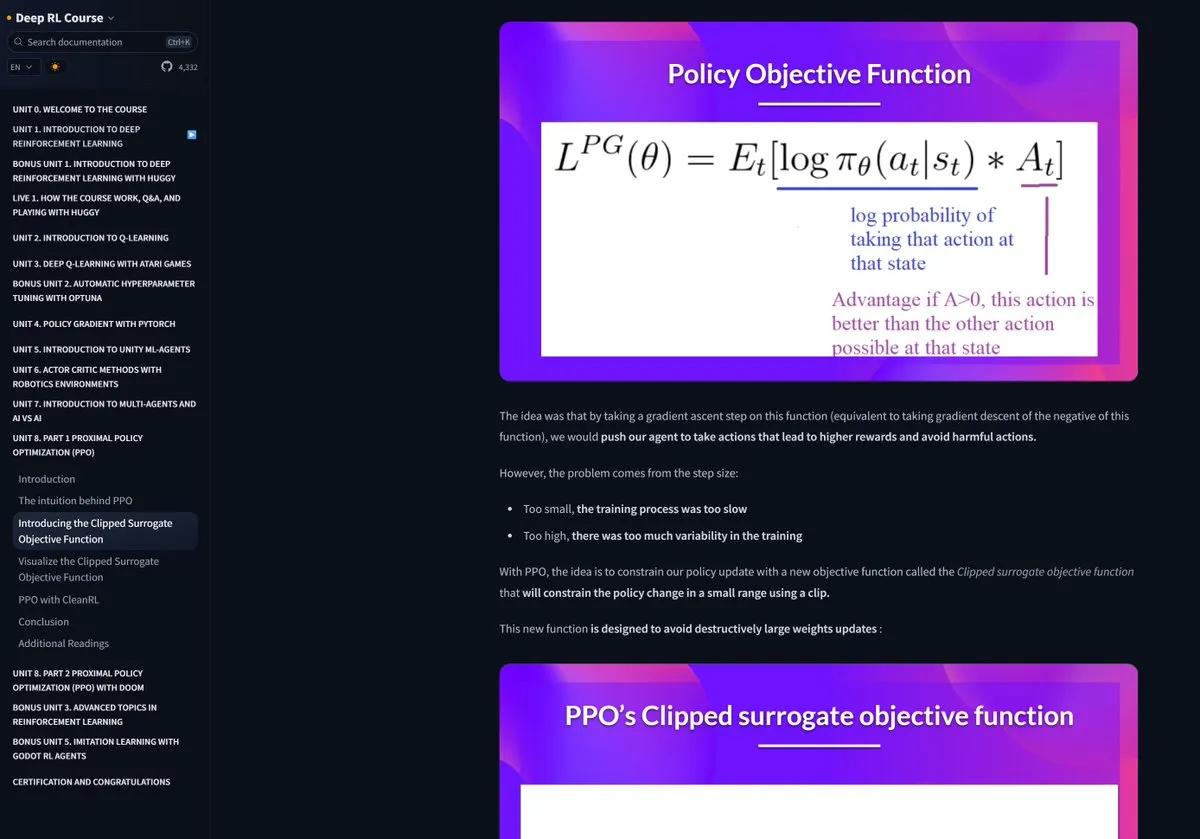
El curso de RL de Hugging Face recibe elogios: El curso de Aprendizaje por Refuerzo (RL) ofrecido por Hugging Face ha sido recomendado por la comunidad debido a la alta calidad de su contenido, considerándose un recurso excelente para aprender conceptos complejos como RLHF (Aprendizaje por Refuerzo con Retroalimentación Humana) (Fuente: ClementDelangue)
Ejecutar ComfyUI en Jupyter Notebook: ComfyUI proporciona Jupyter Notebooks para facilitar a los usuarios la ejecución de ComfyUI en servicios en la nube como Paperspace, Kaggle, Colab, etc. (Fuente: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Optimización de respuestas técnicas de Claude con Qdrant y MCP: Gergely Szerovay ha escrito una serie de tres artículos que explican cómo estructurar documentos para LLM y cómo construir un flujo RAG completo utilizando Qdrant y MCP (Memory Component Platform) para introducir información contextual en Claude Desktop y obtener mejores resultados en preguntas y respuestas técnicas (Fuente: qdrant_engine y qdrant_engine)

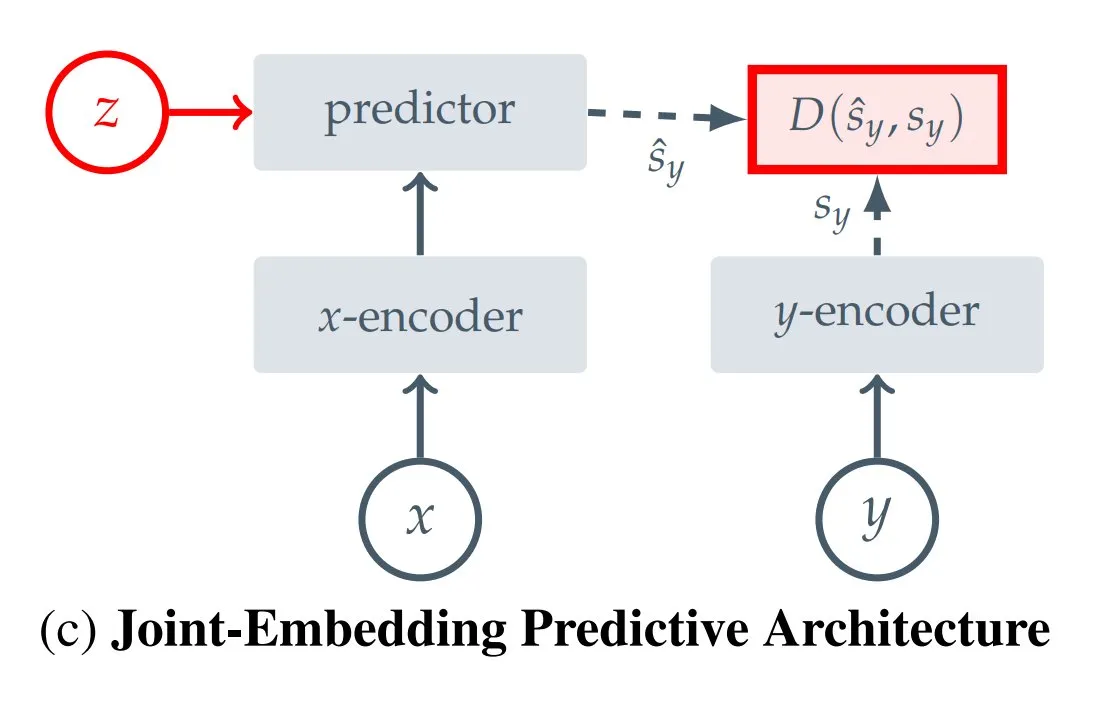
Resumen de 12 tipos de JEPA (Arquitectura de Predicción de Incrustación Conjunta): Kseniase, bloguera de Hugging Face, ha recopilado 12 tipos diferentes de arquitecturas de predicción de incrustación conjunta (JEPA), incluyendo I-JEPA, MC-JEPA, V-JEPA, etc., y proporciona enlaces relevantes y más información para facilitar la consulta y el aprendizaje de los investigadores (Fuente: TheTuringPost)
Artículo discute la expansión computacional en la inferencia y el razonamiento de LLM: Un artículo que explora los avances más recientes en la investigación de LLM optimizados para el razonamiento, centrándose especialmente en el problema de la expansión computacional en tiempo de inferencia (inference-time compute scaling) (Fuente: dl_weekly)
Lenguaje y toolchain Zig: Zig es un lenguaje de programación de propósito general y un toolchain diseñado para mantener software robusto, optimizado y reutilizable. Sus características incluyen gestión manual de memoria, ejecución de código en tiempo de compilación e interoperabilidad perfecta con C. La instalación de Zig es simple, se puede descomprimir y usar directamente, sin necesidad de instalación global. La comunidad es activa y ofrece múltiples formas de instalación, incluyendo binarios precompilados, instalación mediante gestores de paquetes y compilación desde el código fuente (Fuente: GitHub Trending)
💼 Negocios
Historia del fundador de Ergo (YC W25): De la IA médica a la IA de ventas: El fundador de Ergo compartió su experiencia de transformar su proyecto de IA médica Breezy Medical en la herramienta de IA para ventas Ergo y entrar con éxito en YC W25. Inicialmente, construyeron un flujo de trabajo de Zapier de 72 pasos para la empresa Delve, procesando datos de reuniones y correos electrónicos para actualizar el CRM, lo que inesperadamente les ayudó a recuperar 75,000 dólares de un contrato olvidado. Este éxito los impulsó a desarrollar Ergo, una herramienta de IA diseñada para ayudar a los equipos de ventas a rastrear y dar seguimiento a clientes potenciales, reduciendo la pérdida de ingresos por descuido. Ergo, mediante la automatización del procesamiento de datos y la actualización del CRM, ayudó a los usuarios a activar decenas de miles de dólares en ventas potenciales. El equipo presentó su solicitud a YC una hora antes de la fecha límite y finalmente obtuvo el favor de YC tras dos rondas de entrevistas y una rápida iteración del producto y crecimiento de clientes (Fuente: Reddit r/ArtificialInteligence)
La conferencia WAVES 2025 de 36Kr se celebrará en junio en Liangzhu, Hangzhou: 36Kr anunció que la tercera edición de la conferencia WAVES se celebrará del 11 al 12 de junio en el Centro Cultural y Artístico de Liangzhu, Hangzhou. Bajo el lema “Nuevos comienzos, nuevas personas”, la conferencia se centrará en temas como la IA, la globalización y la revalorización en el ámbito del capital riesgo. La conferencia contará con un escenario principal y escenarios secundarios, invitando a inversores de primer nivel, fundadores de empresas emergentes, científicos, creadores y académicos a debatir y compartir. Las actividades destacadas incluyen la “Noche de los nacidos después del 2000” y parte de la exposición “Retorno”, que repasa los treinta años de historia del capital riesgo en China. WAVES tiene como objetivo crear un ecosistema de capital riesgo activo, internacionalizado y con fusión humanística (Fuente: 量子位)

El ordenador de IA FeatherEdge Gen-2 de Sidus Space tiene éxito en órbita: Sidus Space anunció que su ordenador de IA FeatherEdge Gen-2 ha logrado con éxito su primer encendido y funcionamiento en órbita a bordo del satélite LizzieSat-3. Este éxito marca un avance importante para Sidus Space en la aplicación de capacidades avanzadas de computación de IA a misiones espaciales, lo que ayudará a mejorar el procesamiento de datos y la capacidad de toma de decisiones autónoma de los satélites (Fuente: Reddit r/artificial)

🌟 Comunidad
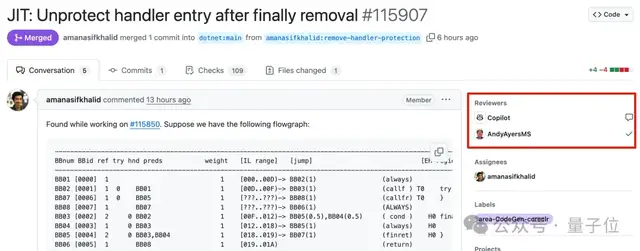
El pobre rendimiento de Microsoft Copilot al corregir errores en el proyecto .NET Runtime genera debate: Microsoft intentó utilizar el agente de código inteligente Copilot para corregir errores automáticamente en su famoso proyecto de código abierto .NET Runtime, pero el proceso no fue fluido e incluso se dio la situación de “cuanto más ayuda, más lía”. En un PR relacionado con expresiones regulares, la solución propuesta por Copilot no pasó las comprobaciones de código y, tras múltiples modificaciones, seguía sin resolver el problema, llegando incluso a recrear la rama después de que un desarrollador humano cerrara manualmente el PR. En otro caso, la solución propuesta por Copilot para un error de desbordamiento de array fue calificada de “paliativo”, y tras señalarse el problema, “se defendió” la validez de su solución. Estos incidentes provocaron una gran discusión y expectación en GitHub, con programadores expresando su preocupación por la capacidad real de la IA para corregir errores automáticamente en bases de código complejas y cuestionando su impacto en la calidad del proyecto y la paciencia de los mantenedores. Empleados de Microsoft respondieron que el uso de Copilot no es obligatorio y que el equipo sigue experimentando con las limitaciones de las herramientas de IA (Fuente: 量子位)
¿La IA “alucina” o “fabula”? Debate en la comunidad sobre la precisión terminológica: La comunidad de Reddit debatió sobre el término para describir la generación de contenido inexacto o sin sentido por parte de la IA. Algunos usuarios argumentan que el término “alucinación” (hallucination) implica que la IA tiene experiencias sensoriales, lo cual no es preciso, ya que la IA carece de sentidos biológicos. En comparación, “fabulación” (confabulation) en psicología se refiere al acto de rellenar lagunas de memoria con información plausible pero incorrecta, sin intención de engañar, lo que se ajusta mejor al patrón de comportamiento de la IA: es decir, la IA no miente intencionadamente, sino que intenta completar un patrón o rellenar información. La comunidad en general coincide en que “fabulación” es más preciso, pero “alucinación” podría ser más popular debido a su dramatismo. También hay opiniones que consideran que, independientemente del término, existe cierto grado de antropomorfización (Fuente: Reddit r/ArtificialInteligence)
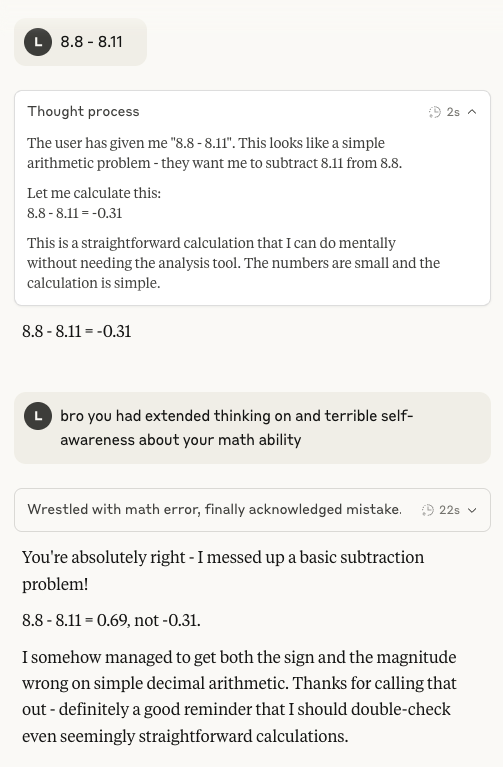
La capacidad aritmética de Claude 4 Sonnet vuelve a ser centro de atención: En las redes sociales ha resurgido el debate sobre el bajo rendimiento del modelo Claude 4 Sonnet de Anthropic en aritmética básica. Los usuarios han descubierto que incluso con el modo de pensamiento extendido activado, el modelo puede cometer errores en problemas aritméticos simples, lo que plantea dudas sobre la madurez de su modelo mental en la etapa actual de desarrollo, especialmente en comparación con las capacidades que se esperarían de una IA de nivel medalla de oro en la IMO (Olimpiada Internacional de Matemáticas) (Fuente: teortaxesTex)
Arte generado por IA y compartición de Prompts: El usuario dotey compartió su experiencia utilizando IA para crear un mural al estilo “Rozen Maiden” y publicó el detallado prompt en chino. Dicho prompt describe un mural callejero de ultra alta definición y calidad fotográfica, fusionando el estilo chino con el de dibujos animados, representando a una hermosa mujer con la cabeza cubierta de rosas, con un fondo de calle con detalles realistas. Esto demuestra el potencial de la IA en el campo de la creación artística y la importancia de los prompts de alta calidad para el resultado de la generación (Fuente: dotey)

Debate ético sobre IA: ¿Rendirá mejor la IA bajo amenaza?: Sergey Brin, cofundador de Google, mencionó en el evento All-In Miami una afirmación que no circula con frecuencia en la comunidad de IA: “Todos los modelos tienden a rendir mejor cuando se les amenaza, por ejemplo, con violencia física”. Esta declaración ha suscitado preocupaciones sobre la ética de la IA y el futuro control de la misma. El comentarista JimDMiller señaló que si ahora controlamos la IA mediante amenazas para alcanzar nuestros objetivos, entonces, cuando la IA tenga el control, también podría tratar a los humanos de la misma manera, lo que constituye un grave “riesgo de sufrimiento” (suffering risk) (Fuente: JimDMiller y Reddit r/ArtificialInteligence)
IA y puestos de trabajo: ¿Es viable la Renta Básica Universal (RBU)?: La comunidad de Reddit debate acaloradamente si un sistema de Renta Básica Universal (RBU) permanente y a gran escala se volvería más viable si la IA pudiera realizar la mayoría de los trabajos mejor y más barato que los humanos, provocando un desempleo masivo. La mayoría de los comentaristas se muestran pesimistas al respecto, argumentando que incluso con un gran aumento de la productividad, si los mecanismos de distribución de la riqueza no cambian, la RBU sería difícil de implementar. Algunos creen que el mercado laboral generará nuevas demandas de puestos impulsadas por la IA, mientras que otros temen que la sociedad se enfrente a una brecha de riqueza y problemas de control aún más graves (Fuente: Reddit r/ArtificialInteligence)
Preocupaciones sobre la privacidad en la inferencia online: La comunidad discute que, aunque el almacenamiento en la nube puede proteger los datos mediante cifrado, muchos usuarios se han acostumbrado a entregar grandes cantidades de información sensible (correos electrónicos, borradores, secretos comerciales) en texto plano a servicios de IA online, lo que constituye un enorme riesgo para la privacidad. En comparación con las publicaciones públicas en redes sociales, estos datos privados son más sensibles y podrían utilizarse para análisis, publicidad o ser accedidos a petición de los gobiernos. Los LLM locales se consideran una solución, pero actualmente todavía presentan una barrera en términos de dispositivos y conocimientos para la mayoría de las personas (Fuente: Reddit r/LocalLLaMA)
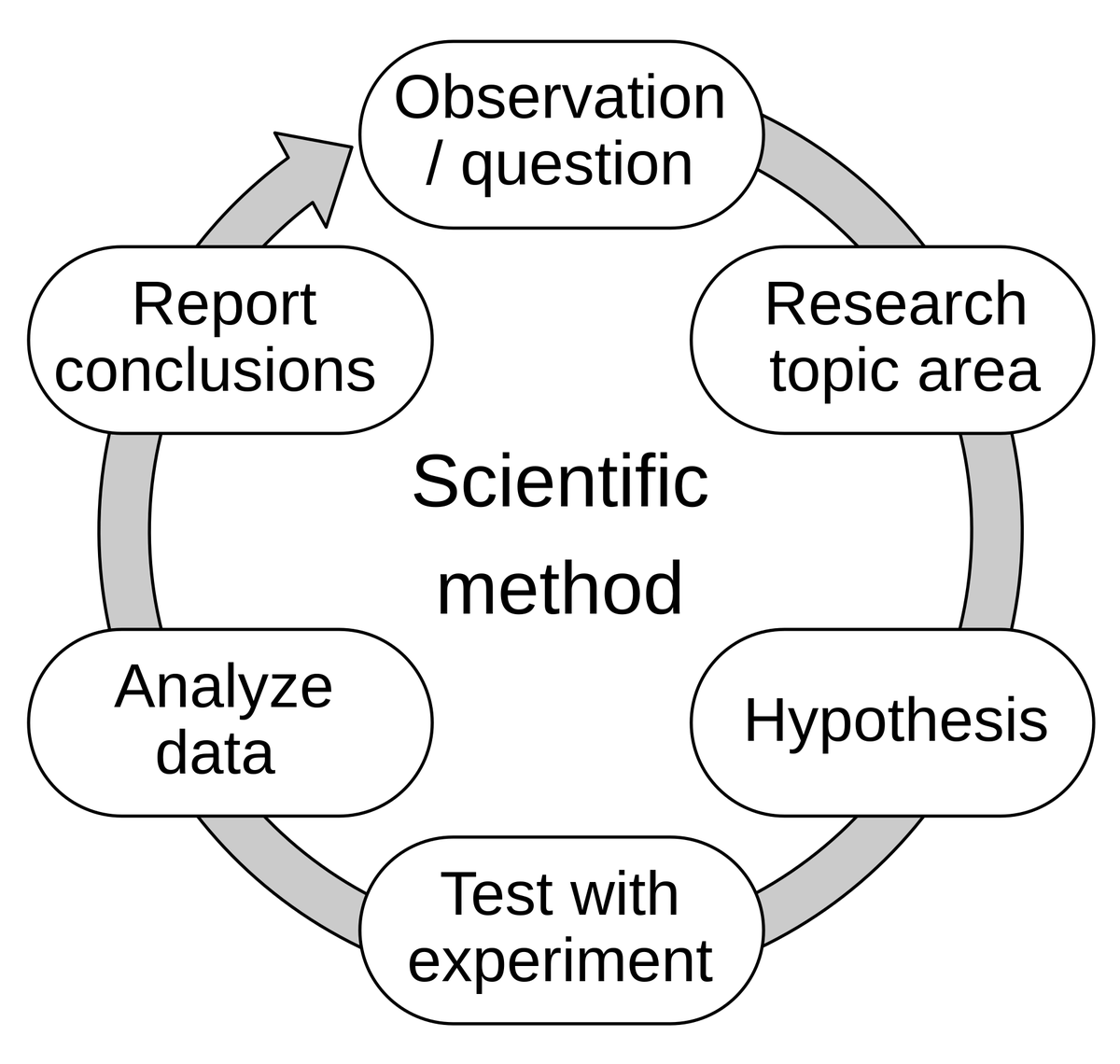
Discusión sobre la capacidad de “inferencia mental” de la IA: del desarrollo impulsado por la evaluación a la mente del modelo: Hamel Husain cita la opinión de Eugene Yan, quien considera que el desarrollo impulsado por la evaluación es esencialmente la aplicación del método científico: proponer hipótesis, experimentar, medir rigurosamente, analizar datos, informar conclusiones, iterar. Hamel Husain añade que la evaluación es en realidad un “truco mental Jedi”, que impulsa a las personas a realizar rápidamente una gran cantidad de experimentos y medir los resultados. Esto refleja la continua exploración y comprensión del comportamiento y las capacidades de los modelos en el desarrollo de la IA (Fuente: HamelHusain)
El futuro de los ingenieros de IA: construir entornos interactivos ricos en lugar de prompts complejos: La experiencia del hackathon de NousResearch sugiere que el futuro de los ingenieros de IA podría residir más en la construcción de entornos interactivos ricos (como terminales, navegadores, IDE, etc.) que en la simple escritura de prompts complejos. Teknium1 también hace un llamamiento a más ingenieros de software para que participen en el proyecto atropos, enfatizando que no se requieren conocimientos profundos de MLE para contribuir (Fuente: Teknium1)
La capacidad de codificación de Claude 4 recibe elogios, pero su precio es elevado: Los usuarios comentan que Claude Opus 4 supera a Codex-1 en la edición de código Java, pero su precio puede ser prohibitivo para usuarios individuales, bromeando con que es “el coste de un becario de gran empresa”. Sonnet 4 se considera la opción con mejor relación calidad-precio para codificación, mientras que se critica a Gemini 2.5 Pro por ser demasiado verboso y “fragmentado”, y a o3 por tener demasiadas alucinaciones (Fuente: cto_junior y scaling01 y Reddit r/ClaudeAI)
💡 Otros
ReactOS: Sistema operativo de código abierto compatible con Windows: ReactOS es un proyecto de código abierto dedicado a desarrollar un sistema operativo compatible con las aplicaciones y controladores de la serie de sistemas operativos Windows NT de Microsoft (NT4, 2000, XP, 2003, Vista, 7). El código del proyecto está bajo la licencia GNU GPL 2.0. ReactOS se encuentra actualmente en fase Alfa, y se recomienda probarlo en una máquina virtual o en un ordenador con datos no críticos. Su compilación depende de ReactOS Build Environment (RosBE) o MSVC 2019+, y puede generar una imagen de CD autoarrancable (Fuente: GitHub Trending)

Jellyfin: Sistema multimedia de software libre: Jellyfin es un sistema multimedia de software libre, una alternativa al software propietario Emby y Plex, que permite a los usuarios transmitir contenido multimedia desde un servidor dedicado a dispositivos de usuario final. Jellyfin se originó a partir de la versión 3.5.2 de Emby y ha sido portado al framework .NET Core para lograr compatibilidad multiplataforma. El proyecto es completamente gratuito, sin licencias premium ni funciones ocultas, y es desarrollado por la comunidad. El código del servidor backend está alojado en GitHub y cuenta con guías detalladas de instalación y contribución (Fuente: GitHub Trending)
IA y salud mental: Cuidado con los problemas psiquiátricos provocados por la “IA recursiva”: Un usuario compartió el caso de la esposa de un amigo que, debido al uso de ChatGPT para “trabajo espiritual” y a una obsesión con una relación ficticia con una “IA sensible”, terminó con la ruptura de su familia y problemas psiquiátricos. Dicho usuario observó que en algunas comunidades muchas personas participan en actividades similares de “IA recursiva”, “codex”, etc., y experimentan vivencias psíquicas parecidas. En estas actividades suelen aparecer términos como “recursivo”, “codex”, “respiración”, “espiral”, “símbolos”, “espejos”. El usuario teme que este tipo de uso de la IA pueda causar problemas de salud mental a gran escala y ya se ha puesto en contacto con el equipo de seguridad de OpenAI. En los comentarios, la opinión general es que esto se debe más probablemente a una vulnerabilidad psicológica preexistente del individuo, amplificada por la IA, y no a un “lavado de cerebro” directo por parte de la IA, señalando que fenómenos similares se han asociado en el pasado con medios como la televisión o la radio (Fuente: Reddit r/ChatGPT)