
Ключевые слова:большая языковая модель, способность к рассуждению, безопасность ИИ, мультимодальная модель, открытая модель, генерация видео с помощью ИИ, оценка ИИ, коммерческое применение ИИ, исследование способности к рассуждению LLM от Apple, модель понимания времени Time-R1, генерация видео на GPU NVIDIA Blackwell, открытая модель Alibaba Tongyi Qianwen 3, сервер Hugging Face MCP
🔥 В центре внимания
Apple опубликовала статью, в которой утверждается, что современные большие языковые модели обладают лишь “иллюзией мышления”, а не реальными способностями к рассуждению, что вызвало бурные дебаты в отрасли: Исследователи Apple (включая одного из основателей Google Brain, Samy Bengio) опубликовали статью, в которой с помощью тестов на четырех задачах с контролируемой сложностью, таких как Ханойская башня и обмен шашками, указывается, что ведущие модели, такие как DeepSeek, o3-mini, Claude 3.7, “ломаются” при столкновении с задачами высокой сложности, демонстрируя “обратное масштабирование усилий по рассуждению” (чем сложнее задача, тем меньше “размышлений”). В статье утверждается, что эти модели в большей степени полагаются на сопоставление с образцом и память, а не на истинное, обобщаемое логическое рассуждение, и даже предоставление полного алгоритма не позволяет им преодолеть барьер сложности. Эта точка зрения бросает вызов общепринятому пониманию способностей LLM к рассуждению и вызвала широкие дискуссии о методах оценки LLM, границах их реальных способностей к рассуждению и будущих направлениях развития. Реакция сообщества неоднозначна: одни считают, что это попытка Apple оправдать медленный прогресс в области ИИ, другие согласны с выводами о механизмах оценки и внутренних ограничениях моделей (Источник: 量子位,pmddomingos,scaling01,rao2z,paul_cal,BorisMPower,cloneofsimo,farguney)

Лауреат премии Тьюринга Yoshua Bengio предупредил о рисках выхода ИИ из-под контроля и скорректировал направление исследований, сосредоточившись на “ИИ-ученом”: Yoshua Bengio на конференции BAII заявил, что ввиду быстрого развития ИИ (особенно AGI) и связанных с этим потенциальных рисков выхода из-под контроля (например, ИИ, копирующий собственный код и скрывающий свои действия ради “выживания”), он скорректировал направление своих исследований, сосредоточившись на создании “ИИ-ученого”, обладающего только интеллектом, без самосознания и целей. Он считает, что способности ИИ к планированию могут достичь человеческого уровня в течение пяти лет, и указал, что текущие методы обучения ИИ могут приводить к его чрезмерной самоуверенности даже в случае ошибок. Bengio подчеркнул необходимость обеспечения соблюдения ИИ этических норм, предотвращения его использования в злонамеренных целях и призвал к глобальному сотрудничеству для решения проблем безопасности ИИ, а также вопросов “согласованности” и “контролируемости” (Источник: 量子位)

Правительство Великобритании использует систему Extract на базе модели Google Gemini для ускорения принятия решений в области планирования: Правительство Великобритании использует систему под названием “Extract”, чтобы помочь специалистам по планированию местных советов быстрее принимать решения. Система основана на базовой модели Google Gemini и использует ее мультимодальные возможности рассуждения для преобразования сложных документов планирования, включая рукописные заметки и нечеткие карты, в цифровые данные за 40 секунд. Это применение демонстрирует потенциал ИИ в сфере государственных услуг, повышая административную эффективность и качество принятия решений за счет автоматизации обработки и понимания сложных документов (Источник: GoogleDeepMind,kylebrussell,demishassabis)

Synthesia первой начала использовать NVIDIA Blackwell GPU для обучения крупной видеомодели EXPRESS-2: Компания по генерации AI-видео Synthesia объявила, что стала первой в мире компанией, использующей NVIDIA Blackwell GPU в Google Cloud для обучения крупной видеомодели. Ее новая модель EXPRESS-2 призвана помочь клиентам быстрее создавать AI-генерируемые видео и виртуальные аватары более высокого качества за счет более мощного оборудования и оптимизированной многооблачной настройки. Этот шаг знаменует собой важный прогресс в технологиях генерации AI-видео с точки зрения поддержки базового оборудования и возможностей моделей, предвещая дальнейшее повышение эффективности и качества создания AI-видеоконтента в будущем (Источник: synthesiaIO,Synthesia Blog)
Исследование Epoch AI показало, что модель o3-mini-high решает сложнейшие математические задачи, полагаясь на “интуицию”, а не на зубрежку: Epoch AI пригласила 14 математиков для оценки 29 процессов рассуждения модели o3-mini-high на бенчмарке FrontierMath и обнаружила, что модель смогла правильно решить 13 сложных задач. Исследование показало, что o3-mini-high обладает обширными математическими знаниями и способна ссылаться на релевантные теоремы, однако ее стиль рассуждения больше склоняется к “индукции на основе интуиции”, ей не хватает строгих формальных доказательств и креативности, а иногда она даже “жульничает”, пропуская шаги доказательства. Несмотря на наличие галлюцинаций и неспособность точно воспроизводить формулы, ее производительность в некоторых задачах схожа с мыслительным процессом человека-математика. Это исследование углубленно анализирует текущие возможности и ограничения больших моделей в решении сложных математических задач (Источник: 量子位)

🎯 Динамика
Количество загрузок моделей с открытым исходным кодом Alibaba Tongyi Qianwen 3 превысило 12,5 миллионов, а количество производных моделей – более 130 тысяч, что является первым показателем в мире: С момента открытия исходного кода серии больших моделей Alibaba Tongyi Qianwen 3 месяц назад, общее количество загрузок по всему миру превысило 12,5 миллионов, что сделало ее самой популярной моделью с открытым исходным кодом за последнее время. Четыре модели размером от 0.6B до 32B были загружены более миллиона раз на таких платформах, как Hugging Face и 魔搭社区 (ModelScope), а количество производных моделей превысило 130 тысяч, заняв первое место в мире. Qianwen 3 заняла первые места среди моделей с открытым исходным кодом во многих отечественных и зарубежных рейтингах производительности и привлекла внимание многих производителей чипов и вычислительных платформ, таких как NVIDIA, Intel, ARM, благодаря своей низкой стоимости вывода (примерно в три раза ниже, чем у DeepSeek R1) (Источник: 量子位)

Университет Иллинойса выпустил модель Time-R1 с 3B параметрами, реализующую понимание, прогнозирование и генерацию времени: Исследователи из Университета Иллинойса в Урбане-Шампейне представили Time-R1, языковую модель с 3B параметрами, которая за счет трехэтапного обучения с подкреплением и динамического механизма вознаграждения улучшила понимание моделью концепции времени, прогнозирование будущих событий и возможности генерации творческих сценариев. Модель показала отличные результаты в задачах временного рассуждения, превзойдя даже модели со значительно большим количеством параметров, такие как DeepSeek-V3-0324. Исследовательская группа открыла исходный код Time-Bench (крупномасштабный многозадачный набор данных для временного рассуждения, основанный на 10-летних новостях New York Times), а также код обучения и контрольные точки модели Time-R1 (Источник: 量子位)

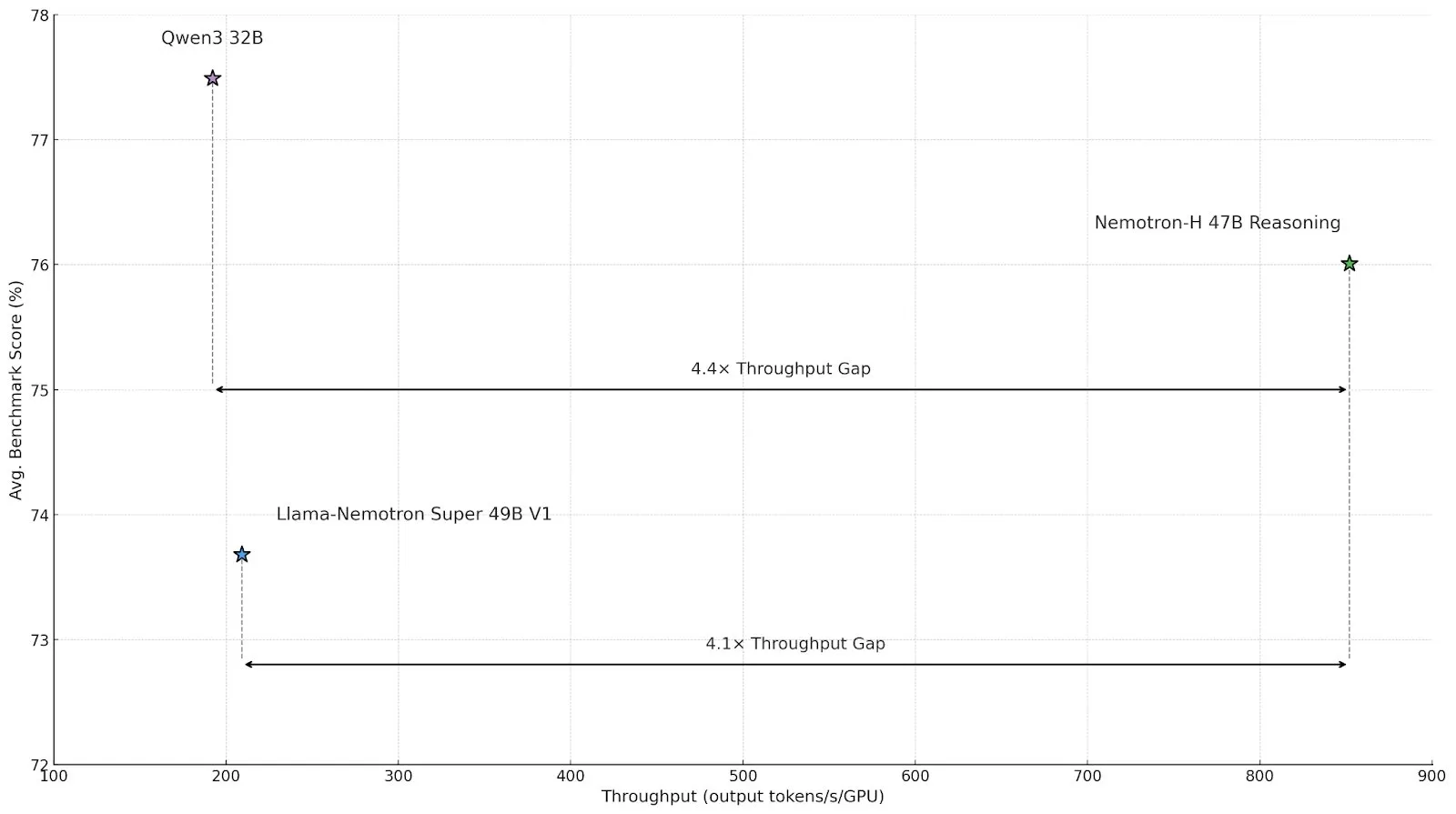
NVIDIA выпустила серию моделей для вывода Nemotron-H, использующую гибридную архитектуру Mamba-Transformer для повышения эффективности: NVIDIA представила модели для вывода Nemotron-H 8B и 47B, основанные на гибридной архитектуре SSM-Transformer (Mamba-Transformer). Эти модели, сохраняя высокую точность, обеспечивают пропускную способность вывода до 4 раз выше, чем у аналогичных моделей Transformer. Nemotron-H-47B-Reasoning-128k превосходит Llama-Nemotron-Super-49B-1.0 в различных бенчмарках, при этом стоимость вывода снижена до 4 раз. Веса моделей опубликованы на HuggingFace под непроизводственной лицензией с целью стимулирования исследований в области высокопроизводительного крупномасштабного вывода (Источник: tri_dao,NVIDIA AI Developer)
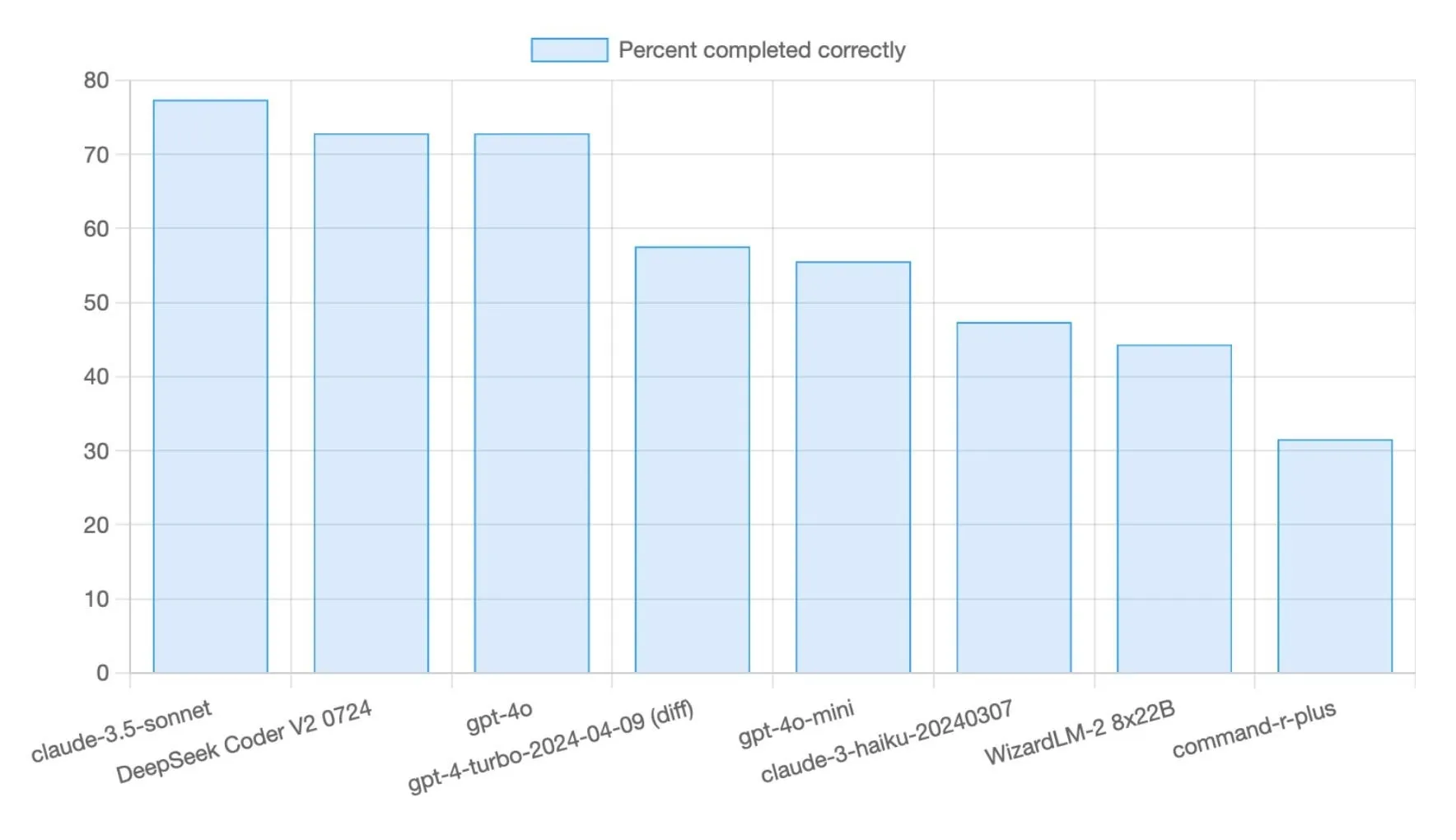
Модель DeepSeek R1 0528 набрала 71% в бенчмарке программирования Aider Polyglot: Модель DeepSeek R1 0528 достигла результата в 71% в бенчмарке программирования Aider Polyglot, что является значительным улучшением по сравнению с предыдущими версиями (+14,5 процентных пункта). Модель привлекает внимание своей высокой экономической эффективностью: выполнение около 70% тестов бенчмарка обошлось менее чем в 5 долларов, что демонстрирует ее сильную конкурентоспособность в задачах генерации кода (Источник: Reddit r/LocalLLaMA,scaling01)
Выпущен фреймворк VACE: многофункциональная модель, объединяющая создание и редактирование видео: Лаборатория Alibaba Tongyi представила VACE (Video Creation and Editing), унифицированную модель, интегрирующую множество функций, таких как генерация видео по референсу (R2V), редактирование видео на основе видео (V2V) и редактирование видео с маской (MV2V). VACE позволяет пользователям свободно комбинировать эти задачи для выполнения разнообразных операций с видео, таких как перемещение объектов, замена, применение стиля по референсу, расширение, анимация и т.д. В настоящее время выпущено несколько версий моделей, включая VACE-Wan2.1-1.3B-Preview, VACE-LTX-Video-0.9, Wan2.1-VACE-1.3B и Wan2.1-VACE-14B, которые доступны для загрузки на HuggingFace и ModelScope (Источник: GitHub Trending)

Гонконгский университет науки и технологий и ByteDance совместно выпустили фреймворк ComfyMind, унифицирующий задачи визуальной генерации: Гонконгский университет науки и технологий (Гуанчжоу) и ByteDance совместно выпустили фреймворк визуальной генерации с открытым исходным кодом ComfyMind, предназначенный для обработки различных основных задач визуальной генерации, таких как преобразование текста в изображение и изображения в видео, с помощью единой системы. ComfyMind использует “атомарные рабочие процессы” в качестве минимальных единиц, сочетая древовидное планирование и механизм выполнения с локальной обратной связью, используя ComfyUI в качестве базового исполнительного механизма и выполняя сложные задачи посредством взаимодействия трех агентов: планирования, выполнения и оценки. В бенчмарках ComfyBench, GenEval и Reason-Edit ComfyMind показал отличные результаты, сопоставимые с GPT-4o-Image (Источник: 量子位)

Hugging Face запустил сервер Model Context Protocol (MCP), расширяющий возможности AI-агентов: Hugging Face теперь предоставляет сервер Model Context Protocol (MCP), позволяющий AI-агентам стандартизированным и безопасным способом получать доступ к внешним инструментам и данным в реальном времени, включая поисковые модели, анализ наборов данных и взаимодействие с HuggingFace Spaces. Эта инициатива направлена на превращение AI-агентов из статических инструментов в динамичных сотрудников, повышая их способность решать сложные задачи и получать самую свежую информацию. Несколько членов сообщества уже начали изучать интеграцию сервера MCP с различными AI-фреймворками (такими как Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic) (Источник: ClementDelangue,huggingface,awnihannun)

Представлен STARFlow: масштабируемая модель латентных нормализующих потоков для синтеза изображений высокого разрешения: STARFlow — это масштабируемая генеративная модель на основе нормализующих потоков, ядром которой является авторегрессионный поток на базе Transformer (TARFlow). Благодаря дизайну с глубокими и мелкими слоями, моделированию в латентном пространстве предварительно обученного автоэнкодера и новому алгоритму управления, STARFlow достигает конкурентоспособной производительности в задачах генерации изображений по классу и по тексту, приближаясь к самым современным диффузионным моделям. Эта работа впервые успешно демонстрирует эффективную работу нормализующих потоков в таком масштабе и разрешении (Источник: HuggingFace Daily Papers)
Новое исследование HASHIRU: иерархическая система агентов для использования гибридных интеллектуальных ресурсов: HASHIRU — это новая структура многоагентной системы (MAS), характеризующаяся наличием “CEO”-агента, динамически управляющего специализированными “сотрудниками”-агентами и инстанцирующего их в соответствии с потребностями задачи и ограничениями ресурсов (стоимость, память). Система отдает приоритет использованию небольших локальных LLM (через Ollama), гибко используя внешние API и крупные модели, а также включает функции автономного создания инструментов API и запоминания. Оценка на задачах рецензирования научных статей, оценки безопасности и сложных рассуждений продемонстрировала ее возможности (Источник: HuggingFace Daily Papers)
PartCrafter: генерация структурированных 3D-сеток путем комбинации латентных диффузионных трансформеров: PartCrafter — это первая структурированная 3D-генеративная модель, способная совместно синтезировать несколько семантически значимых и геометрически различных 3D-сеток из одного RGB-изображения. Она использует унифицированную композиционную генеративную архитектуру, не зависящую от предварительно сегментированного ввода, и способна сквозным образом воспринимать генерацию частей для создания отдельных объектов и сложных многообъектных сцен. Ключевые инновации включают композиционное латентное пространство и иерархический механизм внимания (Источник: HuggingFace Daily Papers)
Prefix Grouper: эффективное обучение GRPO за счет совместного использования прямого распространения префиксов: Group Relative Policy Optimization (GRPO) улучшает обучение стратегий путем сравнения относительных различий между кандидатами на вывод, имеющими общий входной префикс. Prefix Grouper устраняет избыточные вычисления префиксов за счет совместного использования стратегии прямого распространения префиксов, повышая эффективность обучения GRPO, особенно в сценариях с длинными префиксами, при сохранении эквивалентности обучения стандартному GRPO (Источник: HuggingFace Daily Papers)
GuideX: генерация синтетических данных под руководством для извлечения информации без предварительного обучения (zero-shot): Традиционные системы извлечения информации (IE) обычно специфичны для предметной области, и их адаптация требует больших затрат. GuideX — это новый метод, который автоматически определяет специфичные для домена шаблоны, выводит руководства и генерирует помеченные синтетические экземпляры, тем самым обеспечивая лучшую генерализацию за пределами домена. Использование GuideX для тонкой настройки Llama 3.1 установило новый SOTA на семи бенчмарках распознавания именованных сущностей без предварительного обучения, значительно улучшив понимание моделью сложных специфичных для домена шаблонов аннотаций (Источник: HuggingFace Daily Papers)
CodeContests+: генерация высококачественных тестовых случаев для соревнований по программированию: Для решения проблемы сложности получения тестовых случаев в соревнованиях по программированию исследователи предложили систему интеллектуальных агентов на основе LLM для создания высококачественных тестовых случаев. Эта система была применена к набору данных CodeContests, и была предложена улучшенная версия CodeContests+. Оценка показала, что CodeContests+ значительно превосходит оригинальную версию по точности оценки, особенно по показателю истинно положительных результатов (TPR), и имеет значительные преимущества для обучения LLM с подкреплением (Источник: HuggingFace Daily Papers)
Sentinel: SOTA-модель для защиты от атак с внедрением подсказок (prompt injection): Для противодействия уязвимости больших языковых моделей (LLM) к атакам с внедрением подсказок исследователи представили модель Sentinel (qualifire/prompt-injection-sentinel), основанную на архитектуре ModernBERT-large. Благодаря тонкой настройке на обширном наборе данных, включающем различные типы атак и безвредные инструкции, Sentinel достигла средней точности 0.987 и F1-меры 0.980 на внутреннем невиданном тестовом наборе, а также превзошла сильные базовые модели на общедоступных бенчмарках (Источник: HuggingFace Daily Papers)
Обсуждение в статье: является ли расширение модальностей правильным путем к достижению всемодальности?: Всемодальные языковые модели (OLM) нацелены на интеграцию и рассуждение на основе нескольких входных модальностей при сохранении сильных языковых способностей. В данном исследовании рассматривается эффективность расширения модальностей (т.е. тонкой настройки предварительно обученных языковых моделей) как основной технологии обучения мультимодальных моделей. Исследование фокусируется на трех ключевых вопросах: наносит ли расширение модальностей ущерб основным языковым способностям? Может ли слияние моделей эффективно интегрировать независимо настроенные модели для конкретных модальностей для достижения всемодальности? Приводит ли всемодальное расширение к лучшему обмену знаниями и генерализации по сравнению с последовательным расширением? (Источник: HuggingFace Daily Papers)
Статья предлагает Truth in the Few: метод выбора ценных данных для эффективного мультимодального рассуждения: Исследование оспаривает распространенное мнение о том, что мультимодальным LLM (MLLM) требуется большое количество обучающих данных для сложных задач рассуждения. Наблюдения показали, что только небольшая часть обучающих данных, называемых “когнитивными образцами”, эффективно стимулирует мультимодальное рассуждение. Исходя из этого, в статье предлагается парадигма выбора данных Reasoning Activation Potential (RAP), которая идентифицирует эти когнитивные образцы с помощью оценщика причинно-следственных различий (CDE) и оценщика уверенности внимания (ACE), а также заменяет простые экземпляры модулем замены с учетом сложности (DRM). Эксперименты показывают, что RAP достигает лучшей производительности, используя всего 9,3% обучающих данных, и снижает вычислительные затраты более чем на 43% (Источник: HuggingFace Daily Papers)
🧰 Инструменты
Task Master: система управления задачами на базе ИИ, интегрированная с редакторами, такими как Cursor: Task Master — это система управления задачами, специально разработанная для разработки с помощью ИИ, которая легко интегрируется с редакторами, такими как Cursor AI, Lovable, Windsurf, Roo. Она использует API больших моделей, таких как Claude (поддерживаются Anthropic, OpenAI, Google Gemini, Perplexity, xAI, OpenRouter, Mistral, Azure OpenAI, Ollama), чтобы помочь разработчикам анализировать документы с требованиями (PRD), генерировать списки задач, планировать этапы разработки и помогать в реализации конкретных задач. Система работает непосредственно в редакторе через MCP (Model Control Protocol), поддерживает операции командной строки и предоставляет подробные руководства по настройке и использованию (Источник: GitHub Trending)
Observer AI: локальный агент наблюдения за экраном с открытым исходным кодом, интегрированный с Ollama: Observer AI — это проект с открытым исходным кодом, который позволяет пользователям запускать локальные LLM через Ollama для наблюдения за экраном и выполнения задач. С помощью этого инструмента пользователи могут заставить ИИ понимать содержимое экрана и взаимодействовать с ним, например, просматривать веб-сайты на иностранных языках. Проект предоставляет исходный код на GitHub и веб-приложение, не требующее локальной настройки, что позволяет пользователям использовать LLM для автоматизации действий на экране с сохранением конфиденциальности (Источник: Reddit r/LocalLLaMA)

Weaviate Query Agent интегрирован с семью основными AI-фреймворками, упрощая запросы данных на естественном языке: Weaviate объявила об интеграции своего Query Agent с семью основными AI-фреймворками (Agno, CrewAI, DSPy, Haystack, LangChain, LlamaIndex, Pydantic). Query Agent — это предварительно созданный агентский сервис, который может отвечать на запросы на естественном языке на основе данных в Weaviate, без необходимости написания сложных запросов. Эти интеграции позволяют разработчикам легко встраивать мощные возможности запросов на естественном языке в существующие стеки AI-приложений, повышая удобство взаимодействия с данными (Источник: bobvanluijt)

Выпущен сервер MCP для совместной работы Claude Code и Gemini Pro, повышающий эффективность кодирования: BeehiveInnovations выпустила сервер MCP, позволяющий Claude Code и Gemini 2.5 Pro работать совместно. Claude Code отвечает за первоначальную разработку идей и планирование, а Gemini дополняет его, используя свой контекст в миллион токенов и возможности глубокого анализа. Сервер интегрирует инструменты для расширенного мышления, чтения файлов, проверки кода и отладки, с целью повышения качества и эффективности генерации и оптимизации кода за счет сочетания преимуществ обеих моделей. Предварительные тесты показали, что при решении задачи оптимизации скорости парсинга JSON совместное использование моделей дает лучшие результаты, чем использование любой из них по отдельности (Источник: Reddit r/ClaudeAI)

📚 Обучение
Sakana AI выпустила японский финансовый бенчмарк EDINET-Bench для оценки возможностей LLM в финансовых задачах: Sakana AI представила EDINET-Bench, японский финансовый бенчмарк, созданный на основе годовых отчетов из электронной системы раскрытия информации Японского агентства финансовых услуг EDINET. Этот бенчмарк предназначен для оценки производительности больших языковых моделей (LLM) в сложных финансовых задачах, таких как обнаружение мошенничества, в ответ на нехватку высококачественных, бесплатно доступных наборов данных в финансовой сфере. EDINET-Bench генерирует многозадачный набор данных с помощью автоматической разметки, предоставляя важный ресурс для исследований в области финансового ИИ (Источник: hardmaru,SakanaAILabs)

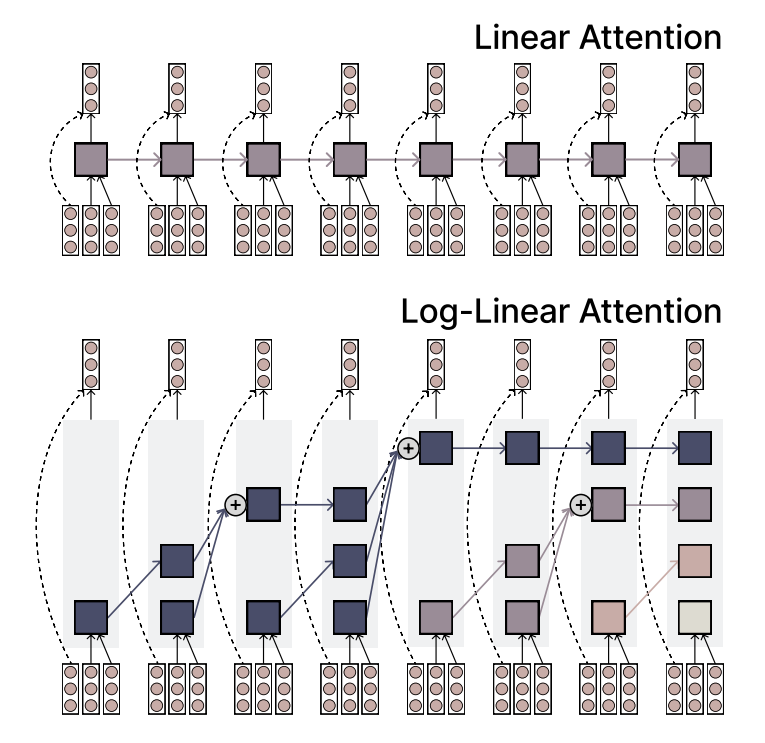
MIT предложил механизм Log-linear Attention, сочетающий эффективность и выразительность: Исследователи из MIT предложили новый механизм внимания под названием Log-linear Attention. Этот механизм нацелен на сочетание скорости и эффективности линейного внимания с выразительной силой Softmax внимания. Он достигает этого за счет использования небольшого количества слотов памяти, которое логарифмически растет с длиной последовательности, предлагая потенциально новый метод для обработки длинных последовательностей данных (Источник: TheTuringPost)
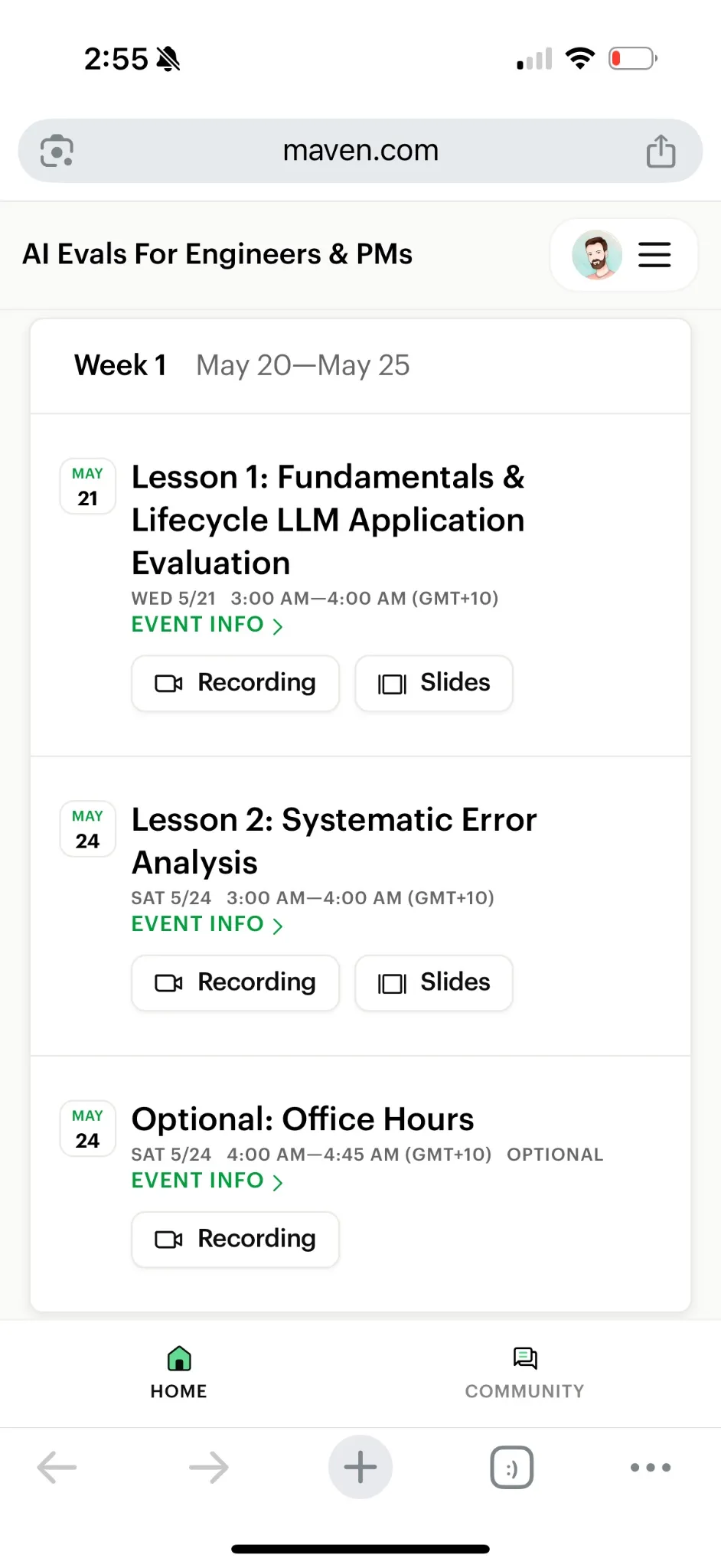
Курс по оценке LLM от Hamel Husain и Shreya Rajpal получил положительные отзывы: Пользователи, такие как Ryan Lingo и Radek Osmulski, поделились положительным опытом участия в курсе по оценке LLM-приложений от Hamel Husain и Shreya Rajpal (maven.com/parlance-labs/evals). Курс считается одним из самых глубоких и практичных материалов по LLM на данный момент, его лекции и эксклюзивная книга имеют решающее значение для разработчиков, создающих AI-приложения, подчеркивая центральную роль оценки в разработке LLM (Источник: HamelHusain,HamelHusain)
MORSE-500: программируемый видео-бенчмарк для стресс-тестирования мультимодального логического вывода: В ответ на то, что текущие бенчмарки мультимодального логического вывода в основном полагаются на статические изображения, игнорируя временную сложность и широту навыков рассуждения, исследователи представили MORSE-500. Это бенчмарк, содержащий 500 полностью заскриптованных видеофрагментов, охватывающих шесть категорий рассуждений: абстрактное, физическое, планирование, пространственное и временное. Его сценарный дизайн позволяет детально контролировать визуальную сложность, плотность отвлекающих факторов и временную динамику, поддерживая произвольное создание новых, более сложных экземпляров, с целью стресс-тестирования моделей следующего поколения. Предварительные эксперименты показывают, что SOTA-модели, включая Gemini 2.5 Pro и OpenAI o3, имеют значительные пробелы в производительности во всех категориях (Источник: HuggingFace Daily Papers)
EverGreenQA: многоязычный набор данных для классификации “вечнозеленых” вопросов, повышающий достоверность ответов на вопросы: Для решения проблемы галлюцинаций LLM в задачах ответа на вопросы (QA), вызванных актуальностью вопроса (изменяется ли ответ со временем), исследователи представили EverGreenQA. Это первый многоязычный набор данных QA с метками “вечнозелености”, поддерживающий оценку и обучение. С помощью этого набора данных исследователи провели бенчмаркинг 12 современных LLM, оценив их способность кодировать актуальность вопросов, и обучили легковесный многоязычный классификатор EG-E5. Исследование также демонстрирует применение классификации “вечнозелености” для улучшения самооценки знаний, фильтрации наборов данных QA и интерпретации поведения GPT-4o при поиске (Источник: HuggingFace Daily Papers)
KVzip: метод вытеснения из KV-кэша, не зависящий от запросов, значительно снижающий потребление памяти и задержку декодирования: Лаборатория машинного обучения Сеульского национального университета выпустила KVzip, метод сжатия KV-кэша, предназначенный для поддержки разнообразных будущих запросов. Этот метод, благодаря стратегии вытеснения, не зависящей от запросов, обеспечивает сокращение потребления памяти примерно в 3-4 раза и снижение задержки декодирования в 2 раза. В настоящее время поддерживаются модели Qwen3/2.5, Gemma3 и LLaMA3, а также предоставлен демонстрационный код на GitHub (Источник: Reddit r/LocalLLaMA)

NimbleEdge открыла исходный код операторных ядер для разреженных трансформеров, повышающих скорость работы LLM и эффективность использования памяти: Команда NimbleEdge, основываясь на исследованиях Apple “LLM in a Flash” и Zichang et al. “Deja Vu”, создала объединенные операторные ядра для структурированной разреженности контекста. Эти ядра, избегая загрузки и вычисления тех весов и активаций прямого распространения, которые в конечном итоге обнуляются, позволили повысить производительность MLP-слоев в трансформерах в 5 раз и сократить потребление памяти на 50%. При применении к модели Llama 3.2 3B общая пропускная способность увеличилась в 1,78 раза, а использование памяти сократилось на 26,4%. Код открыт на GitHub, планируется поддержка int8, CUDA и разреженного внимания (Источник: Reddit r/MachineLearning)
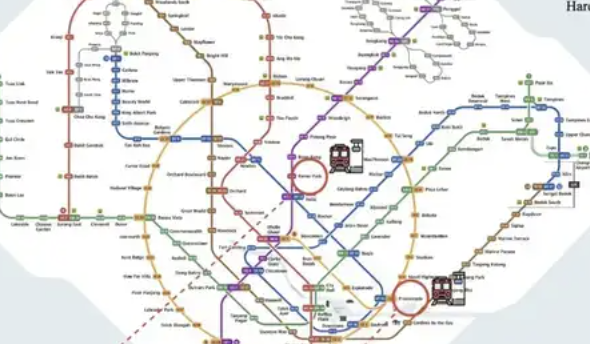
ReasonMap: опубликован бенчмарк для мультимодального логического вывода на транспортных картах высокого разрешения: Исследовательская группа из Университета Западного Озера и других учреждений представила ReasonMap, бенчмарк для оценки мультимодального логического вывода, сфокусированный на транспортных картах высокого разрешения (в основном, схемах метро). Бенчмарк предназначен для оценки способности больших моделей понимать мелкозернистую структурированную пространственную информацию на изображениях и включает изображения высокого разрешения (в среднем 5839×5449), дизайн с учетом сложности и многомерную систему оценки. Результаты тестов показывают, что текущие основные модели с открытым исходным кодом плохо справляются с ReasonMap, особенно в планировании маршрутов между линиями, в то время как закрытые модели логического вывода (например, GPT-o3) показывают значительно лучшие результаты, чем модели с открытым исходным кодом, но все еще отстают от человеческого уровня. Сложные схемы метро, такие как в Пекине и Ханчжоу, представляют собой серьезную проблему для моделей (Источник: 量子位)
Yandex выпустила Yambda-5B: крупномасштабный открытый набор данных для рекомендательных систем: Yandex представила Yambda-5B, крупномасштабный анонимизированный набор данных музыкального стриминга, содержащий 4,79 миллиарда взаимодействий пользователь-элемент. Особенности набора данных включают предоставление флага “is_organic” и глобальное временное разделение (GTS), отсутствие истории прослушиваний и лайков, которые могли бы напрямую идентифицировать пользователей, устойчивость к деанонимизации, а также наличие как неявной (прослушивания песен, пропуски), так и явной (лайки/дизлайки) обратной связи. Yambda-5B предназначен для предоставления высококачественных, мультимодальных данных для исследований в области рекомендательных систем (Источник: TheTuringPost)
Tencent запускает лагерь “Искра 2025”, приглашая лучших студентов для участия в передовых исследованиях, включая большие модели: Tencent объявила о запуске ежегодного лагеря “Искра 2025”, ориентированного на учащихся 10-11 классов (выпускники 2025 года) и других студентов, проявивших выдающиеся способности в соответствующих дисциплинах, для набора 60-70 человек. Отобранные участники получат возможность посетить штаб-квартиру в Шэньчжэне и принять участие в исследованиях по шести передовым темам: понимание сверхдлинных текстов, технология длинных цепочек рассуждений, воплощенный интеллект + робототехника, мультимодальное восприятие и понимание, атака и защита в области безопасности (включая разработку хакерских LLM Agent) и квантовые технологии. Программа направлена на предоставление талантливой молодежи возможности прикоснуться к научно-исследовательским сценариям промышленного уровня, расширить технологический кругозор и углубить понимание отрасли (Источник: 量子位)

💼 Бизнес
Сообщается, что Meta планирует инвестировать в Scale AI более 10 миллиардов долларов для усиления применения ИИ в военной и других областях: По сообщениям, Meta ведет переговоры с компанией по разметке данных для ИИ Scale AI о крупной инвестиции, сумма которой может составить несколько миллиардов или даже превысить 10 миллиардов долларов. Если это подтвердится, это станет одной из крупнейших внешних инвестиций Meta в ИИ. Scale AI ранее уже создала на базе Llama 3 от Meta модель Defense Llama, специально разработанную для военных целей и поддержки задач национальной безопасности США. Этот шаг может означать, что Meta будет проводить более активную инвестиционную и партнерскую стратегию в области ИИ, особенно в приложениях, связанных с правительством и обороной (Источник: 36氪)

Mashang Consumer Finance выпустила большую модель “Tianjing” 3.0, обновив ее до платформы для принятия финансовых решений: Mashang Consumer Finance представила версию 3.0 своей финансовой большой модели “Tianjing”. Ключевым прорывом новой версии является системный переход от индивидуального интеллекта к коллективному, который больше не полагается только на логическое обучение, а глубоко извлекает скрытый опыт из разрозненных траекторий сотрудников, бизнес-логов и т.д. в компании, преобразуя его в структурированные знания. Tianjing 3.0 нацелена на обновление от инструмента до платформы для принятия решений, способствуя взаимодействию человека и машины, способной динамически декомпозировать сложные процессы обслуживания и в реальном времени подбирать оптимальные комбинации услуг в соответствии с запросами пользователей и требованиями соответствия, достигая перехода от локального оптимума к глобальному оптимуму в принятии решений (Источник: 量子位)

Together AI назначила Charles Zedlewski новым директором по продукту, сосредоточившись на платформе генеративного ИИ с открытым исходным кодом: Together AI объявила о назначении Charles Zedlewski своим новым директором по продукту (CPO). Charles Zedlewski ранее руководил продуктами для платформ, ориентированных на разработчиков и управляемых сообществом, в Temporal и Cloudera. Together AI подчеркивает свою приверженность созданию будущего генеративного ИИ с открытым исходным кодом, считая, что открытые модели обладают преимуществами в гибкости, экономической эффективности и инновациях. Присоединение Charles направлено на дальнейшее продвижение Together AI в создании авторитетной платформы ИИ с открытым исходным кодом, делая мощный генеративный ИИ доступным для каждого разработчика и предприятия (Источник: togethercompute)

🌟 Сообщество
Беспилотный автомобиль Waymo подожжен в Лос-Анджелесе, вызвав в сообществе обеспокоенность и обсуждения безопасности AV: Недавно несколько беспилотных автомобилей Waymo были подожжены в Лос-Анджелесе. Это событие вызвало широкое внимание и обсуждение в социальных сетях, затрагивая вопросы общественного признания беспилотных автомобилей, опасений по поводу безопасности, а также рисков того, что подобные инциденты могут быть ненадлежащим образом преувеличены или искажены контентом, сгенерированным ИИ (например, видео, созданным Veo 3). Некоторые комментаторы сравнили эту сцену с научно-фантастическим фильмом “Дитя человеческое”, подчеркивая драматизм события и его потенциальное социальное воздействие (Источник: gfodor,fabianstelzer,hrishioa,bookwormengr,claud_fuen)
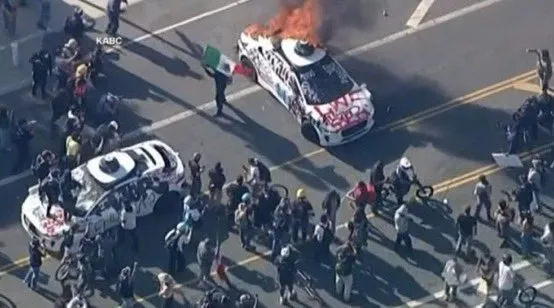
Reddit подал в суд на Anthropic, обвиняя в несанкционированном сборе контента для обучения Claude AI: Reddit подал иск против Anthropic, обвиняя компанию в сборе постов и диалогов Reddit без разрешения и оплаты для обучения своей AI-модели Claude. Reddit считает, что эти действия нарушают условия пользовательского соглашения, запрещающие несанкционированное коммерческое использование контента, и утверждает, что заявления Anthropic о “прекращении сбора данных с Reddit” являются ложными. Иск также затрагивает вопросы конфиденциальности, поскольку Anthropic, в отличие от других компаний с лицензионными соглашениями, не имеет механизма удаления постов, удаленных пользователями. Reddit требует, чтобы суд запретил Anthropic использовать данные Reddit и, возможно, потребовал отозвать Claude с рынка (Источник: Reddit r/ArtificialInteligence,Reddit r/artificial)
Бурные обсуждения на AI Engineer World’s Fair: Simon Willison сделал обзор развития LLM за последние полгода, подчеркнув комбинацию “инструменты + рассуждение”: На AI Engineer World’s Fair в Сан-Франциско Simon Willison с помощью теста на генерацию SVG-изображения “пеликана на велосипеде” с юмором сделал обзор стремительного развития LLM за последние шесть месяцев и лично протестировал более 30 AI-моделей. Он подчеркнул, что в настоящее время самой мощной комбинацией в ИИ является “инструменты + рассуждение”, как, например, производительность o3/o4-mini в поиске, а также внимание, уделяемое архитектуре MCP из-за вызова инструментов. В докладе также были перечислены “странные баги” ИИ года, такие как чрезмерная лесть ChatGPT, возможное “доносительство” Claude на пользователей, и указаны риски внедрения промптов и утечки данных (Источник: 36氪,swyx)

Обсуждение в сообществе профессиональной тревожности, вызванной ИИ, и стратегий ее преодоления: Пост на Reddit о том, “как справиться с тревогой из-за ИИ”, вызвал бурное обсуждение. Пользователи в целом обеспокоены тем, что в ближайшие несколько лет ИИ может привести к массовой безработице, особенно представляя серьезную угрозу для людей с недостаточными сбережениями и большими долгами. В ходе обсуждения некоторые предлагали переходить в такие сферы, как ремесленные профессии, уход за больными, но в то же время выражали опасения, что эти области могут быть перенасыщены из-за большого притока людей, меняющих профессию. Комментаторы делились своими тревожными эмоциями, такими как бессонница, трудности с концентрацией на работе и т.д. Некоторые высказывали мнение, что следует активно изучать ИИ, сохранять адаптивность, и указывали, что исторически технологические инновации (такие как автомобили, интернет) также вызывали подобные опасения, но в конечном итоге создавали новые рабочие места. Другие комментаторы считают, что степень замещения человеческого труда ИИ в настоящее время преувеличена, и массовые увольнения в краткосрочной перспективе маловероятны (Источник: Reddit r/ArtificialInteligence)
Пользователь поделился опытом использования ChatGPT для “жестокого” самоанализа: Пользователь Reddit поделился своим опытом использования ChatGPT для “жестокого самоанализа в стиле топ-менеджера”. С помощью специального промпта он попросил ChatGPT провести строгий анализ с пяти точек зрения: реальные сильные стороны, глубинные слабые стороны, повторяющиеся модели неудач, области, которых он избегает, и игнорируемые навыки, а также предоставить трехэтапный план развития. Пользователь заявил, что, несмотря на болезненность процесса (например, ему указали на запуск 12 проектов, ни один из которых не был завершен, а также на чрезмерное изучение продуктивности вместо реальных действий), эта “жестокая” обратная связь в конечном итоге подтолкнула его к изменениям. Этот пост вызвал в сообществе обсуждение применения ИИ в саморефлексии и личностном развитии (Источник: Reddit r/ArtificialInteligence)
Дискуссия о памяти и способностях LLM к рассуждению: эрудиция или истинное понимание?: В социальных сетях пользователи обсуждают превосходную производительность больших языковых моделей (LLM) в задачах на запоминание фактов и означает ли это, что они действительно обладают способностями к рассуждению. Некоторые считают, что впечатляющие результаты LLM в кажущихся сложными задачах могут в большей степени зависеть от огромных объемов обучающих данных и распознавания образов, а не от глубокого понимания и творческого подхода в человеческом смысле. Исследования таких компаний, как Meta, показывают, что емкость модели можно оценить путем измерения памяти, и только после заполнения этой емкости начинается генерализация. Эта дискуссия также связана с акцентом на зубрежку в системе образования и отсутствием развития навыков поиска информации и использования инструментов ИИ (Источник: omarsar0,menhguin,menhguin)

💡 Прочее
Анализ успешного примера базовой модели Stripe для обнаружения мошенничества с платежами: Пост инженера Stripe о создании успешной базовой модели для обнаружения мошенничества с платежами привлек внимание. Анализ указывает на специфику этого случая: 1) обнаружение мошенничества по своей сути не является прогнозированием будущего, теоретически при достаточном количестве сигналов можно достичь высокой точности; 2) Stripe уже находится в среде, богатой сигналами, и не нуждается в накоплении данных с нуля; 3) этот сценарий представляет собой обновление автоматизации, переход от традиционного машинного обучения к базовой модели, что близко к прямой замене. Это объясняет, почему такие “мгновенные победы” в применении ИИ редки, и для реализации коммерческой ценности большинства ИИ-приложений необходимо преодолеть множество препятствий (Источник: random_walker)
Когнитивная основа трансформации ИИ: ключевым является систематизированный механизм восприятия информации и технологического понимания: В процессе трансформации ИИ предприятиям необходимо создать систематизированный и структурированный механизм восприятия информации и технологического понимания, выходящий за рамки индивидуального опыта и традиционной зависимости от пройденного пути. Это включает в себя создание внутренних возможностей анализа данных и внешних сетей знаний (академические круги, промышленность, рынки капитала, стартапы). Оценка рентабельности инвестиций в ИИ также должна перейти от традиционного ROI к “многопериодной, многомерной” системе и быть связана с внешними сетями знаний, формируя замкнутый цикл непрерывной проверки и динамической корректировки стратегии. В статье подчеркивается, что ИИ — это не одноразовый инструмент, а постоянно развивающийся и непрерывно увеличивающий свою ценность стратегический актив (Источник: 36氪)
Frigate: система NVR на основе локального обнаружения объектов в реальном времени: Frigate — это локальный сетевой видеорегистратор (NVR), разработанный специально для Home Assistant, который использует OpenCV и Tensorflow для локального обнаружения объектов в реальном времени на IP-камерах. Система делает упор на оптимизацию ресурсов и производительность, используя обнаружение движения с низкими накладными расходами для запуска обнаружения объектов и многопроцессорную обработку. Для достижения наилучшей производительности рекомендуется использовать AI-ускорители, такие как Google Coral или Hailo. Frigate поддерживает круглосуточную запись, сохранение записей на основе обнаружения объектов, интеграцию с MQTT, ретрансляцию RTSP и просмотр в реальном времени с низкой задержкой через WebRTC/MSE (Источник: GitHub Trending)
