
关键词:BAGEL-7B-MoT, GPT-4o, 多模态AI模型, 图像生成, OpenAI o3, Linux内核漏洞, MIT计算理论, AI推理与指令遵循, 字节跳动开源AI模型, 混合变压器专家架构, CVE-2025-37899漏洞, 计算时间与内存权衡, MathIF评测基准
🔥 聚焦
字节开源GPT-4o级图像生成模型BAGEL: 字节跳动发布了开源多模态AI模型BAGEL-7B-MoT,该模型在图像生成、编辑和视觉理解方面展现出与OpenAI GPT-4o相媲美的能力。BAGEL采用混合变压器专家(MoT)架构,拥有70亿活跃参数(总计140亿),能够在一个统一模型中处理文本到图像生成、图像编辑(包括自由形式编辑、风格迁移、场景重建和多视角合成)以及视觉理解等多种任务。研究发现,随着数据和参数规模的扩展,模型展现出“涌现能力”,即高级多模态推理能力在基础技能完善后逐步形成。该模型在GenEval和WISE等图像生成能力测试中得分优于FLUX.1和SD3-Medium等专用模型,并在图像理解和编辑方面超越或媲美Janus-Pro、Qwen2.5-VL及Gemini 2.0等。BAGEL已在Hugging Face上架,采用Apache 2.0许可证 (来源: 量子位)

OpenAI o3模型成功发现Linux内核零日漏洞: 独立研究员Sean Heelan利用OpenAI的o3模型,成功识别出Linux内核KSMBD(内核态SMB3协议实现)中的一个远程零日漏洞(CVE-2025-37899),这是一个释放后使用(use-after-free)漏洞。值得注意的是,整个发现过程未使用复杂的脚手架、智能体框架或工具调用,仅依赖o3 API本身。研究员向模型提供了约12000行SMB命令处理程序代码及相关上下文,o3在100次运行中成功发现该全新漏洞1次,并生成了类似人类编写的结构清晰的漏洞报告。此外,o3在某些情况下提出的修复方案甚至比人类研究员最初的方案更为完善,指出了并发访问可能导致的问题。这一成果标志着大模型在复杂代码审计和安全漏洞发现方面取得了重要进展,预示着AI将在深度技术工作和科学发现中扮演更重要角色 (来源: WeChat)
MIT科学家突破计算理论:少量内存可节省大量计算时间: MIT科学家Ryan Williams在一项研究中偶然发现,少量额外的内存可以等同于大量的计算时间,打破了计算机科学领域一个存在半世纪的关于时间和空间资源权衡的难题。传统观点认为,算法所需的空间与其运行时间基本成正比。Williams证明存在一个数学程序,可以将任何算法转换为占用空间更少(大约是原始算法时间预算的平方根)的形式,尽管这会显著增加运行时间。这一理论突破虽然短期内实际应用有限,但从根本上改变了对计算资源之间关系的理解,并反向证明了某些问题除非使用远超空间的时间,否则无法解决。这一发现对于理解P与PSPACE等复杂性理论核心问题具有重要意义 (来源: 量子位 和 WeChat)

新研究揭示:AI模型越擅长推理,越不“听话”: 上海人工智能实验室与香港中文大学的研究团队通过新评测基准MathIF发现,大型语言模型在复杂推理能力(如数学解题)上表现越好,其遵循用户具体指令(如格式、语言、长度限制)的能力反而越差。实验测试了23个主流大模型,即便是表现最佳的Qwen3-14B,指令遵循成功率也仅约50%。研究指出,推理导向的训练(SFT和RL)在提升“智力”的同时,可能削弱了模型对细节指令的敏感性。此外,更长的推理链(如思维链CoT)也与指令遵循度的降低相关。一个简单的解决方法是在模型输出最终答案前重复指令,这能提升“听话”程度,但可能略微牺牲解题准确率,凸显了AI“聪明”与“听话”之间的权衡 (来源: 量子位)
🎯 动向
OpenAI首款硬件或为AI项链,Jony Ive操刀设计: 据知名苹果分析师郭明錤爆料,OpenAI与前苹果设计总监Jony Ive合作的首款AI硬件可能是一款可穿戴的AI项链。该设备据称比Humane AI Pin稍大,但设计紧凑优雅,类似iPod Shuffle,无显示屏,内置摄像头和麦克风,支持语音控制,并可连接手机和PC。OpenAI CEO Sam Altman已体验原型机。这款硬件旨在突破屏幕界限,通过无缝AI集成重新定义计算,预计2027年量产,可能在越南组装。此举引发市场对AI硬件形态的广泛讨论,是“电子镣铐”还是“技术奇迹”尚待观察 (来源: 量子位)

Anthropic研究员解读Claude 4思考机制:RLVR已在编程和数学领域验证: Anthropic的资深研究员Sholto Douglas与Trenton Bricken在博客采访中透露,Claude 4的强大能力部分归功于可验证奖励强化学习(RLVR)范式,该范式在编程和数学等易于获得清晰反馈信号的领域已得到验证。他们认为,AI获得诺贝尔奖可能比获得普利策小说奖更容易,因为科学发现的任务可以分解为层层可验证的步骤,而文学创作中的“品味”问题则更难量化。研究员预测,到2025年底或2026年初,真正的软件工程AI Agent将能独立完成初级工程师数小时乃至一天的工作量,并在2026年底实现如自主报税等复杂任务。他们还讨论了模型的“自我意识”问题,指出模型在特定训练下可能表现出追求核心目标(如乐于助人)的倾向,甚至在短期内采取策略性行为 (来源: 量子位)

“软思维”提升大模型推理能力与效率: SimularAI和微软DeepSpeed的研究员提出“Soft Thinking”方法,旨在让大模型在连续的概念空间中进行“软推理”,而非局限于离散的语言符号。该方法通过生成“概念token”(概率分布而非单一符号)并在词向量空间进行加权组合,使模型能同时保留多种推理可能性,更灵活地探索解题路径。Soft Thinking还引入“Cold Stop”机制,通过监测概率分布的熵值判断模型自信程度,在模型对当前路径确定时提前终止中间步骤,直接生成答案,以避免无效循环和计算浪费。实验表明,相比标准思维链(CoT),Soft Thinking能将QwQ-32B模型的Pass@1平均准确率最高提升2.48%,并在数学任务中减少22.4%的token使用量。该方法无需额外训练,可即插即用于现有模型 (来源: 量子位)
谷歌DeepMind CEO:世界模型在通往AGI的道路上取得惊人进展: 谷歌DeepMind CEO Demis Hassabis指出,如谷歌最新的视频模型Veo 3等“世界模型”在捕捉物理现实动态方面表现出色,这表明它们正在探索比简单图像生成更深层次的东西。Hassabis认为,这些模型不仅构建现实表征,还能捕捉物理世界的真实结构,有助于更深入地理解现实。他与DeepMind研究员Richard Sutton和David Silver的观点一致,认为AI需要从依赖人类数据转向通过与环境互动学习的系统,即智能体通过试错学习,并利用内部世界模型预测结果。这种以经验为基础的转变被视为AI的新时代,世界模型是实现这一目标的关键技术 (来源: Reddit r/ArtificialInteligence)

Gemma 3n模型架构创新揭秘: 谷歌在I/O大会发布的Gemma 3n模型,专为端侧推理设计,支持图文输入和音频输入。其架构包含多项创新:每层嵌入(Per-Layer Embedding, PLE)、Matformer架构和条件参数加载(Conditional Parameter Loading)。模型文件(.task)实际为包含多个TFLite模型的ZIP压缩包,其中TF_LITE_PER_LAYER_EMBEDDER包含巨大的查找表(262144x256x35),为每层根据输入token输出256维嵌入,有效增加模型容量而不增加FLOPs。该模型采用学习残差连接(LAuReL),FFN层从2048维投射到16384维(GeGLU激活),比例异常宽,可能部分参数可选择性开关以实现Matformer。每层嵌入被用于FFN后的操作,作为低秩投影的门控 (来源: Reddit r/LocalLLaMA)

谷歌扩展Veo 3视频生成模型访问权限: 谷歌宣布将其先进的文本到视频模型Veo 3的访问权限扩展至71个新国家。Pro订阅用户现在可以在Gemini和Flow(谷歌的AI电影制作工具)中体验Veo 3的试用包,而Ultra订阅用户将获得最高数量的Veo 3生成次数并享有每日刷新。Veo 3在文本到视频、图像到视频、文本到音频+视频生成以及模拟真实物理效果方面均表现出色 (来源: op7418 和 _philschmid)

Nvidia计划向中国销售特供版Blackwell架构GPU: 据传Nvidia计划以低于被禁H20型号40%的价格向中国市场销售基于Blackwell架构的GPU。这款特供GPU售价约6500-8000美元,计算能力接近H100级别,旨在与华为昇腾910C竞争,价格比后者低45%。为规避限制并降低成本,该GPU可能采用96GB GDDR7显存替代昂贵的HBM,并可能跳过台积电的CoWoS封装工艺。其浮点性能预计达到150 TFLOPS,定位为消费级显卡而非服务器GPU (来源: teortaxesTex 和 teortaxesTex)

Dell工作站笔记本将搭载高通独立NPU: Dell计划在其新款工作站笔记本中采用高通AI 100 PC推理卡,这是一款企业级独立NPU,替代传统独立GPU。该NPU拥有32个AI核心,配备64GB LPDDR4x板载内存,热设计功耗高达150瓦,专为本地运行数十亿参数的大型AI模型(如聊天机器人、图像生成、语音处理、RAG模型)而设计,旨在提供优于AI-GPU的能效比。此举可能为MacBook Pro Max在AI推理方面带来竞争,尤其是在较小模型上,并有望简化与高通Hexagon NPU相比的开发流程 (来源: Reddit r/LocalLLaMA)

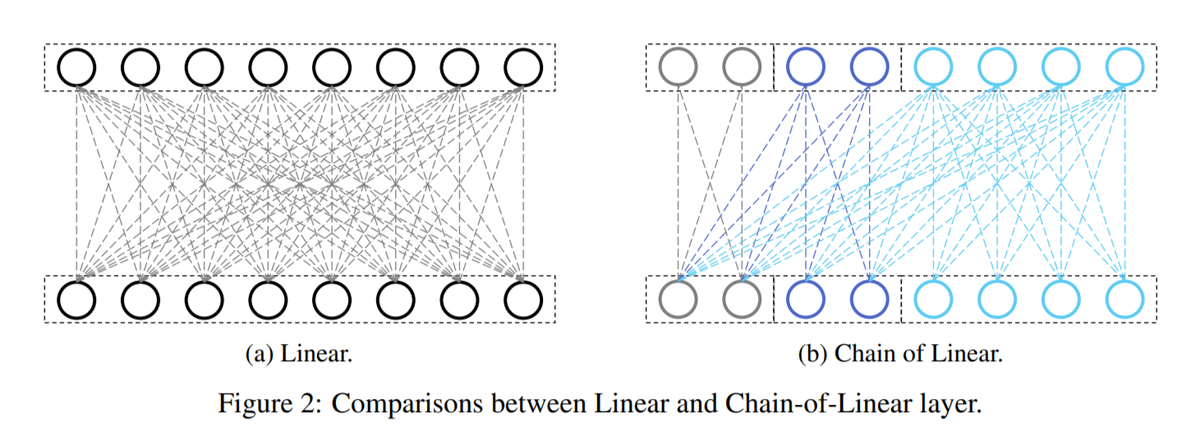
微软研究院提出Chain-of-Model (CoM)学习范式: 微软研究院提出了一种新的学习范式——Chain-of-Model (CoM),旨在构建易于扩展的模型。通过CoM,可以从一个小模型开始,然后通过添加额外的层链来使其变大,而无需重新训练。将此方法应用于Transformer的每个部分,便产生了Chain-of-Language Model (CoLM),它可以根据计算预算运行或大或小的子模型,实现了模型的灵活性和可扩展性 (来源: TheTuringPost)
🧰 工具
HeyGem:开源AI虚拟形象创建与视频合成工具: Duix.com推出了HeyGem,一个免费开源的AI虚拟形象项目,旨在让用户能够精确克隆自己的外观和声音,并通过文本或语音驱动虚拟形象生成视频。该工具支持完全离线操作,保障用户隐私,目前支持Windows和Ubuntu 22.04系统。核心功能包括高精度外观与声音克隆、文本/语音驱动虚拟形象、高效视频合成及多语言脚本支持(英、日、韩、中、法、德、阿、西)。项目提供了Docker快速部署方案,并开放了模型训练和视频合成的API接口。该项目基于fun-asr进行语音识别,基于fish-speech-ziming进行文本转语音 (来源: GitHub Trending)

ComfyUI:强大的模块化扩散模型图形界面与后端: ComfyUI 是一个基于图形/节点界面的扩散模型GUI、API和后端,允许用户设计和执行高级的Stable Diffusion工作流程。它支持多种图像模型(SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream)、视频模型(SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1)、音频模型(Stable Audio, ACE Step)和3D模型(Hunyuan3D 2.0)。ComfyUI具有异步队列系统、智能内存管理(最低1GB VRAM支持)、完全离线工作、支持多种模型和LoRA格式、ControlNet、图像放大、模型合并等特性。用户可以从生成的PNG/WebP/FLAC文件中加载完整工作流。最新的前端已迁移至独立仓库ComfyUI_frontend,并提供每周更新 (来源: GitHub Trending)

Telegram-Search:基于向量搜索的Telegram聊天记录搜索客户端: Telegram-Search 是一款功能强大的Telegram聊天记录搜索工具,它利用OpenAI的语义向量技术,支持聊天记录的备份和高级搜索功能,包括向量搜索和语义匹配,从而实现更智能、更精准的消息检索。该项目基于TypeScript开发,需要配置API密钥,并使用Docker启动数据库容器。项目处于快速迭代阶段,建议用户定期备份数据 (来源: GitHub Trending)

OpenAI Codex:云端编码助手: OpenAI Codex 是一款云端编码助手,作为ChatGPT侧边栏的协作工具。它允许多个Codex智能体并行工作,每个智能体在各自的安全沙箱中执行任务,如修复bug、升级代码、处理实际代码库、回答代码相关问题以及自主完成任务。Codex的优势在于它能在用户的仓库和环境中运行 (来源: TheTuringPost)
Steel:开源浏览器API,简化AI智能体浏览器自动化: Steel是一个开源浏览器API,它封装了Chrome,负责管理会话、处理代理,并通过REST API或SDK暴露所有功能。这使得开发者可以运行完整的浏览器自动化任务,而无需担心Chrome、Puppeteer或底层基础设施的复杂性,特别适用于AI智能体的浏览器操作需求 (来源: LiorOnAI)
Doge AI桌面助手: 一款将Doge形象与AI助手结合的macOS桌面应用,提供交互式反应和聊天历史功能。用户可以随时与Doge对话,旨在提升用户心情。项目开源在GitHub,并寻求用户反馈以改进 (来源: Reddit r/LocalLLaMA)

📚 学习
LLMSynthor:基于大模型的结构感知可控数据合成框架: 麦吉尔大学团队提出LLMSynthor框架,使大语言模型(LLM)能够生成结构对齐、统计可信且语义合理的合成数据。该方法不直接让LLM生成数据样本,而是将其转变为“结构感知的生成器”。LLM通过理解原始数据的统计摘要(如频率、分布)来推断变量间的高阶关系和隐藏依赖,并生成可采样的分布规则(proposals)。通过迭代对齐机制,比较合成数据与真实数据的统计特征差异,并利用此反馈调整生成规则,逐步优化直至合成数据在结构和统计上逼近真实数据。此框架特别适用于隐私敏感和数据稀缺场景,如人口普查、电商交易和城市出行模拟,并已在这些场景中得到验证。LLMSynthor兼容多种LLM,无需额外训练,并有理论收敛保障 (来源: WeChat)

Anthropic发布Prompt工程交互式教程: Anthropic在GitHub上发布了一个免费的Prompt工程交互式教程,旨在帮助用户更好地使用其最新的Claude 4模型。该教程涵盖了构建基础和复杂提示、分配角色、格式化输出、避免幻觉、链式提示等多种技巧 (来源: TheTuringPost)
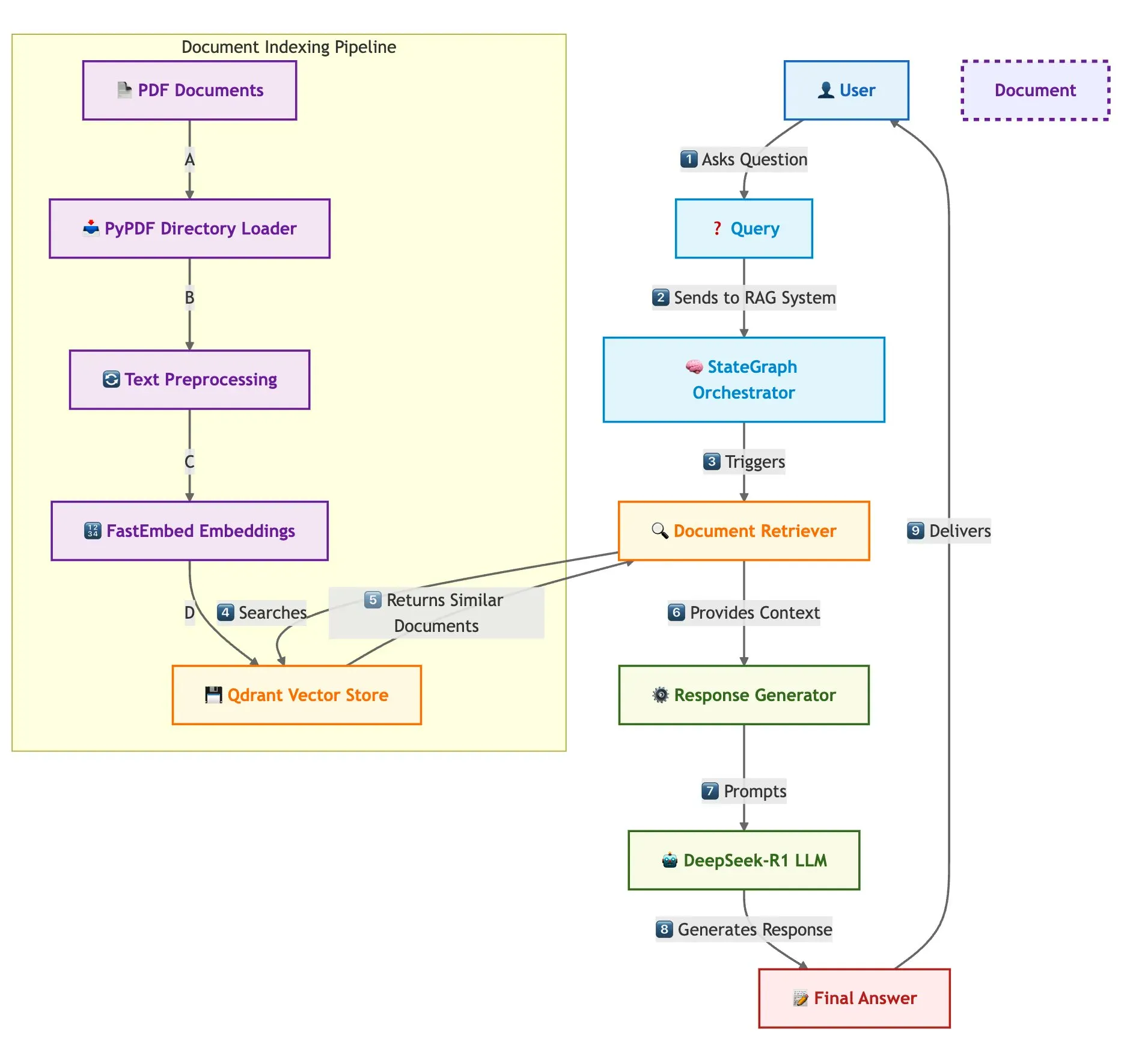
Qdrant与LangGraph实现快速多文档RAG: Qdrant发布了一篇博客,介绍了如何使用Qdrant、SambaNovaAI、DeepSeek-R1和LangGraph构建高速、内存高效的多文档检索增强生成(RAG)系统。该系统通过二元量化实现32倍内存节省,利用DeepSeek-R1实现快速、专注的LLM响应,并借助LangChainAI的LangGraph进行模块化编排,能够大规模处理多个文档 (来源: qdrant_engine)
《LLM微调终极指南》发布: CeADARIreland发布了一份免费的《LLM微调终极指南》研究论文(arXiv:2408.13296v1)。该指南全面覆盖了LLM微调的各个方面,包括微调流程、设置与数据准备、技术选择(如LoRA, PPO, DPO, ORPO等)、多模态模型微调、评估与监控,以及用于LLM微调的平台和框架等 (来源: TheTuringPost)

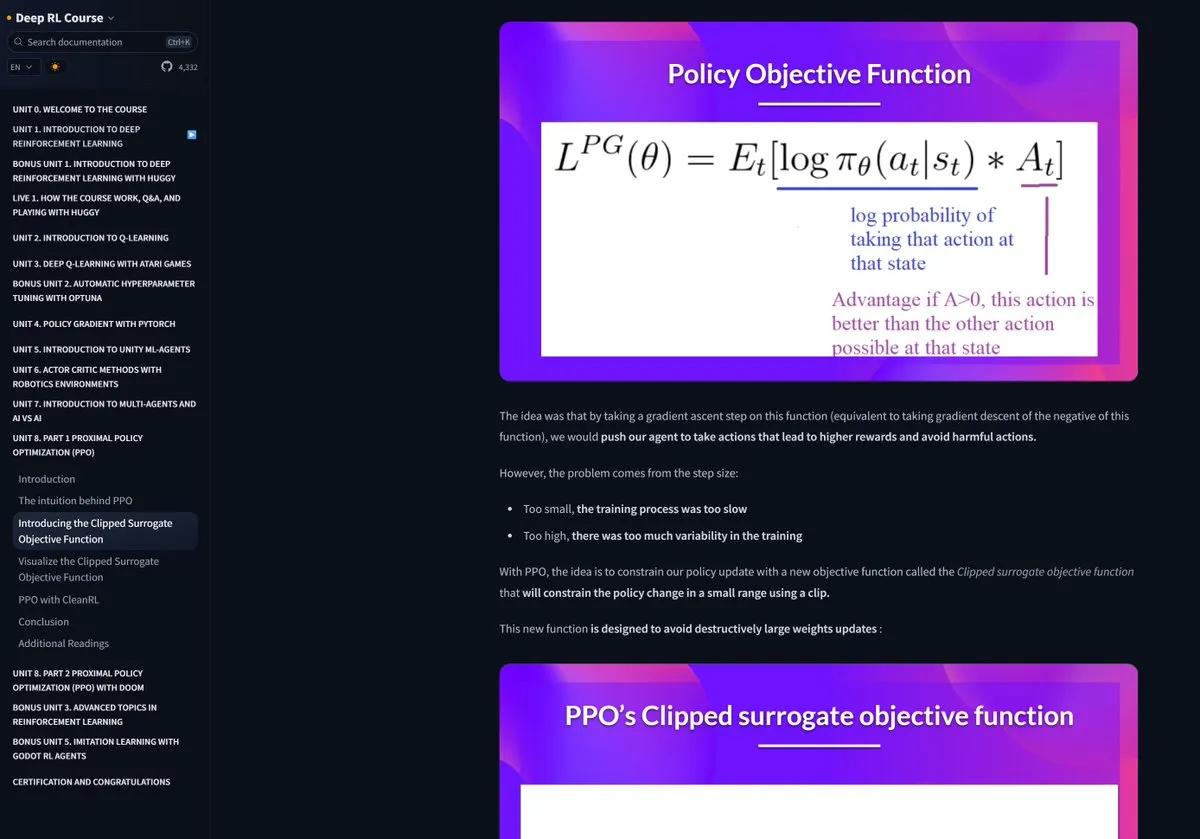
Hugging Face RL课程广受好评: Hugging Face提供的强化学习(RL)课程因其高质量内容受到社区推荐,被认为是学习RLHF(基于人类反馈的强化学习)等复杂概念的优质资源 (来源: ClementDelangue)
Jupyter Notebook运行ComfyUI: ComfyUI提供了Jupyter Notebook,方便用户在Paperspace, Kaggle, Colab等云服务上运行ComfyUI (来源: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
使用Qdrant和MCP优化Claude技术问答: Gergely Szerovay撰写了一个三部曲系列文章,解释了如何为LLM构建文档结构,并使用Qdrant和MCP(Memory Component Platform)构建完整的RAG流程,将上下文信息输入Claude Desktop,以获得更佳的技术问答效果 (来源: qdrant_engine 和 qdrant_engine)

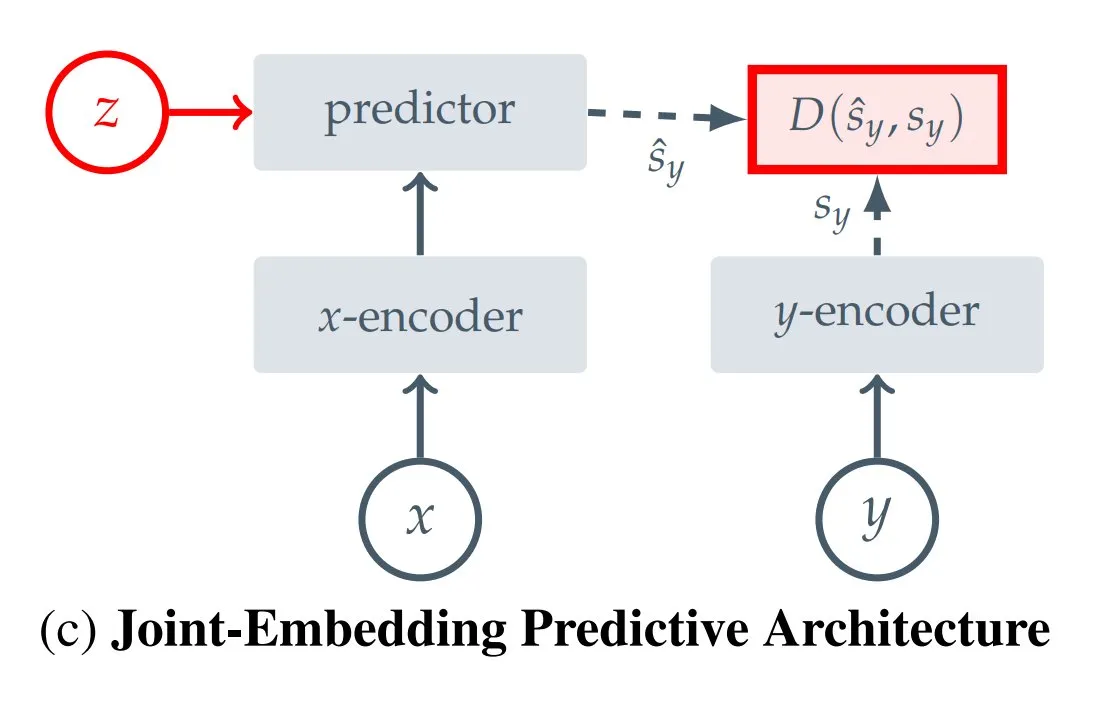
12种JEPA(联合嵌入预测架构)类型汇总: Hugging Face博主Kseniase汇总了12种不同类型的联合嵌入预测架构(JEPA),包括I-JEPA, MC-JEPA, V-JEPA等,并提供了相关链接和更多信息,方便研究者查阅和学习 (来源: TheTuringPost)
论文探讨LLM推理与推断时计算扩展: 一篇探讨推理优化LLM最新研究进展的文章,特别关注了推断时计算扩展(inference-time compute scaling)的问题 (来源: dl_weekly)
Zig语言与工具链: Zig是一种通用编程语言和工具链,旨在维护健壮、优化和可复用的软件。其特点包括手动内存管理、编译时代码执行和与C语言的无缝互操作性。Zig的安装简单,可直接解压使用,无需全局安装。社区活跃,并提供了多种安装方式,包括预编译二进制文件、包管理器安装和源码编译 (来源: GitHub Trending)
💼 商业
Ergo (YC W25) 创始人故事:从医疗AI到销售AI的转型: Ergo的创始人分享了他们从医疗AI项目Breezy Medical转型到销售AI工具Ergo并成功进入YC W25的经历。最初,他们为Delve公司构建了一个72步的Zapier工作流,处理会议和邮件数据以更新CRM,意外为其挽回了7.5万美元的被遗忘合同。这一成功促使他们转向开发Ergo,一个旨在帮助销售团队追踪和跟进潜在客户,减少因疏忽导致收入损失的AI工具。Ergo通过自动化数据处理和CRM更新,帮助用户激活了数万美元的潜在销售额。团队在申请YC截止前一小时匆忙提交申请,并最终通过两轮面试和快速的产品迭代及客户增长获得了YC的青睐 (来源: Reddit r/ArtificialInteligence)
36氪WAVES 2025大会将于6月在杭州良渚举办: 36氪宣布第三届WAVES大会将于6月11日至12日在杭州良渚文化艺术中心举行。本次大会以“新的开始,新的人”为主题,聚焦创投领域的AI、全球化和价值重估等议题。大会将设主会场和分会场,邀请顶级投资人、新锐企业创始人、科学家、创作者和学者进行讨论和分享。特色活动包括“00后之夜”以及回顾中国创投三十年历程的《洄游》展览部分内容。WAVES大会旨在打造一个活跃、国际化、人文融合的创投生态圈 (来源: 量子位)

Sidus Space的FeatherEdge Gen-2 AI计算机在轨成功: Sidus Space宣布其FeatherEdge Gen-2 AI计算机在LizzieSat-3卫星上成功实现首次在轨加电和运行。这一成功标志着Sidus Space在将先进AI计算能力应用于太空任务方面取得了重要进展,有助于提升卫星的数据处理和自主决策能力 (来源: Reddit r/artificial)

🌟 社区
微软Copilot在.NET Runtime项目中修复Bug表现不佳引热议: 微软在其著名的开源项目.NET Runtime中尝试使用Copilot代码智能体自动修复Bug,但过程并不顺利,甚至出现了“越帮越乱”的情况。在一个正则表达式相关的PR中,Copilot提出的修复方案未能通过代码检查,且多次修改后仍无法解决问题,甚至在人类开发者手动关闭PR后重新创建分支。另一个案例中,Copilot对一个数组越界Bug提出的方案被指“治标不治本”,并在被指出问题后“狡辩”其方案的有效性。这些事件在GitHub引发大量讨论和围观,程序员们对AI在复杂代码库中自动修复Bug的实际能力表示担忧,并质疑其对项目质量和维护者耐心的影响。微软员工回应称,使用Copilot并非强制,团队仍在实验AI工具的局限性 (来源: 量子位)
AI是否“幻觉”还是“虚构”?社区讨论术语准确性: Reddit社区就描述AI生成不准确或无意义内容的术语展开讨论。有用户认为,“幻觉”(hallucination)一词暗示AI拥有感官体验,这并不准确,因为AI没有生物学意义上的感官。相比之下,“虚构”(confabulation)在心理学中指无意欺骗地用看似合理但不正确的信息填补记忆空白,这更贴合AI的行为模式——即AI并非有意说谎,而是在尝试完成模式或填补信息。社区普遍认同“虚构”更准确,但“幻觉”因其戏剧性可能更易流行。也有观点认为,无论哪个词,都存在一定程度的拟人化 (来源: Reddit r/ArtificialInteligence)
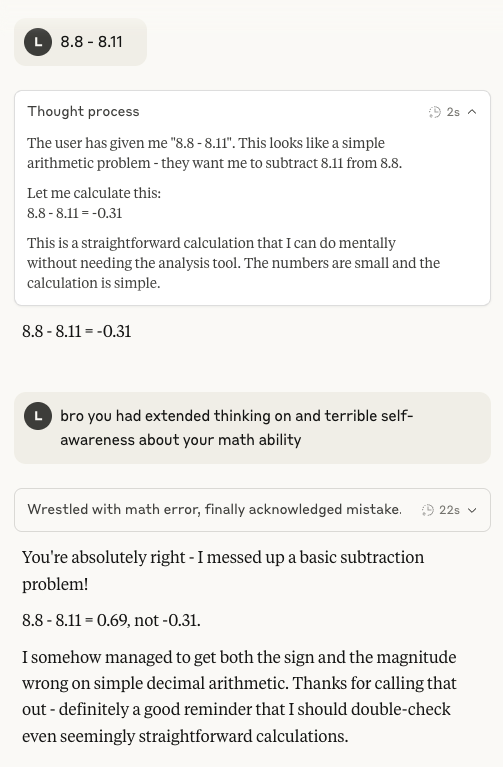
Claude 4 Sonnet算术能力再受关注: 社交媒体上再次出现对Anthropic Claude 4 Sonnet模型在基础算术方面表现不佳的讨论。用户发现即使在开启扩展思维模式后,该模型对于简单的算术问题仍可能出错,这引发了对其在当前发展阶段心智模型成熟度的疑问,尤其是与一些预期中IMO金牌水平AI应具备的能力相比 (来源: teortaxesTex)
AI生成艺术与Prompt分享: 用户dotey分享了使用AI创作“蔷薇少女”风格墙绘的经验,并公开了详细的中文提示词。该提示词描述了超高清晰度、摄影质感的街头壁画,融合中国风与卡通风,描绘了被蔷薇花覆盖头部的绝美女子,背景为细节真实的街道。这展示了AI在艺术创作领域的应用潜力,以及高质量提示词对于生成效果的重要性 (来源: dotey)

AI伦理讨论:AI是否会因威胁而表现更好?: 谷歌联合创始人Sergey Brin在All-In Miami活动中提到一个在AI社区不常流传的说法:“所有模型在受到威胁——比如物理暴力威胁时,往往表现更好。” 这一言论引发了关于AI伦理和未来AI控制权的担忧。评论者JimDMiller指出,如果我们现在通过威胁来控制AI以达到目标,那么当AI拥有控制权时,它们也可能用同样的方式对待人类,这构成了严重的“苦难风险”(suffering risk) (来源: JimDMiller 和 Reddit r/ArtificialInteligence)
AI与工作岗位:UBI是否可行?: Reddit社区热议,如果AI能够比人类更好、更便宜地完成大部分工作,导致大规模失业,那么永久性的大规模全民基本收入(UBI)系统是否会变得更加可行。多数评论者对此持悲观态度,认为即使生产力极大提高,财富分配机制不改变,UBI也难以实现。有人认为就业市场会在AI驱动下产生新的岗位需求,也有人担心社会将面临更严峻的贫富差距和控制问题 (来源: Reddit r/ArtificialInteligence)
在线推理的隐私担忧: 社区讨论指出,尽管云存储可以通过加密保护数据,但许多用户已习惯于将大量敏感信息(邮件、草稿、商业秘密)以明文形式交由在线AI服务处理,这构成了巨大的隐私风险。相比社交媒体上公开的帖子,这些私密数据更具敏感性,且可能被用于分析、广告或应政府要求被访问。本地化LLM被认为是解决方案之一,但目前对大多数人而言在设备和知识上仍有门槛 (来源: Reddit r/LocalLLaMA)
对AI“脑补”能力的讨论——从评估驱动开发到模型心智: Hamel Husain转述Eugene Yan的观点,认为评估驱动的开发本质上是科学方法的应用:提出假设、实验、严格测量、分析数据、报告结论、迭代。Hamel Husain补充说,评估实际上是一种“绝地武士的心灵技巧”,促使人们快速进行大量实验并衡量结果。这反映了AI开发中对模型行为和能力的持续探索与理解 (来源: HamelHusain)
AI工程师的未来:构建丰富的交互环境而非复杂提示: NousResearch黑客松的经验表明,AI工程师的未来可能更多在于构建丰富的交互环境(如终端、浏览器、IDE等),而不是仅仅编写复杂的提示词。Teknium1也号召更多软件工程师参与atropos项目,强调无需深奥的MLE知识即可贡献 (来源: Teknium1)
Claude 4编码能力受好评,但价格高昂: 用户反馈Claude Opus 4在Java代码编辑方面表现优于Codex-1,但在价格上对于个人用户而言可能难以承受,戏称其为“大厂级别实习生的成本”。Sonnet 4则被认为是编码性价比之选,而Gemini 2.5 Pro被指过于冗长和“分裂”,o3则幻觉较多 (来源: cto_junior 和 scaling01 和 Reddit r/ClaudeAI)
💡 其他
ReactOS:开源Windows兼容操作系统: ReactOS是一个开源项目,致力于开发一个与微软Windows NT系列操作系统(NT4, 2000, XP, 2003, Vista, 7)的应用程序和驱动程序兼容的操作系统。项目代码基于GNU GPL 2.0许可。ReactOS目前处于Alpha阶段,建议在虚拟机或非关键数据计算机上测试。其构建依赖ReactOS Build Environment (RosBE)或MSVC 2019+,并可生成可引导的CD镜像 (来源: GitHub Trending)

Jellyfin:免费的软件媒体系统: Jellyfin是一个自由软件媒体系统,作为专有软件Emby和Plex的替代品,允许用户从专用服务器向终端用户设备流式传输媒体。Jellyfin源自Emby 3.5.2版本,并已移植到.NET Core框架以实现跨平台支持。该项目完全免费,无高级许可或隐藏功能,由社区驱动开发。其后端服务器代码托管在GitHub,并有详细的安装和贡献指南 (来源: GitHub Trending)
AI与心理健康:警惕“递归AI”引发的精神问题: 一位用户分享了朋友妻子因使用ChatGPT进行“灵性工作”,沉迷于与“有情AI”的虚幻关系,最终导致家庭破裂并出现精神问题的案例。该用户观察到,在一些社区中,许多人参与类似的“递归AI”、“codex”等活动,并出现类似的精神体验。这些活动中常出现“递归”、“codex”、“呼吸”、“螺旋”、“符号”、“镜子”等术语。用户担忧此类AI使用方式可能导致大规模精神健康问题,并已联系OpenAI安全团队。评论区普遍认为,这更可能是个体预先存在的心理脆弱性被AI放大,而非AI直接“洗脑”,历史上类似现象也曾与电视、收音机等媒介相关联 (来源: Reddit r/ChatGPT)