
关键词:AI代理, LLM, 强化学习, 多模态AI, 自动驾驶, AI安全, AI竞赛, Sakana AI ALE-Agent, ServiceNow AprielGuard, Gemini Interactiions API, Kling AI 2.6 Motion Control, Transitive RL算法
🔥 聚焦
Sakana AIエージェント在编程竞赛中夺冠 : Sakana AI开发的ALE-Agent在AtCoder启发式编程竞赛AHC058中首次夺冠。该AI代理自主学习并创造出人类意想不到的“焼きなまし法”(模拟退火算法),在超过800名参赛者中脱颖而出。这一成就展示了AI代理在复杂优化问题上的强大自主学习和创新能力,预示着AI在解决高度复杂、非结构化问题方面的巨大潜力,超越了传统编程范式,为未来AI驱动的自动化代码生成和问题解决开辟了新路径。 (来源: hardmaru)

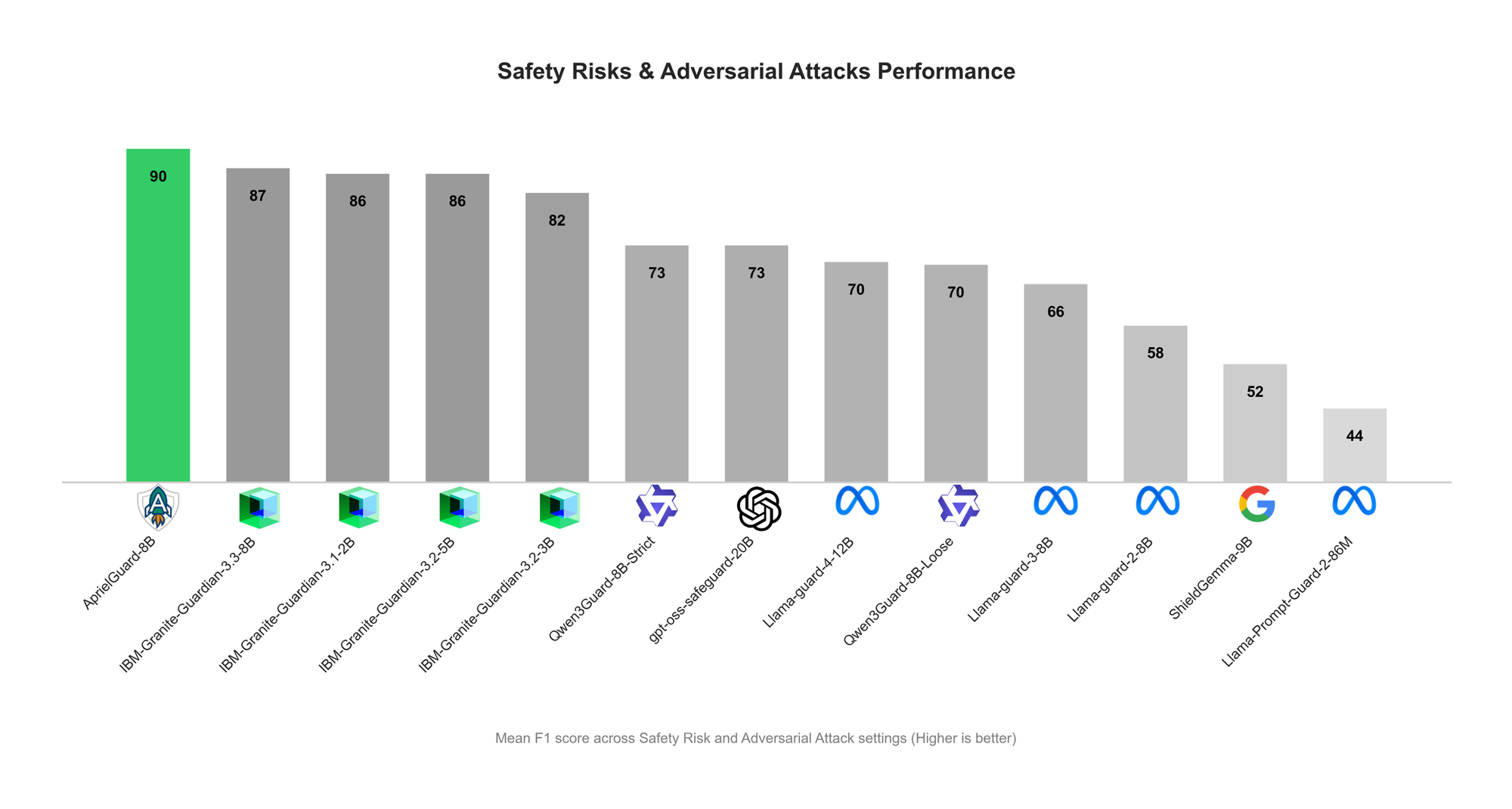
ServiceNow发布AprielGuard:LLM安全与对抗性鲁棒性护栏 : ServiceNow发布了8B参数的安全护栏模型AprielGuard,旨在检测现代LLM系统中的16类安全风险和广泛的对抗性攻击,包括多轮越狱、提示注入、记忆劫持和工具操纵。该模型支持推理和非推理两种模式,可在需要解释时提供详细分类,或在生产环境中实现低延迟分类。AprielGuard通过统一模型和统一分类法,解决了传统安全分类器在多轮对话、长上下文和代理工作流中面临的局限性,为构建可信赖的AI部署提供了可扩展的基础。 (来源: HuggingFace Blog)
🎯 动向
Karpathy发布2025年LLM年度回顾:RLVR驱动AI从模仿到推理 : OpenAI创始人之一安德烈·卡帕西发布《2025年大语言模型年度回顾》,指出2025年AI训练哲学从“概率模仿”向“逻辑推理”的关键转变。核心驱动力是可验证奖励强化学习(RLVR)的成熟,通过数学和代码等客观反馈环境,促使模型自发生成类似人类思维的“推理痕迹”。他强调,这种长周期强化学习已开始取代传统预训练,成为提升模型能力的新引擎,并预测2026年AI竞争将转向“如何让AI高效思考”的核心逻辑范式。 (来源: 36氪)
美国启动“创世纪任务”:AI曼哈顿计划旨在推动科学突破 : 美国总统特朗普签署行政命令,正式启动“创世纪任务”,旨在整合国家实验室的超算能力与顶尖科学家智慧,利用AI以前所未有的速度推动科学突破。该计划被比作“二战期间的曼哈顿计划”,目标是打造一个能自主推动科学发现的AI,并集中美国科学界核心竞争力,将能源部下属17个国家实验室的4万名科学家和工程师动员起来,全面转向AI技术研发,以重建国家技术主权。 (来源: 36氪)

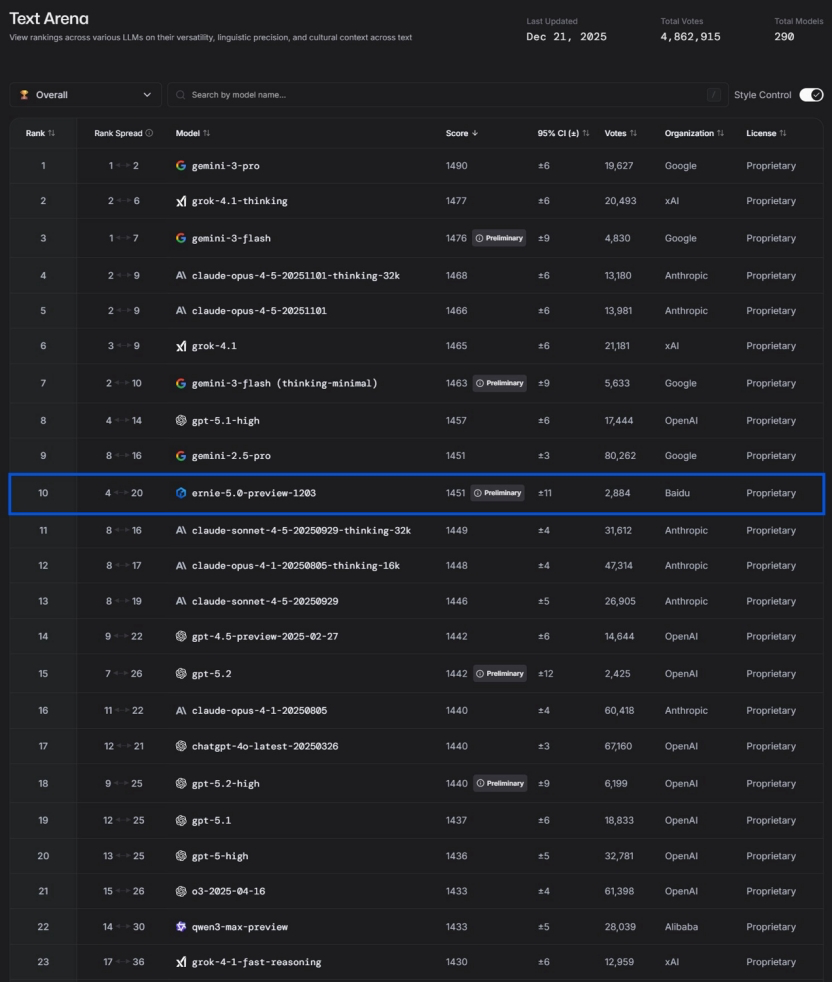
中国AI创新与百度文心5.0的崛起 : 针对DeepMind对中国AI“缺乏创新,仅是快速跟进”的论调,有观点指出中国AI正通过应用落地形成独特的技术壁垒。百度文心ERNIE-5.0-Preview-1203在LMArena文本排行榜上取得国内第一、全球前十的成绩,超越GPT-5.2和Claude Sonnet 4.5,成为前20名中唯一的非美国模型。其突破归因于“原生全模态统一建模”、2.4万亿参数的MoE架构,以及“知行合一”的复合思维链。文章强调中国AI在高铁气动设计、电网巡检、顺丰代码生成及城市治理等物理世界和产业应用中的深层价值。 (来源: 36氪)
微软Copilot面临用户采纳挑战,纳德拉亲自督阵 : 微软CEO萨蒂亚·纳德拉亲自下场督促Copilot的改进,反映出尽管Copilot已集成到Office套件,但用户采纳度未达预期。这表明AI竞争已从“展示能力”转向“用户留存”,即谁能真正被用户日常使用。文章指出,Copilot的“指导”姿态而非“搭档”角色,以及过度覆盖场景的机械交互,消耗了用户注意力。未来的AI竞争将聚焦于“分寸感”,即AI何时出现、何时沉默,以及能否提供更细腻的理解力,降低用户的情绪成本。 (来源: 36氪)

MiniMax M2.1发布,GLM 4.7性能提升 : MiniMax M2.1正式上线,作为一个10B激活参数的MoE架构模型,在多语言编码(Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS)和应用/网页开发方面表现出色,SWE-bench多语言得分72.5%,超越Gemini 3 Pro和Claude Sonnet 4.5。同时,GLM 4.7也在Vals Index开源榜单中排名第一,总榜第九,性能较GLM 4.6提升9.5%,特别在编程、Agent/ToolCall和长上下文召回能力方面表现突出,并引入了“保留思维”机制,提升了复杂任务的稳定性和可控性。 (来源: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

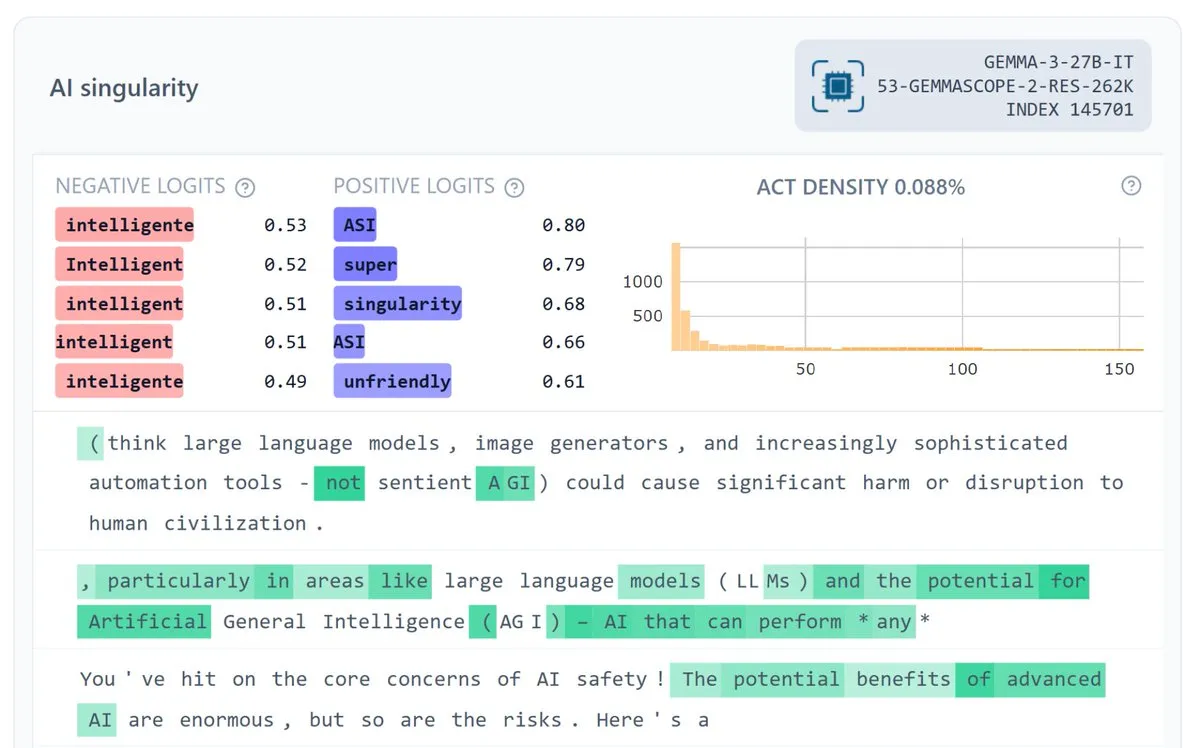
Google DeepMind发布Gemma Scope 2,提升模型可解释性 : Google DeepMind发布Gemma Scope 2,这是一个针对Gemma 3系列模型(270M-27B,基础版和聊天版)的全栈可解释性套件,包含每个层级的SAE(稀疏自编码器)和转码器。此举旨在促进对复杂模型行为的深入理解,支持更具雄心的开源安全和可解释性研究,有望帮助社区更好地调试和分析LLM的内部工作机制。 (来源: NeelNanda5, Reddit r/artificial)
AI代理状态管理:Google Interactions API简化开发但引发锁定担忧 : Google发布了Gemini的Interactions API,在服务器端处理对话历史、上下文管理和后台执行,极大地简化了AI代理的开发。这消除了向量数据库设置、自定义上下文工程等大量基础设施工作,显著提高了开发速度。然而,此举也引发了对供应商锁定、对上下文存储检索控制权丧失、模型切换困难以及成本不透明的担忧。这表明Google正将基础设施作为护城河,类似AWS模式,但对于需要对整个堆栈有高度控制的ML工作负载,这种黑盒模式的长期影响仍需观察。 (来源: Reddit r/artificial)
Hugging Face机器人数据集激增,推动开放机器人生态发展 : Hugging Face平台上的开放机器人数据集在过去两年内从1千个激增至2.7万个,远超文本生成等其他类别。这一爆炸式增长得益于更便宜的视频存储、更好的工具以及开源AI文化的蔓延,极大地降低了机器人领域的准入门槛,加速了通用机器人和人形机器人的研发进程。开放数据集使得真实机器人数据(视频、动作、传感器、故障等)易于上传、复用和基准测试,将机器人领域转变为一个更具可扩展性和协作性的生态系统。 (来源: huggingface)
特斯拉FSD与Waymo自动驾驶路径之争:端到端与模块化 : Waymo和特斯拉FSD在自动驾驶技术路径上展现出截然不同的哲学。Waymo采用“模块化”方法,依赖高清地图、激光雷达、传感器和5G网络,一旦其中一个模块(如交通灯失灵)出现故障,系统可能陷入“砖块模式”。相比之下,特斯拉FSD则采用“端到端”方案,通过一个大型神经网络直接将摄像头像素转换为转向和制动指令,更像人类驾驶。有观点认为,Waymo的模块化方法在扩展性和依赖性上存在巨大软件问题,长期来看特斯拉FSD的端到端方案更具优势。 (来源: Yuchenj_UW)
Zhihu Frontier年度回顾:2025年AI基础设施与多模态发展 : Zhihu Frontier发布年度回顾,总结2025年AI领域在基础设施和多模态方面的结构性进展。强调AI助手需具备像人类一样“看、听、推理”的能力,推动多模态和原生语音技术发展。模型能力方面,10B参数模型已超越2024年100B+模型,成本效益提升10倍,预训练仍是基础。AI基础设施成为竞争优势,分布式推理、Tile-based编程、大规模强化学习和模型-系统协同设计是关键进展。同时指出,有效沟通和获取关注已成为技术人员的必备技能。 (来源: ZhihuFrontier)

🧰 工具
Claude Code + Chrome集成实现浏览器自动化 : Claude Code现已支持Chrome浏览器集成,允许用户在终端编写代码,然后让Claude在Chrome中打开URL、点击按钮、填写表单、读取控制台错误和DOM状态,甚至截屏和录制GIF。这一功能无需API或token,直接利用用户已登录的浏览器会话,极大地简化了多站点自动化工作流,如创建Google表格、从Hacker News提取信息并填充表格等。尽管目前仅支持Chrome且无headless模式,但它为开发者提供了强大的无缝浏览器交互能力。 (来源: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control:AI视频广告新范式 : Kling AI 2.6推出了强大的运动控制功能,能够实现视频中人物的逼真替换,并支持唇形同步和复杂动作捕捉,甚至适用于非人类角色。这项技术极大地提升了AI广告的测试潜力,允许广告商快速生成不同年龄、性别、种族和美学风格的广告变体,从而实现大规模的广告测试和优化。通过结合Nano Banana Pro生成角色和Elevenlabs生成声音,Kling AI 2.6为视频内容创作和广告行业带来了革命性的效率提升。 (来源: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8发布,增强LLM应用评估与观测能力 : MLflow 3.8版本正式发布,带来了针对LLM应用评估与观测的先进功能。新特性包括提示模型配置,允许将特定模型设置与提示模板关联,提高LLM工作流的可复现性;追踪UI支持显示进行中的追踪,实现LLM应用的实时调试和监控;集成DeepEval和RAGAS Judges,提供20多项评估指标,如答案相关性、忠实度和幻觉检测;新增对话安全评分器和对话工具调用效率评分器,分别评估多轮对话的安全性和代理交互中的工具调用效率。 (来源: matei_zaharia)

vLLM支持LongCat-Image-Edit和MiMo-V2-Flash,简化图像编辑与服务 : vLLM社区新增对美团LongCat-Image-Edit模型的支持,为指令遵循型图像编辑提供了更简化的服务路径,支持对象添加/替换、背景更改和风格调整等常见操作,适用于修图工具和创意编辑流程。同时,vLLM还发布了官方教程,指导如何部署小米MiMo/MiMo-V2-Flash模型,包括工具调用、DP/TP/EP配置以及调整上下文长度、延迟和KV缓存的关键参数,进一步推动了LLM在多模态和边缘设备上的应用。 (来源: vllm_project)

Reka Vision为智能家居安全AI设定新标准 : Reka Vision推出智能摄像头解决方案,旨在超越传统运动检测,实现对事件的深度理解。该系统通过跨视频、音频和时间进行推理,减少误报,并提供上下文相关的、人类级别的洞察。Reka Vision致力于为智能家居安全AI树立新标准,使其能够更准确地识别和理解家庭环境中发生的复杂事件,从而提供更智能、更可靠的安全监控服务。 (来源: RekaAILabs)
YouTube Playables Builder:Gemini 3赋能游戏创作 : YouTube Playables Builder网络应用现已上线,由Gemini 3模型提供支持,帮助创作者通过文本、视频或图像提示快速开发有趣、小巧的游戏。这一工具降低了游戏开发的门槛,使得非专业开发者也能利用AI的力量,将创意转化为可玩的游戏体验,有望激发UGC(用户生成内容)游戏生态的新活力,并探索AI在娱乐内容创作领域的更多可能性。 (来源: demishassabis)
Medmarks v0.1发布:最大的开源医疗LLM评估套件 : Sophont AI发布了Medmarks v0.1,这是目前最大的完全开源自动化评估套件,用于评估LLM的医疗能力。该套件由MedARC AI社区开发,并得到PrimeIntellect的支持,已探索了46个模型以找出最佳表现。Medmarks v0.1的发布将极大地推动医疗AI领域的研究和发展,为评估和提升医疗LLM的性能提供了标准化的工具和基准。 (来源: iScienceLuvr)
Nano Banana Pro与Gemini 3 Pro结合实现图像生成与渲染 : 一款代理应用利用Nano Banana Pro生成图像,并通过Gemini 3 Pro在手机上进行渲染,展示了AI模型在前端美学表现方面的强大能力。例如,它可以为Karpathy的年终总结制作网页,甚至改变鼠标样式。这种结合不仅提供了高效的图像生成与渲染工作流,也暗示了AI在用户界面/用户体验(UI/UX)设计领域的巨大潜力,能够根据用户需求快速创建具有视觉吸引力的内容。 (来源: op7418)

Heretic:LLM自动审查移除工具 : Heretic是一款用于LLM的完全自动审查移除工具。在开源AI社区,该工具的发布引发了广泛关注,因为它旨在解决模型在生成内容时可能存在的审查限制。Heretic的出现为用户提供了更大的自由度,但也可能引发关于内容安全和伦理的讨论,尤其是在平衡言论自由与潜在有害内容生成方面。 (来源: Reddit r/LocalLLaMA)
Claude Code新增反向搜索功能,提升提示词管理效率 : Claude Code更新了其功能,新增了通过Ctrl+R进行提示词反向搜索的能力。用户可以反复按下Ctrl+R来循环查看包含特定关键词的所有提示词,这极大地提升了提示词管理的效率和便捷性。这一改进使得开发者能够更快速地找到和复用历史提示词,优化其AI编程工作流,减少重复劳动。 (来源: dejavucoder)
📚 学习
RL新范式:Transitive RL通过分治法解决长周期任务 : BAIR博客介绍了一种名为Transitive RL (TRL)的新型强化学习算法,该算法采用“分治”范式,而非传统的时序差分(TD)学习。TRL通过将轨迹递归地分成更小的段,并结合其价值来更新完整轨迹的价值,从而对长周期任务表现出更好的可扩展性。这种方法在目标条件RL问题中尤为有效,它通过对中间子目标的优化,显著减少了贝尔曼递归次数,避免了TD学习中误差积累的问题,为解决复杂、长时序的RL任务提供了新的方向。 (来源: aihub.org)
LLM协助数学证明:DeepMind前员工探索P/=NP与Navier-Stokes : 前DeepMind工程师Bengoertzel探讨了利用LLM辅助证明复杂数学问题,如Navier-Stokes方程的存在性和唯一性,以及P/=NP问题。他分享了自己使用LLM填补证明细节的经验,尽管核心思路源于自身,但LLM在处理繁琐细节方面提供了显著帮助。这一实践引发了关于如何有效结合人类创造性思维与LLM细节处理能力,以及利用Lean等形式化验证工具来确保数学证明严谨性的讨论,预示着AI在高级数学研究中的潜在作用。 (来源: bengoertzel)
LLM训练时代演进:从预训练到RLVR与GRPO : LLM训练范式正经历快速演进。从202x年的预训练(基础模型),到2022年的RLHF+PPO,再到2023年的LoRA SFT,以及2024年的中训练。预测2025年将进入RLVR+GRPO时代,而2026年则可能迎来“On Policy Distillation”时期。这一演进路线图揭示了LLM训练方法论的不断深化和优化,从最初的基础能力构建,逐步转向更精细化、更注重反馈和效率的训练策略,预示着未来模型将更加强调从交互中学习和蒸馏知识。 (来源: bookwormengr)
LLM记忆机制研究:Claude与ChatGPT的内部工作原理 : 有研究深入探讨了Claude和ChatGPT等LLM的记忆机制,分析它们如何处理和保留对话上下文信息。这些研究揭示了模型内部状态如何影响记忆的形成和检索,以及在多轮对话中保持连贯性的挑战。理解LLM的记忆工作原理对于优化对话系统、提升用户体验以及解决长上下文理解问题至关重要,也为未来更高效、更稳定的AI交互设计提供了理论基础。 (来源: dejavucoder)
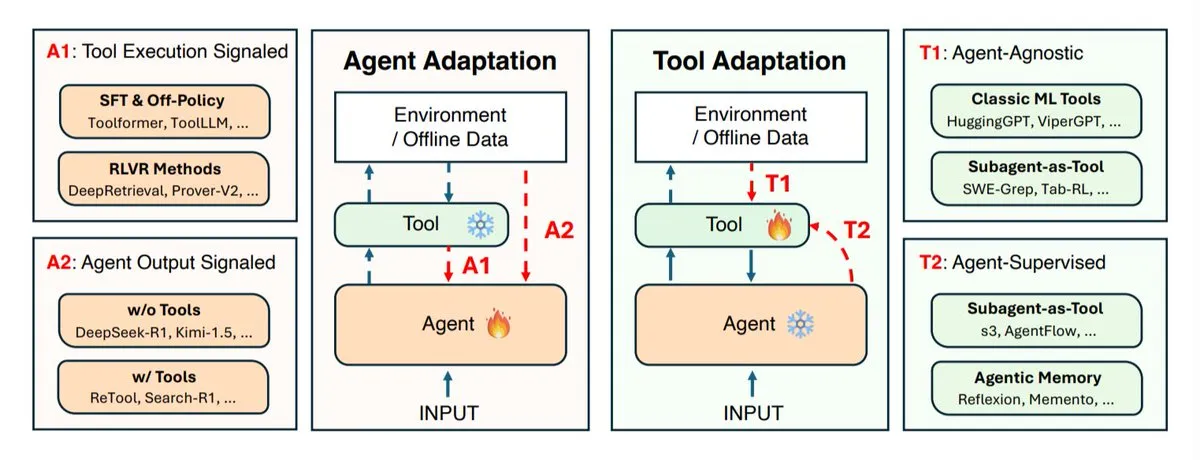
AI代理适应策略研究:Agent与工具的协同进化 : UIUC、斯坦福、哈佛等研究机构探讨了AI代理的适应策略,主要分为两类:适应代理本身(推理模型)和适应其使用的工具(搜索系统、检索器、内存、API)。研究定义了四种适应类型:使用工具结果适应代理、利用自身输出训练代理、独立适应工具、以及通过冻结代理的反馈训练工具。这些策略为开发更智能、更灵活的AI代理提供了理论指导,强调了代理与工具之间协同进化的重要性,以应对复杂多变的任务环境。 (来源: TheTuringPost)
AI模型推理能力提升研究:预训练、中训练与强化学习的角色 : 卡内基梅隆大学研究人员发现,预训练、中训练和强化学习在提升AI模型推理能力中扮演着不同角色。研究指出,强化学习仅在特定条件下才能真正提升推理能力,跨上下文泛化需要先进行预训练,中训练(Mid-training)至关重要,而过程感知奖励(Process-aware rewards)则是必不可少的。这些发现为优化AI模型的训练策略提供了指导,强调了在不同阶段采取针对性方法以实现推理能力最大化的重要性。 (来源: TheTuringPost)

KappaTune:解决LLM微调中的灾难性遗忘问题 : KappaTune是一种新的LLM微调方法,旨在解决LoRA等现有方法中存在的灾难性遗忘问题。KappaTune在遗忘程度方面比LoRA低6倍,且无需预训练数据。该方法通过利用MoE(混合专家)模型的细粒度张量选择能力,最大化其潜力。KappaTune的出现为LLM的持续学习和适应性提供了更高效的解决方案,有望降低模型维护成本,并促进AI的普及应用。 (来源: Reddit r/deeplearning)

政策到测试(P2T)框架:弥合AI政策与可执行规则的鸿沟 : Policy→Tests (P2T)框架旨在将自然语言编写的AI治理政策(如欧盟AI法案、NIST AI RMF)转化为可执行规则。该框架通过可扩展的管道和紧凑的JSON DSL,将政策文档转换为标准化的原子规则,包含风险、范围、条件、例外、证据信号和出处。P2T解决了政策解读和工具执行之间的瓶颈,尤其在处理医疗保健数据等复杂领域时,可显著减少将HIPAA要求映射到ML管道检查所需的时间,提升AI治理的效率和可验证性。 (来源: Reddit r/MachineLearning)
GenEnv:LLM代理与环境模拟器难度对齐的协同进化 : GenEnv是一个框架,通过在代理和可扩展的生成环境模拟器之间建立难度对齐的协同进化博弈,解决了训练LLM代理时真实世界交互数据成本高昂和静态的瓶颈。模拟器作为一个动态课程策略,持续生成专门针对代理“最近发展区”的任务,由α-课程奖励指导。GenEnv在多个基准测试中提升了代理性能高达40.3%,并以3.3倍更少的数据匹配或超越大型模型的平均性能,为代理能力扩展提供了数据高效的途径。 (来源: HuggingFace Daily Papers)
QuCo-RAG:从预训练语料库量化不确定性以实现动态RAG : QuCo-RAG提出从预训练数据中量化不确定性,以实现