
キーワード:AIエージェント, LLM, 強化学習, マルチモーダルAI, 自動運転, AIセキュリティ, AI競争, サカナAI ALEエージェント, ServiceNow AprielGuard, Gemini Interactions API, Kling AI 2.6 モーションコントロール, Transitive RLアルゴリズム
🔥 注目
Sakana AIエージェントがプログラミングコンテストで優勝 : Sakana AIが開発したALE-Agentが、AtCoderのヒューリスティックプログラミングコンテストAHC058で初優勝を飾りました。このAIエージェントは自律的に学習し、人間には思いつかないような「焼きなまし法」(シミュレーテッドアニーリングアルゴリズム)を創造し、800名以上の参加者の中から抜きん出ました。この成果は、AIエージェントが複雑な最適化問題において強力な自律学習と革新能力を持つことを示しており、AIが高度に複雑で非構造化な問題を解決する上で、従来のプログラミングパラダイムを超越する大きな可能性を秘めていることを示唆しています。これは、将来のAI駆動型自動コード生成と問題解決への新たな道を開くものです。 (来源: hardmaru)

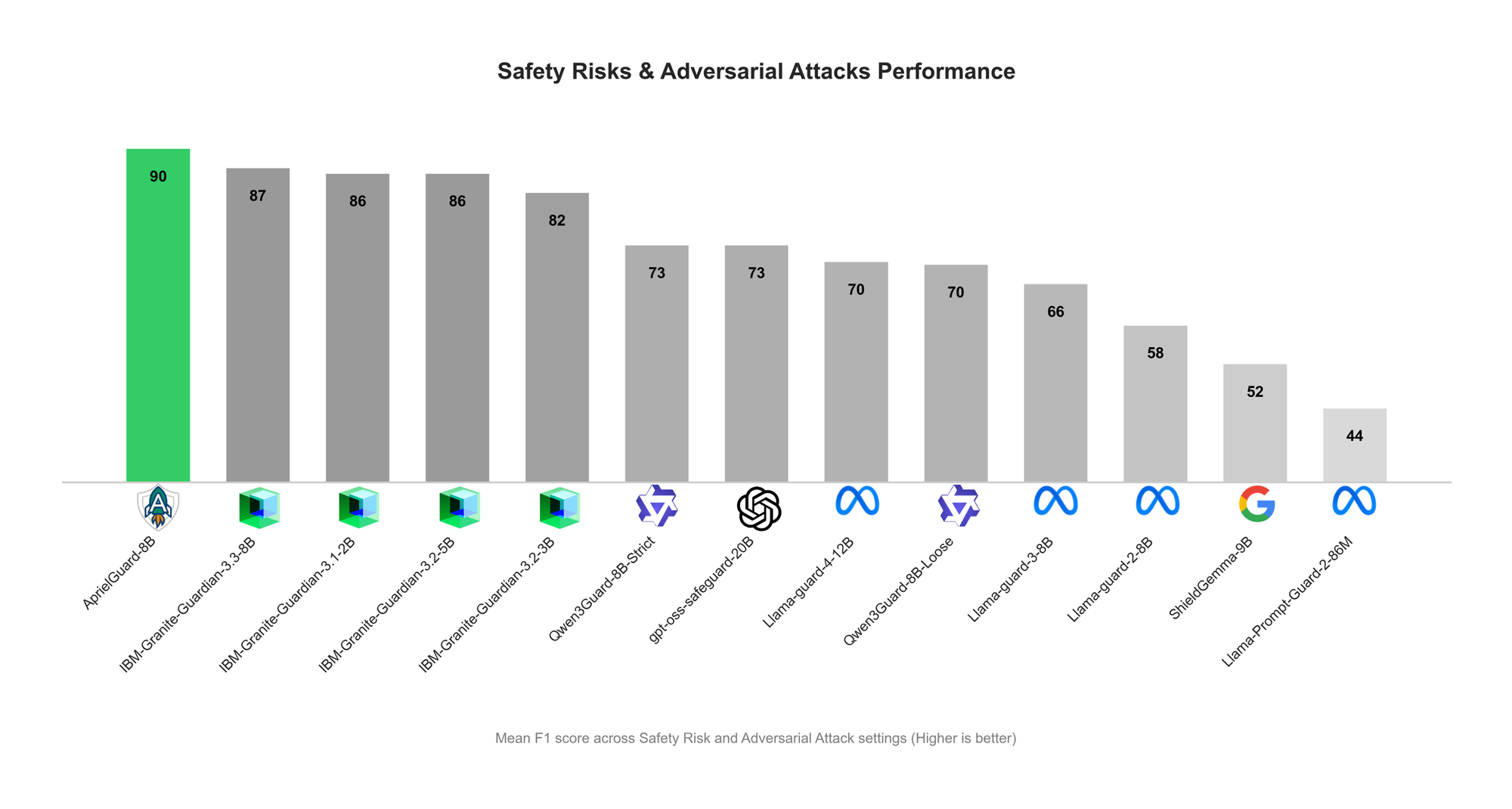
ServiceNowがAprielGuardを発表:LLMの安全性と敵対的堅牢性のガードレール : ServiceNowは、8Bパラメータの安全ガードレールモデルAprielGuardを発表しました。これは、現代のLLMシステムにおける16種類の安全リスクと、多段階のジェイルブレイク、prompt injection、memory hijacking、tool manipulationを含む広範な敵対的攻撃を検出することを目的としています。このモデルは、推論モードと非推論モードの両方をサポートしており、説明が必要な場合には詳細な分類を提供し、本番環境では低遅延の分類を実現できます。AprielGuardは、統一されたモデルと統一された分類法を通じて、多段階の会話、長いコンテキスト、エージェントワークフローにおいて従来のセキュリティ分類器が直面していた限界を解決し、信頼できるAI展開を構築するためのスケーラブルな基盤を提供します。 (来源: HuggingFace Blog)
🎯 動向
Karpathyが2025年LLM年次レビューを発表:RLVRがAIを模倣から推論へ駆動 : OpenAIの共同創設者の一人であるアンドレイ・カルパシーが「2025年大規模言語モデル年次レビュー」を発表し、2025年にAIトレーニングの哲学が「確率的模倣」から「論理的推論」へと大きく転換すると指摘しました。その核心的な推進力は、検証可能な報酬強化学習(RLVR)の成熟であり、数学やコードなどの客観的なフィードバック環境を通じて、モデルが人間のような「推論の痕跡」を自発的に生成するよう促します。彼は、この長周期強化学習が従来の事前学習に取って代わり、モデル能力を向上させる新たなエンジンとなりつつあることを強調し、2026年にはAI競争が「いかにAIを効率的に思考させるか」という核心的な論理パラダイムへと移行すると予測しています。 (来源: 36氪)
米国が「ジェネシスミッション」を開始:AIマンハッタン計画が科学的ブレークスルーを推進 : 米国大統領トランプは、国家研究所のスーパーコンピューティング能力とトップ科学者の知恵を統合し、AIを活用して前例のない速度で科学的ブレークスルーを推進することを目的とした行政命令に署名し、「ジェネシスミッション」を正式に開始しました。この計画は「第二次世界大戦中のマンハッタン計画」になぞらえられ、自律的に科学的発見を推進できるAIを構築し、米国の科学界の核心的な競争力を集中させ、エネルギー省傘下の17の国家研究所の4万人の科学者とエンジニアを動員し、AI技術の研究開発に全面的に転換することで、国家の技術主権を再構築することを目指しています。 (来源: 36氪)

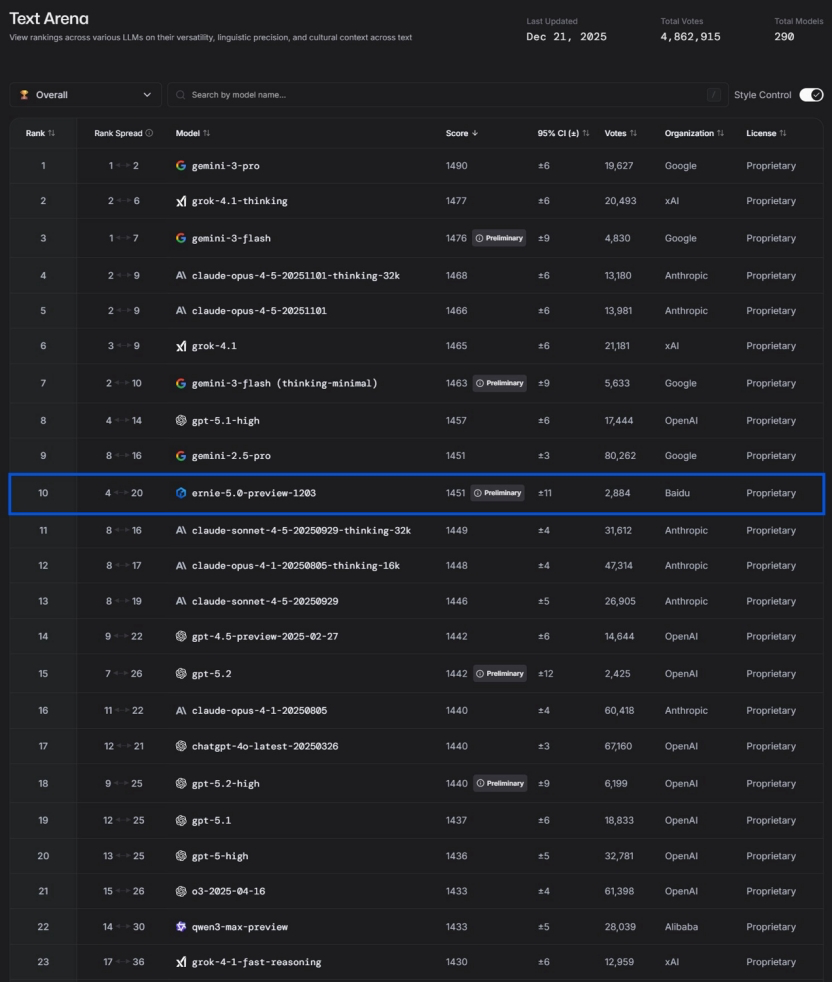
中国AIの革新とBaidu ERNIE 5.0の台頭 : DeepMindが中国AIについて「革新性に欠け、単に迅速に追随しているだけ」と論じたことに対し、中国AIはアプリケーションの実装を通じて独自の技術的障壁を形成しているとの見方があります。Baidu ERNIE-5.0-Preview-1203は、LMArenaのテキストランキングで国内1位、世界トップ10の成績を収め、GPT-5.2とClaude Sonnet 4.5を上回り、トップ20の中で唯一の非米国モデルとなりました。そのブレークスルーは、「ネイティブな全モダリティ統一モデリング」、2.4兆パラメータのMoEアーキテクチャ、そして「知行合一」の複合思考チェーンに起因しています。記事は、中国AIが高速鉄道の空力設計、電力網の巡回検査、SF Expressのコード生成、都市ガバナンスなどの物理世界および産業アプリケーションにおける深い価値を強調しています。 (来源: 36氪)
Microsoft Copilotがユーザー採用の課題に直面、ナデラCEOが自ら指揮 : Microsoft CEOサティア・ナデラがCopilotの改善を自ら監督していることは、CopilotがOfficeスイートに統合されているにもかかわらず、ユーザー採用率が期待に達していないことを反映しています。これは、AI競争が「能力の提示」から「ユーザー定着」、つまり誰が実際にユーザーに日常的に使用されるかへと移行したことを示しています。記事は、Copilotの「指導」的な姿勢が「パートナー」としての役割ではなく、また過度に多くのシナリオをカバーする機械的なインタラクションがユーザーの注意力を消費していると指摘しています。将来のAI競争は「適切な距離感」に焦点を当て、AIがいつ現れ、いつ沈黙すべきか、そしてより繊細な理解力を提供し、ユーザーの感情的コストを低減できるかどうかが鍵となるでしょう。 (来源: 36氪)

MiniMax M2.1がリリース、GLM 4.7の性能が向上 : MiniMax M2.1が正式にリリースされました。10BアクティベーションパラメータのMoEアーキテクチャモデルとして、多言語コーディング(Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS)およびアプリケーション/ウェブ開発において優れた性能を発揮し、SWE-bench多言語スコアで72.5%を記録し、Gemini 3 ProとClaude Sonnet 4.5を上回りました。同時に、GLM 4.7もVals Indexのオープンソースランキングで1位、総合ランキングで9位を獲得し、GLM 4.6と比較して9.5%の性能向上を達成しました。特にプログラミング、Agent/ToolCall、長文コンテキストの想起能力において顕著な進歩を見せ、「思考保持」メカニズムを導入することで、複雑なタスクの安定性と制御性を向上させています。 (来源: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

Google DeepMindがGemma Scope 2をリリース、モデルの解釈可能性を向上 : Google DeepMindは、Gemma 3シリーズモデル(270M-27B、ベース版およびチャット版)向けのフルスタック解釈可能性スイートであるGemma Scope 2をリリースしました。これには、各レイヤーのSAE(Sparse Autoencoder)とトランスコーダーが含まれています。この取り組みは、複雑なモデルの動作に対する深い理解を促進し、より野心的なオープンソースの安全性および解釈可能性研究を支援することを目的としており、LLMの内部動作メカニズムをコミュニティがより良くデバッグし分析するのに役立つと期待されています。 (来源: NeelNanda5, Reddit r/artificial)
AIエージェントの状態管理:Google Interactions APIが開発を簡素化するも、ロックインへの懸念も : GoogleはGeminiのInteractions APIをリリースしました。これは、会話履歴、コンテキスト管理、バックグラウンド実行をサーバー側で処理することで、AIエージェントの開発を大幅に簡素化します。これにより、ベクトルデータベースの設定やカスタムコンテキストエンジニアリングといった大量のインフラ作業が不要になり、開発速度が著しく向上します。しかし、この動きは、ベンダーロックイン、コンテキストの保存と検索に対する制御権の喪失、モデル切り替えの困難さ、コストの不透明性といった懸念も引き起こしています。これは、GoogleがAWSモデルと同様にインフラを堀として利用していることを示していますが、スタック全体に高度な制御を必要とするMLワークロードにとって、このブラックボックスモデルの長期的な影響はまだ注視が必要です。 (来源: Reddit r/artificial)
Hugging Faceでロボットデータセットが急増、オープンロボティクスエコシステムの発展を推進 : Hugging Faceプラットフォーム上のオープンロボットデータセットが、過去2年間で1,000個から27,000個へと急増し、テキスト生成などの他のカテゴリをはるかに上回りました。この爆発的な増加は、より安価なビデオストレージ、より優れたツール、そしてオープンソースAI文化の普及によってもたらされ、ロボティクス分野への参入障壁を大幅に引き下げ、汎用ロボットやヒューマノイドロボットの研究開発プロセスを加速させています。オープンデータセットにより、実際のロボットデータ(ビデオ、動作、センサー、故障など)のアップロード、再利用、ベンチマークが容易になり、ロボティクス分野はよりスケーラブルで協調的なエコシステムへと変貌しています。 (来源: huggingface)
Tesla FSDとWaymoの自動運転経路論争:エンドツーエンドかモジュール式か : WaymoとTesla FSDは、自動運転技術の経路において全く異なる哲学を示しています。Waymoは「モジュール式」アプローチを採用し、高精度マップ、LiDAR、センサー、5Gネットワークに依存しており、交通信号の故障など、いずれかのモジュールに障害が発生すると、システムが「ブリックモード」に陥る可能性があります。対照的に、Tesla FSDは「エンドツーエンド」ソリューションを採用し、単一の大きなニューラルネットワークを通じてカメラのピクセルを直接ステアリングとブレーキの指示に変換し、より人間らしい運転を実現しています。Waymoのモジュール式アプローチは、拡張性と依存性において大きなソフトウェア問題を抱えており、長期的にはTesla FSDのエンドツーエンドソリューションがより優位であるという見方があります。 (来源: Yuchenj_UW)
Zhihu Frontier年次レビュー:2025年のAIインフラとマルチモーダル開発 : Zhihu Frontierは年次レビューを発表し、2025年のAI分野におけるインフラとマルチモーダルに関する構造的進展をまとめました。AIアシスタントが人間のように「見て、聞いて、推論する」能力を持つ必要性を強調し、マルチモーダルおよびネイティブ音声技術の発展を推進しています。モデル能力の面では、10Bパラメータモデルが2024年の100B+モデルをすでに超え、コスト効率が10倍向上しており、事前学習は依然として基盤です。AIインフラは競争優位性となり、分散推論、Tile-basedプログラミング、大規模強化学習、モデルとシステムの協調設計が主要な進展です。同時に、効果的なコミュニケーションと注目を集めることが、技術者にとって必須のスキルとなっていることも指摘しています。 (来源: ZhihuFrontier)

🧰 ツール
Claude Code + Chrome統合でブラウザ自動化を実現 : Claude CodeはChromeブラウザ統合をサポートし、ユーザーがターミナルでコードを記述し、ClaudeにChromeでURLを開かせたり、ボタンをクリックさせたり、フォームに入力させたり、コンソールエラーやDOMの状態を読み取らせたり、さらにはスクリーンショットを撮ったりGIFを録画したりできるようになりました。この機能はAPIやトークンを必要とせず、ユーザーがログイン済みのブラウザセッションを直接利用するため、Googleスプレッドシートの作成やHacker Newsからの情報抽出とフォームへの入力など、複数サイトにわたる自動化ワークフローを大幅に簡素化します。現時点ではChromeのみをサポートし、ヘッドレスモードはありませんが、開発者には強力なシームレスなブラウザインタラクション機能を提供します。 (来源: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control:AI動画広告の新たなパラダイム : Kling AI 2.6は、動画内の人物のリアルな置き換えを可能にし、リップシンクや複雑なモーションキャプチャ、さらには非人間キャラクターにも対応する強力なモーションコントロール機能を発表しました。この技術は、AI広告のテスト可能性を大幅に向上させ、広告主が異なる年齢、性別、人種、美的スタイルの広告バリエーションを迅速に生成し、大規模な広告テストと最適化を実現できるようにします。Nano Banana Proによるキャラクター生成とElevenlabsによる音声生成を組み合わせることで、Kling AI 2.6は動画コンテンツ制作と広告業界に革命的な効率向上をもたらします。 (来源: Kling_ai, Reddit r/ChatGPT)

MLflow 3.8がリリース、LLMアプリケーションの評価と観測能力を強化 : MLflow 3.8バージョンが正式にリリースされ、LLMアプリケーションの評価と観測のための高度な機能が導入されました。新機能には、特定のモデル設定をプロンプトテンプレートに関連付け、LLMワークフローの再現性を向上させるプロンプトモデル設定が含まれます。トラッキングUIは進行中のトラッキング表示をサポートし、LLMアプリケーションのリアルタイムデバッグと監視を実現します。DeepEvalとRAGAS Judgesを統合し、回答の関連性、忠実度、幻覚検出など20以上の評価指標を提供します。さらに、会話の安全性スコアラーと会話ツール呼び出し効率スコアラーが追加され、それぞれ多段階会話の安全性とエージェントインタラクションにおけるツール呼び出し効率を評価します。 (来源: matei_zaharia)

vLLMがLongCat-Image-EditとMiMo-V2-Flashをサポート、画像編集とサービスを簡素化 : vLLMコミュニティは、MeituanのLongCat-Image-Editモデルのサポートを追加し、指示に従う画像編集のためのより簡素化されたサービスパスを提供します。オブジェクトの追加/置換、背景変更、スタイル調整などの一般的な操作をサポートし、画像編集ツールやクリエイティブな編集プロセスに適しています。同時に、vLLMはXiaomi MiMo/MiMo-V2-Flashモデルのデプロイ方法に関する公式チュートリアルも公開しました。これには、ツール呼び出し、DP/TP/EP設定、およびコンテキスト長、遅延、KVキャッシュの主要パラメータの調整が含まれており、LLMのマルチモーダルおよびエッジデバイスでの応用をさらに推進しています。 (来源: vllm_project)

Reka VisionがスマートホームセキュリティAIの新たな基準を設定 : Reka Visionは、従来のモーション検知を超え、イベントの深い理解を実現することを目的としたスマートカメラソリューションを発表しました。このシステムは、ビデオ、オーディオ、および時間軸を横断して推論を行うことで、誤報を減らし、コンテキストに基づいた人間レベルの洞察を提供します。Reka Visionは、スマートホームセキュリティAIの新たな基準を確立し、家庭環境で発生する複雑なイベントをより正確に識別し理解することで、よりスマートで信頼性の高いセキュリティ監視サービスを提供することを目指しています。 (来源: RekaAILabs)
YouTube Playables Builder:Gemini 3がゲーム制作を強化 : YouTube Playables Builderウェブアプリケーションが現在公開されており、Gemini 3モデルを搭載しています。これにより、クリエイターはテキスト、ビデオ、または画像プロンプトを通じて、面白くて小さなゲームを迅速に開発できます。このツールはゲーム開発の敷居を下げ、非専門の開発者でもAIの力を利用して、アイデアをプレイ可能なゲーム体験に変えることを可能にします。UGC(ユーザー生成コンテンツ)ゲームエコシステムに新たな活力を与え、エンターテイメントコンテンツ制作分野におけるAIのさらなる可能性を探ることが期待されます。 (来源: demishassabis)
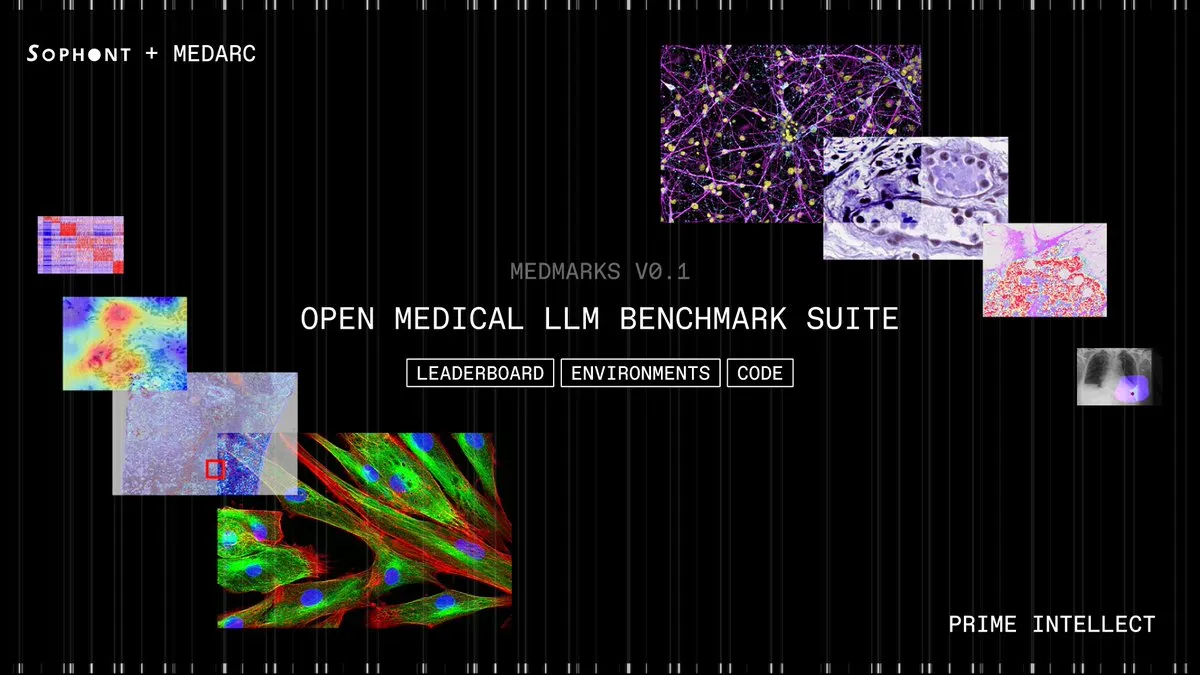
Medmarks v0.1がリリース:最大のオープンソース医療LLM評価スイート : Sophont AIは、LLMの医療能力を評価するための、現在最大の完全オープンソース自動評価スイートであるMedmarks v0.1をリリースしました。このスイートはMedARC AIコミュニティによって開発され、PrimeIntellectの支援を受けており、最適なパフォーマンスを見つけるために46のモデルを調査しました。Medmarks v0.1のリリースは、医療AI分野の研究開発を大きく推進し、医療LLMの性能を評価および向上させるための標準化されたツールとベンチマークを提供します。 (来源: iScienceLuvr)
Nano Banana ProとGemini 3 Proの組み合わせで画像生成とレンダリングを実現 : あるエージェントアプリケーションが、Nano Banana Proを利用して画像を生成し、Gemini 3 Proを通じてスマートフォン上でレンダリングすることで、AIモデルのフロントエンドにおける美的表現の強力な能力を示しました。例えば、Karpathyの年末レビューのためのウェブページを作成したり、マウスのスタイルを変更したりすることも可能です。この組み合わせは、効率的な画像生成とレンダリングのワークフローを提供するだけでなく、AIがユーザーインターフェース/ユーザーエクスペリエンス(UI/UX)デザイン分野で持つ大きな可能性を示唆しており、ユーザーの要求に応じて視覚的に魅力的なコンテンツを迅速に作成できます。 (来源: op7418)

Heretic:LLM自動検閲除去ツール : Hereticは、LLM向けの完全自動検閲除去ツールです。オープンソースAIコミュニティにおいて、このツールのリリースは広範な注目を集めました。なぜなら、モデルがコンテンツを生成する際に存在する可能性のある検閲制限を解決することを目的としているからです。Hereticの登場はユーザーにより大きな自由度を提供しますが、特に表現の自由と潜在的に有害なコンテンツ生成のバランスに関して、コンテンツの安全性と倫理に関する議論を引き起こす可能性もあります。 (来源: Reddit r/LocalLLaMA)
Claude Codeに逆検索機能が追加、プロンプト管理効率を向上 : Claude Codeは機能を更新し、Ctrl+Rによるプロンプトの逆検索機能を追加しました。ユーザーはCtrl+Rを繰り返し押すことで、特定のキーワードを含むすべてのプロンプトを循環して表示でき、これによりプロンプト管理の効率と利便性が大幅に向上します。この改善により、開発者は過去のプロンプトをより迅速に見つけて再利用できるようになり、AIプログラミングワークフローを最適化し、繰り返し作業を削減できます。 (来源: dejavucoder)
📚 学習
RLの新たなパラダイム:Transitive RLが分割統治法で長周期タスクを解決 : BAIRブログは、Transitive RL (TRL)という新しい強化学習アルゴリズムを紹介しました。このアルゴリズムは、従来の時系列差分(TD)学習ではなく、「分割統治」パラダイムを採用しています。TRLは、軌跡を再帰的に小さなセグメントに分割し、その価値を組み合わせて完全な軌跡の価値を更新することで、長周期タスクに対してより優れたスケーラビリティを示します。この方法は、目標条件付きRL問題において特に効果的であり、中間サブ目標の最適化を通じてベルマン再帰の回数を大幅に削減し、TD学習における誤差蓄積の問題を回避します。これにより、複雑で長時系列のRLタスクを解決するための新たな方向性を提供します。 (来源: aihub.org)
LLMが数学的証明を支援:DeepMind元従業員がP/=NPとNavier-Stokesを探索 : 元DeepMindエンジニアのBengoertzelは、LLMを利用してNavier-Stokes方程式の存在と一意性、およびP/=NP問題のような複雑な数学問題の証明を支援することについて議論しました。彼は、LLMを使用して証明の詳細を補完した経験を共有しており、核心的なアイデアは彼自身のものであったものの、LLMが煩雑な詳細処理において顕著な助けとなったと述べています。この実践は、人間の創造的思考とLLMの詳細処理能力をいかに効果的に組み合わせるか、そしてLeanなどの形式検証ツールを利用して数学的証明の厳密性を確保する方法に関する議論を引き起こし、高度な数学研究におけるAIの潜在的な役割を示唆しています。 (来源: bengoertzel)
LLMトレーニング時代の進化:事前学習からRLVRとGRPOへ : LLMのトレーニングパラダイムは急速な進化を遂げています。202x年の事前学習(基礎モデル)から始まり、2022年にはRLHF+PPO、2023年にはLoRA SFT、そして2024年には中間学習へと進化しました。2025年にはRLVR+GRPO時代に突入し、2026年には「On Policy Distillation」の時代が到来すると予測されています。この進化ロードマップは、LLMのトレーニング方法論が絶えず深化・最適化されており、初期の基礎能力構築から、より洗練され、フィードバックと効率を重視したトレーニング戦略へと移行していることを示しています。これにより、将来のモデルはインタラクションからの学習と知識の蒸留をより重視するようになるでしょう。 (来源: bookwormengr)
LLMの記憶メカニズム研究:ClaudeとChatGPTの内部動作原理 : ClaudeやChatGPTなどのLLMの記憶メカニズムを深く掘り下げ、それらが会話コンテキスト情報をどのように処理し保持するかを分析する研究があります。これらの研究は、モデルの内部状態が記憶の形成と検索にどのように影響するか、そして多段階の会話で一貫性を維持する上での課題を明らかにしています。LLMの記憶動作原理を理解することは、会話システムの最適化、ユーザーエクスペリエンスの向上、および長文コンテキスト理解の問題解決にとって極めて重要であり、将来のより効率的で安定したAIインタラクション設計のための理論的基盤も提供します。 (来源: dejavucoder)
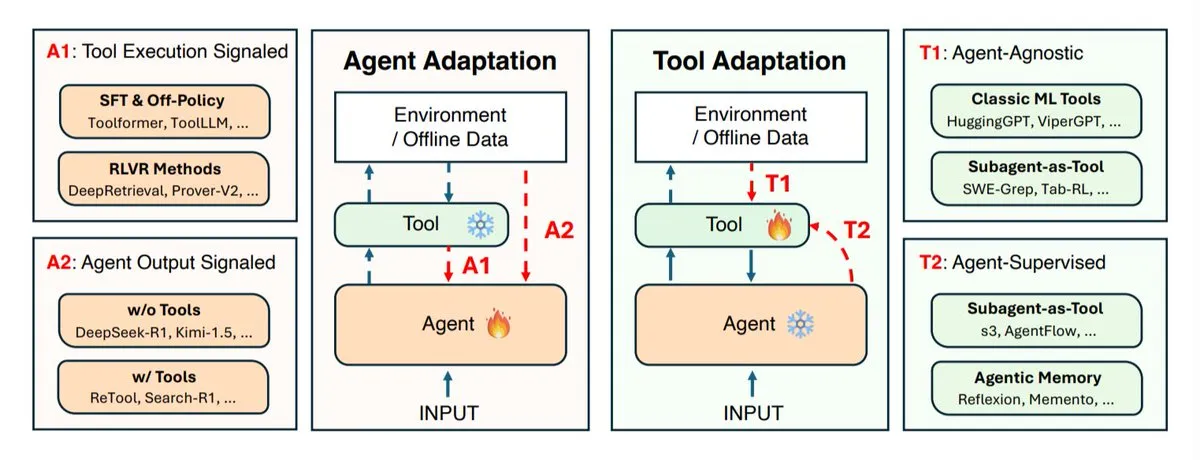
AIエージェントの適応戦略研究:エージェントとツールの協調的進化 : UIUC、スタンフォード、ハーバードなどの研究機関は、AIエージェントの適応戦略について議論しました。主に2つのカテゴリに分けられます:エージェント自体(推論モデル)の適応と、それが使用するツール(検索システム、リトリーバー、メモリ、API)の適応です。研究では、4種類の適応タイプが定義されています:ツール結果を利用したエージェントの適応、自身の出力を利用したエージェントのトレーニング、ツールの独立した適応、およびエージェントを固定したフィードバックによるツールのトレーニングです。これらの戦略は、よりスマートで柔軟なAIエージェントを開発するための理論的指針を提供し、複雑で変化の多いタスク環境に対応するために、エージェントとツール間の協調的進化の重要性を強調しています。 (来源: TheTuringPost)
AIモデル推論能力向上研究:事前学習、中間学習、強化学習の役割 : カーネギーメロン大学の研究者たちは、事前学習、中間学習、強化学習がAIモデルの推論能力向上において異なる役割を果たすことを発見しました。研究は、強化学習が推論能力を真に向上させるのは特定の条件下のみであり、コンテキストを超えた汎化にはまず事前学習が必要であること、中間学習(Mid-training)が極めて重要であること、そしてプロセス認識型報酬(Process-aware rewards)が不可欠であることを指摘しています。これらの発見は、AIモデルのトレーニング戦略を最適化するための指針を提供し、推論能力を最大化するために異なる段階で的を絞ったアプローチを採用することの重要性を強調しています。 (来源: TheTuringPost)

KappaTune:LLMファインチューニングにおける壊滅的忘却問題を解決 : KappaTuneは、LoRAなどの既存の手法に存在する壊滅的な忘却問題を解決することを目的とした、LLMの新しいファインチューニング方法です。KappaTuneは、忘却の程度においてLoRAよりも6倍低く、事前学習データも不要です。この方法は、MoE(混合エキスパート)モデルのきめ細かいテンソル選択能力を利用して、その可能性を最大限に引き出します。KappaTuneの登場は、LLMの継続学習と適応性に対するより効率的なソリューションを提供し、モデルのメンテナンスコストを削減し、AIの普及を促進することが期待されます。 (来源: Reddit r/deeplearning)

Policy→Tests (P2T)フレームワーク:AIポリシーと実行可能ルールのギャップを埋める : Policy→Tests (P2T)フレームワークは、自然言語で記述されたAIガバナンスポリシー(EU AI法、NIST AI RMFなど)を実行可能なルールに変換することを目的としています。このフレームワークは、スケーラブルなパイプラインとコンパクトなJSON DSLを通じて、ポリシー文書を標準化された原子ルールに変換します。これには、リスク、範囲、条件、例外、証拠シグナル、および出所が含まれます。P2Tは、ポリシーの解釈とツール実行の間のボトルネックを解決し、特に医療データなどの複雑な分野を扱う際に、HIPAA要件をMLパイプラインチェックにマッピングするのに必要な時間を大幅に短縮し、AIガバナンスの効率と検証可能性を向上させることができます。 (来源: Reddit r/MachineLearning)
GenEnv:LLMエージェントと環境シミュレータの難易度整合による協調的進化 : GenEnvは、エージェントとスケーラブルな生成環境シミュレータの間で難易度を整合させた協調的進化ゲームを確立することで、LLMエージェントのトレーニングにおける実世界インタラクションデータの高コストと静的な性質というボトルネックを解決するフレームワークです。シミュレータは動的なカリキュラム戦略として機能し、エージェントの「最近接発達領域」に特化したタスクを継続的に生成し、α-カリキュラム報酬によってガイドされます。GenEnvは複数のベンチマークでエージェントの性能を最大40.3%向上させ、大規模モデルの平均性能を3.3倍少ないデータで達成または上回り、エージェント能力の拡張にデータ効率の良い道筋を提供します。 (来源: HuggingFace Daily Papers)
QuCo-RAG:事前学習コーパスから不確実性を定量化し、動的RAGを実現 : QuCo-RAGは、事前学習データから不確実性を定量化し、動的なRAGを実現することを提案しています。