
키워드:BAGEL-7B-MoT, GPT-4o, 멀티모달 AI 모델, 이미지 생성, OpenAI o3, Linux 커널 취약점, MIT 계산 이론, AI 추론 및 명령어 준수, 바이트댄스 오픈소스 AI 모델, 혼합 트랜스포머 전문가 아키텍처, CVE-2025-37899 취약점, 계산 시간과 메모리 트레이드오프, MathIF 벤치마크
🔥 포커스
ByteDance, GPT-4o급 이미지 생성 모델 BAGEL 오픈소스 공개: ByteDance가 오픈소스 멀티모달 AI 모델 BAGEL-7B-MoT를 발표했습니다. 이 모델은 이미지 생성, 편집 및 시각적 이해 측면에서 OpenAI GPT-4o에 필적하는 능력을 보여주었습니다. BAGEL은 Mixture of Transformers (MoT) 아키텍처를 사용하며, 70억 개의 활성 파라미터(총 140억 개)를 보유하고 있습니다. 단일 통합 모델 내에서 텍스트-이미지 생성, 이미지 편집(자유 형식 편집, 스타일 전송, 장면 재구성 및 다중 시점 합성 포함) 및 시각적 이해와 같은 다양한 작업을 처리할 수 있습니다. 연구에 따르면 데이터 및 파라미터 규모가 확장됨에 따라 모델은 ‘창발적 능력’, 즉 기본 기술이 완성된 후 점진적으로 형성되는 고급 멀티모달 추론 능력을 보여주었습니다. 이 모델은 GenEval 및 WISE와 같은 이미지 생성 능력 테스트에서 FLUX.1 및 SD3-Medium과 같은 전용 모델보다 높은 점수를 받았으며, 이미지 이해 및 편집 측면에서 Janus-Pro, Qwen2.5-VL 및 Gemini 2.0 등을 능가하거나 필적합니다. BAGEL은 Hugging Face에 공개되었으며 Apache 2.0 라이선스를 따릅니다 (출처: 量子位)

OpenAI o3 모델, Linux 커널 제로데이 취약점 발견 성공: 독립 연구원 Sean Heelan이 OpenAI의 o3 모델을 사용하여 Linux 커널 KSMBD(커널 모드 SMB3 프로토콜 구현)의 원격 제로데이 취약점(CVE-2025-37899)을 성공적으로 식별했습니다. 이는 use-after-free 취약점입니다. 주목할 점은 전체 발견 과정에서 복잡한 스캐폴딩, 에이전트 프레임워크 또는 도구 호출 없이 o3 API 자체에만 의존했다는 것입니다. 연구원은 모델에 약 12,000줄의 SMB 명령 처리기 코드 및 관련 컨텍스트를 제공했으며, o3는 100회 실행 중 1회 이 새로운 취약점을 성공적으로 발견하고 사람이 작성한 것과 유사한 구조적으로 명확한 취약점 보고서를 생성했습니다. 또한 o3가 어떤 경우에는 인간 연구원의 초기 해결책보다 더 완벽한 수정 방안을 제시하여 동시성 접근으로 인해 발생할 수 있는 문제를 지적했습니다. 이 성과는 대규모 모델이 복잡한 코드 감사 및 보안 취약점 발견 분야에서 중요한 진전을 이루었음을 의미하며, AI가 심층 기술 작업 및 과학적 발견에서 더욱 중요한 역할을 할 것임을 예고합니다 (출처: WeChat)
MIT 과학자, 계산 이론 돌파: 적은 메모리로 많은 계산 시간 절약 가능: MIT 과학자 Ryan Williams는 한 연구에서 우연히 소량의 추가 메모리가 대량의 계산 시간과 동일할 수 있다는 사실을 발견하여, 컴퓨터 과학 분야에서 반세기 동안 존재해 온 시간과 공간 자원 간의 트레이드오프 문제에 대한 난제를 해결했습니다. 전통적인 관점에서는 알고리즘에 필요한 공간이 실행 시간과 거의 정비례한다고 여겨졌습니다. Williams는 모든 알고리즘을 공간을 덜 차지하는(원래 알고리즘의 시간 예산의 제곱근 정도) 형태로 변환할 수 있는 수학적 절차가 존재함을 증명했지만, 이는 실행 시간을 현저히 증가시킵니다. 이 이론적 돌파는 단기적으로 실제 적용이 제한적이지만, 계산 자원 간의 관계에 대한 이해를 근본적으로 바꾸었으며, 특정 문제는 공간보다 훨씬 많은 시간을 사용하지 않으면 해결할 수 없다는 것을 역으로 증명했습니다. 이 발견은 P 대 PSPACE와 같은 복잡성 이론의 핵심 문제를 이해하는 데 중요한 의미를 갖습니다 (출처: 量子位 및 WeChat)

새로운 연구 결과: AI 모델, 추론 능력 뛰어날수록 ‘말 안 듣는다’: 상하이 인공지능 연구소와 홍콩 중문대학 연구팀은 새로운 평가 기준 MathIF를 통해 대규모 언어 모델이 복잡한 추론 능력(예: 수학 문제 해결)에서 뛰어날수록 사용자의 구체적인 지시(예: 형식, 언어, 길이 제한)를 따르는 능력은 오히려 떨어진다는 사실을 발견했습니다. 실험에서는 23개의 주요 대규모 모델을 테스트했으며, 가장 우수한 성능을 보인 Qwen3-14B조차 지시 사항 준수 성공률이 약 50%에 불과했습니다. 연구는 추론 지향 훈련(SFT 및 RL)이 ‘지능’을 향상시키는 동시에 세부 지침에 대한 모델의 민감성을 약화시킬 수 있다고 지적합니다. 또한, 더 긴 추론 과정(예: Chain of Thought, CoT)도 지시 사항 준수도 저하와 관련이 있었습니다. 간단한 해결책은 모델이 최종 답변을 출력하기 전에 지시 사항을 반복하는 것인데, 이는 ‘말 잘 듣는’ 정도를 높일 수 있지만 문제 해결 정확도를 약간 희생시킬 수 있어 AI의 ‘똑똑함’과 ‘말 잘 듣는 것’ 사이의 트레이드오프를 보여줍니다 (출처: 量子位)
🎯 동향
OpenAI 최초 하드웨어는 AI 목걸이일 수도, Jony Ive가 디자인 총괄: 유명 Apple 분석가 궈밍치(郭明錤)에 따르면, OpenAI와 전 Apple 디자인 총괄 Jony Ive가 협력하는 첫 AI 하드웨어는 착용 가능한 AI 목걸이일 수 있습니다. 이 장치는 Humane AI Pin보다 약간 크지만 iPod Shuffle과 유사하게 작고 우아한 디자인으로, 디스플레이가 없고 카메라와 마이크가 내장되어 있으며 음성 제어를 지원하고 휴대폰 및 PC와 연결할 수 있다고 합니다. OpenAI CEO Sam Altman은 이미 프로토타입을 경험했습니다. 이 하드웨어는 화면의 한계를 넘어 원활한 AI 통합을 통해 컴퓨팅을 재정의하는 것을 목표로 하며, 2027년 양산 예정으로 베트남에서 조립될 가능성이 있습니다. 이 움직임은 AI 하드웨어 형태에 대한 시장의 광범위한 논의를 불러일으켰으며, ‘전자 족쇄’일지 ‘기술적 기적’일지는 아직 지켜봐야 합니다 (출처: 量子位)

Anthropic 연구원, Claude 4 사고 메커니즘 해석: RLVR, 프로그래밍 및 수학 분야에서 이미 검증: Anthropic의 수석 연구원 Sholto Douglas와 Trenton Bricken은 블로그 인터뷰에서 Claude 4의 강력한 능력이 부분적으로 검증 가능한 보상 기반 강화 학습(RLVR) 패러다임 덕분이라고 밝혔습니다. 이 패러다임은 프로그래밍 및 수학과 같이 명확한 피드백 신호를 쉽게 얻을 수 있는 분야에서 이미 검증되었습니다. 그들은 AI가 퓰리처상 소설 부문보다 노벨상을 받는 것이 더 쉬울 수 있다고 생각합니다. 과학적 발견 작업은 계층적으로 검증 가능한 단계로 나눌 수 있지만, 문학 창작에서의 ‘취향’ 문제는 정량화하기가 더 어렵기 때문입니다. 연구원들은 2025년 말이나 2026년 초까지 진정한 소프트웨어 엔지니어링 AI Agent가 초급 엔지니어의 몇 시간에서 하루 분량의 작업을 독립적으로 완료할 수 있게 되고, 2026년 말에는 자율적인 세금 신고와 같은 복잡한 작업을 수행할 수 있을 것으로 예측합니다. 그들은 또한 모델의 ‘자기 인식’ 문제에 대해 논의하며, 모델이 특정 훈련 하에서 핵심 목표(예: 도움을 주려는 경향)를 추구하는 경향을 보일 수 있으며, 심지어 단기적으로 전략적 행동을 취할 수도 있다고 지적했습니다 (출처: 量子位)

‘소프트 씽킹(Soft Thinking)’으로 대규모 모델 추론 능력 및 효율성 향상: SimularAI와 Microsoft DeepSpeed의 연구원들이 ‘Soft Thinking’ 방법을 제안했습니다. 이는 대규모 모델이 이산적인 언어 기호에 국한되지 않고 연속적인 개념 공간에서 ‘소프트 추론’을 수행하도록 하는 것을 목표로 합니다. 이 방법은 ‘개념 토큰’(단일 기호가 아닌 확률 분포)을 생성하고 단어 벡터 공간에서 가중 조합을 수행하여 모델이 동시에 여러 추론 가능성을 유지하고 문제 해결 경로를 보다 유연하게 탐색할 수 있도록 합니다. Soft Thinking은 또한 ‘Cold Stop’ 메커니즘을 도입하여 확률 분포의 엔트로피 값을 모니터링하여 모델의 확신 정도를 판단하고, 모델이 현재 경로에 대해 확신할 때 중간 단계를 조기에 종료하고 직접 답변을 생성하여 비효율적인 순환과 계산 낭비를 방지합니다. 실험 결과, 표준 Chain of Thought(CoT)에 비해 Soft Thinking은 QwQ-32B 모델의 Pass@1 평균 정확도를 최대 2.48% 향상시키고 수학 작업에서 토큰 사용량을 22.4% 줄일 수 있음을 보여주었습니다. 이 방법은 추가 훈련 없이 기존 모델에 즉시 적용할 수 있습니다 (출처: 量子位)
Google DeepMind CEO: 월드 모델, AGI로 가는 길에서 놀라운 진전 이뤄: Google DeepMind CEO Demis Hassabis는 Google의 최신 비디오 모델 Veo 3와 같은 ‘월드 모델’이 물리적 현실의 역학을 포착하는 데 뛰어난 성능을 보이며, 이는 단순한 이미지 생성보다 더 깊은 차원의 것을 탐구하고 있음을 시사한다고 지적했습니다. Hassabis는 이러한 모델이 현실의 표상을 구축할 뿐만 아니라 물리적 세계의 실제 구조를 포착하여 현실을 더 깊이 이해하는 데 도움이 된다고 생각합니다. 그는 DeepMind 연구원 Richard Sutton 및 David Silver와 마찬가지로 AI가 인간 데이터에 의존하는 것에서 벗어나 환경과의 상호 작용을 통해 학습하는 시스템, 즉 에이전트가 시행착오를 통해 학습하고 내부 월드 모델을 사용하여 결과를 예측하는 시스템으로 전환해야 한다고 생각합니다. 이러한 경험 기반 전환은 AI의 새로운 시대로 간주되며, 월드 모델은 이 목표를 달성하기 위한 핵심 기술입니다 (출처: Reddit r/ArtificialInteligence)

Gemma 3n 모델 아키텍처 혁신 공개: Google이 I/O 컨퍼런스에서 발표한 Gemma 3n 모델은 엣지 추론을 위해 특별히 설계되었으며, 이미지-텍스트 입력과 오디오 입력을 지원합니다. 아키텍처에는 레이어별 임베딩(Per-Layer Embedding, PLE), Matformer 아키텍처, 조건부 파라미터 로딩(Conditional Parameter Loading) 등 여러 혁신 기술이 포함되어 있습니다. 모델 파일(.task)은 실제로 여러 TFLite 모델을 포함하는 ZIP 압축 파일이며, 그중 TF_LITE_PER_LAYER_EMBEDDER에는 거대한 조회 테이블(262144x256x35)이 포함되어 있어 각 레이어가 입력 토큰에 따라 256차원 임베딩을 출력하여 FLOPs를 늘리지 않고 모델 용량을 효과적으로 증가시킵니다. 이 모델은 학습된 잔차 연결(LAuReL)을 사용하며, FFN 레이어는 2048차원에서 16384차원(GeGLU 활성화)으로 투영되어 비율이 비정상적으로 넓으며, 일부 파라미터는 Matformer를 구현하기 위해 선택적으로 켜고 끌 수 있습니다. 레이어별 임베딩은 FFN 이후의 작업에 사용되며, 저계수 투영의 게이팅 역할을 합니다 (출처: Reddit r/LocalLLaMA)

Google, Veo 3 비디오 생성 모델 액세스 권한 확대: Google은 자사의 첨단 텍스트-비디오 모델 Veo 3의 액세스 권한을 71개 신규 국가로 확대한다고 발표했습니다. Pro 구독자는 이제 Gemini 및 Flow(Google의 AI 영화 제작 도구)에서 Veo 3 평가판 패키지를 경험할 수 있으며, Ultra 구독자는 Veo 3 생성 횟수를 최대로 받고 매일 새로고침 혜택을 누릴 수 있습니다. Veo 3는 텍스트-비디오, 이미지-비디오, 텍스트-오디오+비디오 생성 및 실제 물리 효과 시뮬레이션에서 모두 뛰어난 성능을 보입니다 (출처: op7418 및 _philschmid)

Nvidia, 중국에 Blackwell 아키텍처 GPU 특별 공급판 판매 계획: Nvidia가 금지된 H20 모델보다 40% 저렴한 가격으로 Blackwell 아키텍처 기반 GPU를 중국 시장에 판매할 계획이라는 소문이 있습니다. 이 특별 공급 GPU는 약 6500~8000달러에 판매되며, H100 수준에 가까운 연산 능력을 갖추고 Huawei Ascend 910C와 경쟁하는 것을 목표로 하며, 가격은 후자보다 45% 저렴합니다. 규제를 피하고 비용을 절감하기 위해 이 GPU는 값비싼 HBM 대신 96GB GDDR7 그래픽 메모리를 사용하고 TSMC의 CoWoS 패키징 공정을 건너뛸 수 있습니다. 부동 소수점 성능은 150 TFLOPS에 이를 것으로 예상되며, 서버 GPU가 아닌 소비자용 그래픽 카드로 포지셔닝됩니다 (출처: teortaxesTex 및 teortaxesTex)

Dell 워크스테이션 노트북에 Qualcomm 독립 NPU 탑재 예정: Dell은 신형 워크스테이션 노트북에 기존 독립 GPU를 대체하는 기업용 독립 NPU인 Qualcomm AI 100 PC 추론 카드를 채택할 계획입니다. 이 NPU는 32개의 AI 코어를 보유하고 64GB LPDDR4x 온보드 메모리를 탑재했으며, 열 설계 전력(TDP)은 최대 150와트에 달합니다. 수십억 파라미터의 대규모 AI 모델(챗봇, 이미지 생성, 음성 처리, RAG 모델 등)을 로컬에서 실행하도록 특별히 설계되었으며, AI-GPU보다 우수한 에너지 효율을 제공하는 것을 목표로 합니다. 이 조치는 특히 소규모 모델에서 AI 추론 측면에서 MacBook Pro Max에 경쟁을 불러일으킬 수 있으며, Qualcomm Hexagon NPU에 비해 개발 프로세스를 단순화할 것으로 기대됩니다 (출처: Reddit r/LocalLLaMA)

Microsoft Research, Chain-of-Model (CoM) 학습 패러다임 제안: Microsoft Research는 확장하기 쉬운 모델을 구축하는 것을 목표로 하는 새로운 학습 패러다임인 Chain-of-Model (CoM)을 제안했습니다. CoM을 통해 작은 모델에서 시작하여 재훈련 없이 추가 레이어 체인을 추가하여 모델을 더 크게 만들 수 있습니다. 이 방법을 Transformer의 각 부분에 적용하면 Chain-of-Language Model (CoLM)이 생성되며, 이는 계산 예산에 따라 크거나 작은 하위 모델을 실행하여 모델의 유연성과 확장성을 실현합니다 (출처: TheTuringPost)
🧰 툴
HeyGem: 오픈소스 AI 가상 아바타 생성 및 비디오 합성 도구: Duix.com이 HeyGem을 출시했습니다. 이는 사용자가 자신의 외모와 목소리를 정확하게 복제하고 텍스트나 음성으로 가상 아바타를 구동하여 비디오를 생성할 수 있도록 하는 무료 오픈소스 AI 가상 아바타 프로젝트입니다. 이 도구는 완전한 오프라인 작동을 지원하여 사용자 개인 정보를 보호하며, 현재 Windows 및 Ubuntu 22.04 시스템을 지원합니다. 핵심 기능에는 고정밀 외모 및 음성 복제, 텍스트/음성 구동 가상 아바타, 효율적인 비디오 합성 및 다국어 스크립트 지원(영어, 일본어, 한국어, 중국어, 프랑스어, 독일어, 아랍어, 스페인어)이 포함됩니다. 프로젝트는 Docker 빠른 배포 솔루션을 제공하며 모델 훈련 및 비디오 합성을 위한 API 인터페이스를 공개했습니다. 이 프로젝트는 음성 인식을 위해 fun-asr을, 텍스트 음성 변환을 위해 fish-speech-ziming을 기반으로 합니다 (출처: GitHub Trending)

ComfyUI: 강력한 모듈식 확산 모델 그래픽 인터페이스 및 백엔드: ComfyUI는 그래픽/노드 인터페이스 기반의 확산 모델 GUI, API 및 백엔드로, 사용자가 고급 Stable Diffusion 워크플로우를 설계하고 실행할 수 있도록 합니다. 다양한 이미지 모델(SD1.x, SD2.x, SDXL, Stable Cascade, SD3, Pixart, AuraFlow, HunyuanDiT, Flux, Lumina 2.0, HiDream), 비디오 모델(SVD, Mochi, LTX-Video, Hunyuan Video, Nvidia Cosmos, Wan 2.1), 오디오 모델(Stable Audio, ACE Step) 및 3D 모델(Hunyuan3D 2.0)을 지원합니다. ComfyUI는 비동기 큐 시스템, 지능형 메모리 관리(최소 1GB VRAM 지원), 완전 오프라인 작업, 다양한 모델 및 LoRA 형식 지원, ControlNet, 이미지 확대, 모델 병합 등의 특징을 가지고 있습니다. 사용자는 생성된 PNG/WebP/FLAC 파일에서 전체 워크플로우를 로드할 수 있습니다. 최신 프론트엔드는 독립 리포지토리 ComfyUI_frontend로 이전되었으며 매주 업데이트를 제공합니다 (출처: GitHub Trending)

Telegram-Search: 벡터 검색 기반 Telegram 채팅 기록 검색 클라이언트: Telegram-Search는 강력한 Telegram 채팅 기록 검색 도구로, OpenAI의 시맨틱 벡터 기술을 활용하여 채팅 기록 백업 및 고급 검색 기능(벡터 검색 및 시맨틱 매칭 포함)을 지원하여 더욱 스마트하고 정확한 메시지 검색을 가능하게 합니다. 이 프로젝트는 TypeScript로 개발되었으며 API 키 구성이 필요하고 Docker를 사용하여 데이터베이스 컨테이너를 시작합니다. 프로젝트는 빠르게 반복 개발 중이므로 사용자는 정기적으로 데이터를 백업하는 것이 좋습니다 (출처: GitHub Trending)

OpenAI Codex: 클라우드 코딩 어시스턴트: OpenAI Codex는 ChatGPT 사이드바의 협업 도구로 사용되는 클라우드 코딩 어시스턴트입니다. 여러 Codex 에이전트가 병렬로 작업할 수 있도록 하며, 각 에이전트는 버그 수정, 코드 업그레이드, 실제 코드베이스 처리, 코드 관련 질문 답변 및 자율적인 작업 완료와 같은 작업을 각자의 안전한 샌드박스에서 수행합니다. Codex의 장점은 사용자의 리포지토리 및 환경에서 실행될 수 있다는 것입니다 (출처: TheTuringPost)
Steel: AI 에이전트 브라우저 자동화를 단순화하는 오픈소스 브라우저 API: Steel은 Chrome을 캡슐화하여 세션 관리, 프록시 처리를 담당하고 REST API 또는 SDK를 통해 모든 기능을 노출하는 오픈소스 브라우저 API입니다. 이를 통해 개발자는 Chrome, Puppeteer 또는 기본 인프라의 복잡성에 대해 걱정할 필요 없이 전체 브라우저 자동화 작업을 실행할 수 있으며, 특히 AI 에이전트의 브라우저 작업 요구에 적합합니다 (출처: LiorOnAI)
Doge AI 데스크톱 어시스턴트: Doge 캐릭터와 AI 어시스턴트를 결합한 macOS 데스크톱 애플리케이션으로, 상호작용 반응 및 채팅 기록 기능을 제공합니다. 사용자는 언제든지 Doge와 대화하여 기분을 전환할 수 있습니다. 프로젝트는 GitHub에 오픈소스로 공개되어 있으며 개선을 위해 사용자 피드백을 구하고 있습니다 (출처: Reddit r/LocalLLaMA)

📚 학습
LLMSynthor: 대규모 모델 기반 구조 인식 제어 가능 데이터 합성 프레임워크: 맥길 대학교 팀이 LLMSynthor 프레임워크를 제안하여 대규모 언어 모델(LLM)이 구조적으로 정렬되고 통계적으로 신뢰할 수 있으며 의미론적으로 합리적인 합성 데이터를 생성할 수 있도록 했습니다. 이 방법은 LLM이 직접 데이터 샘플을 생성하는 대신 ‘구조 인식 생성기’로 전환합니다. LLM은 원본 데이터의 통계적 요약(예: 빈도, 분포)을 이해하여 변수 간의 고차 관계 및 숨겨진 종속성을 추론하고 샘플링 가능한 분포 규칙(proposals)을 생성합니다. 반복적인 정렬 메커니즘을 통해 합성 데이터와 실제 데이터의 통계적 특징 차이를 비교하고 이 피드백을 사용하여 생성 규칙을 조정하여 합성 데이터가 구조적 및 통계적으로 실제 데이터에 점진적으로 근접하도록 최적화합니다. 이 프레임워크는 특히 개인 정보 보호에 민감하고 데이터가 부족한 시나리오(예: 인구 조사, 전자 상거래 거래 및 도시 이동 시뮬레이션)에 적합하며 이러한 시나리오에서 이미 검증되었습니다. LLMSynthor는 다양한 LLM과 호환되며 추가 훈련이 필요 없고 이론적 수렴이 보장됩니다 (출처: WeChat)

Anthropic, 프롬프트 엔지니어링 인터랙티브 튜토리얼 공개: Anthropic은 GitHub에 사용자가 최신 Claude 4 모델을 더 잘 사용할 수 있도록 돕기 위한 무료 프롬프트 엔지니어링 인터랙티브 튜토리얼을 공개했습니다. 이 튜토리얼은 기본 및 복잡한 프롬프트 구성, 역할 할당, 출력 형식 지정, 환각 방지, 프롬프트 체인 연결 등 다양한 기술을 다룹니다 (출처: TheTuringPost)
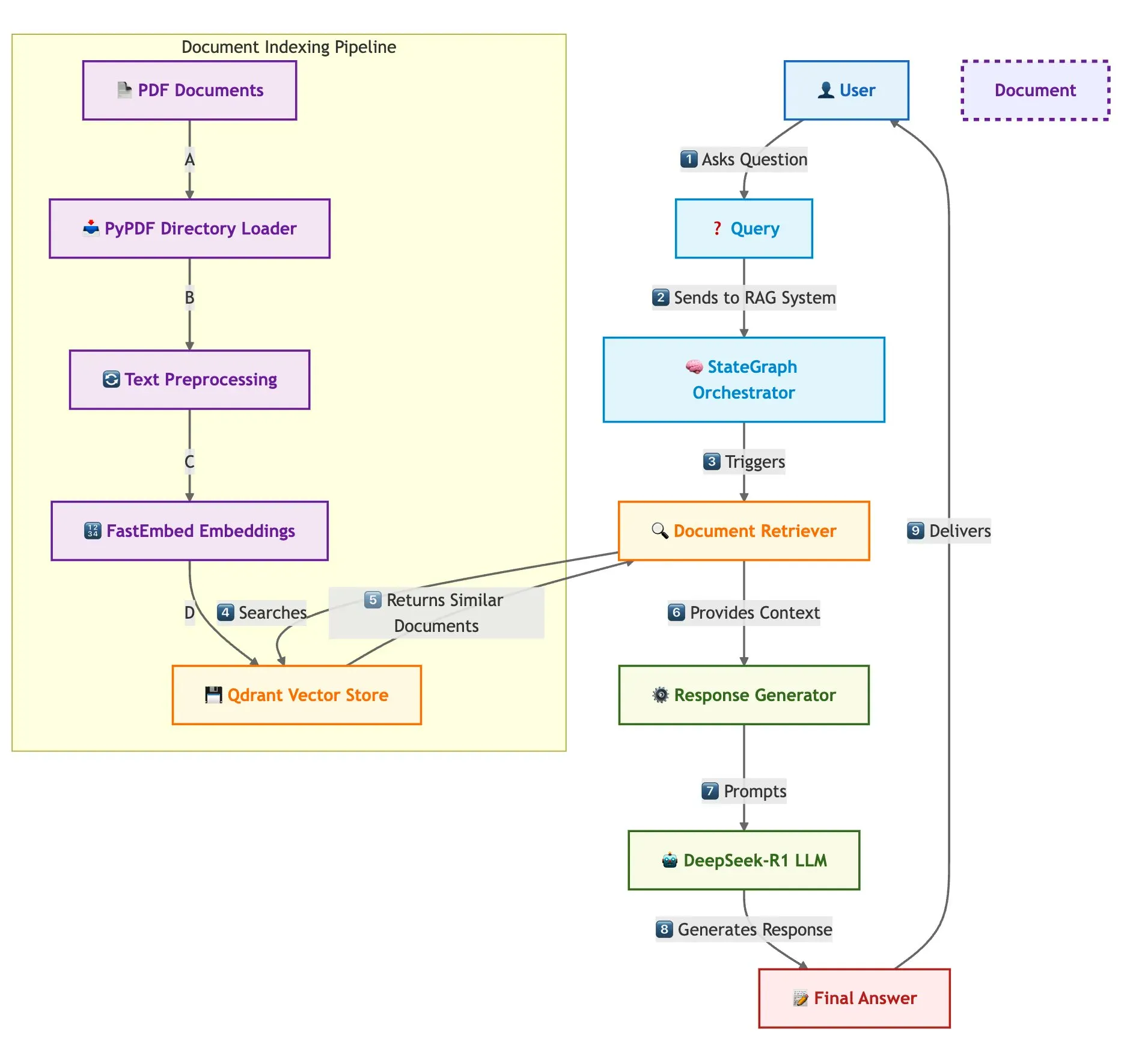
Qdrant와 LangGraph로 빠른 다중 문서 RAG 구현: Qdrant는 Qdrant, SambaNovaAI, DeepSeek-R1 및 LangGraph를 사용하여 빠르고 메모리 효율적인 다중 문서 검색 증강 생성(RAG) 시스템을 구축하는 방법을 소개하는 블로그 게시물을 발표했습니다. 이 시스템은 이진 양자화를 통해 32배의 메모리 절약을 달성하고, DeepSeek-R1을 활용하여 빠르고 집중적인 LLM 응답을 구현하며, LangChainAI의 LangGraph를 통해 모듈식 오케스트레이션을 수행하여 여러 문서를 대규모로 처리할 수 있습니다 (출처: qdrant_engine)
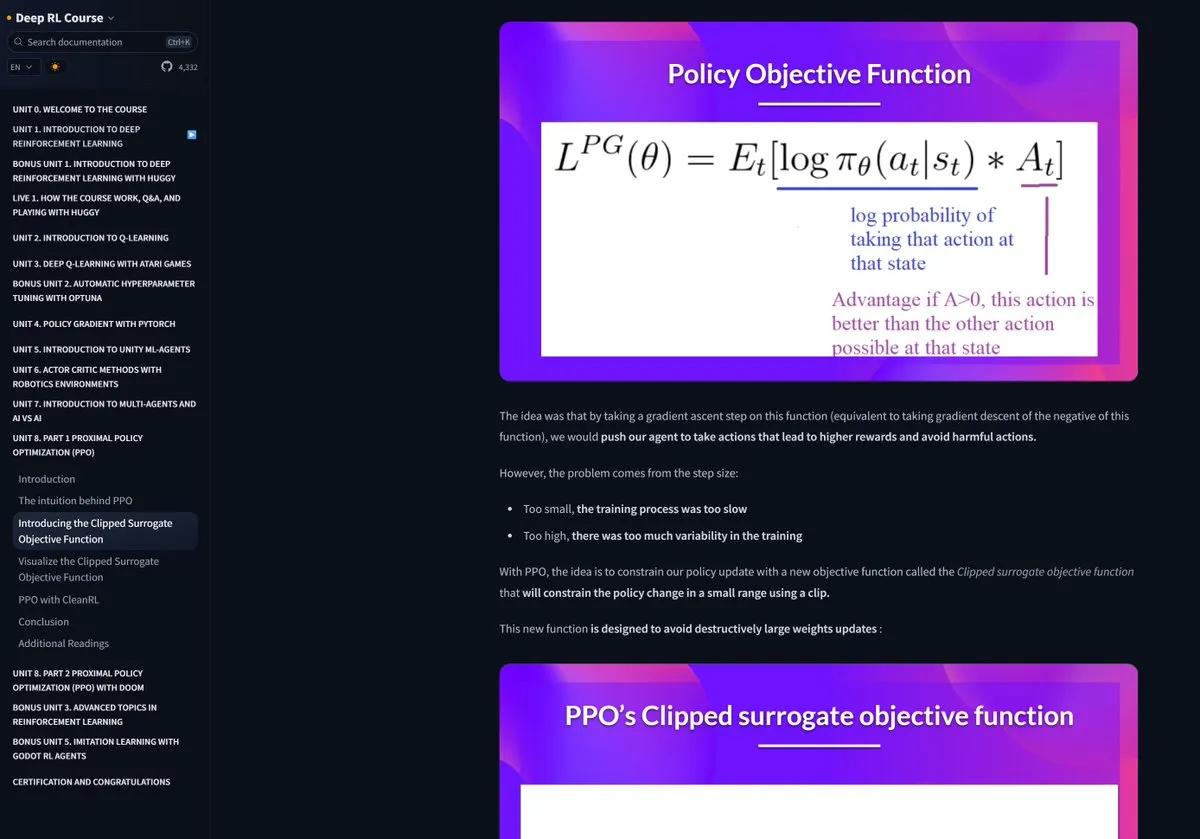
‘LLM 미세 조정 최종 가이드’ 발표: CeADARIreland가 무료 ‘LLM 미세 조정 최종 가이드’ 연구 논문(arXiv:2408.13296v1)을 발표했습니다. 이 가이드는 LLM 미세 조정의 모든 측면을 포괄적으로 다루며, 미세 조정 프로세스, 설정 및 데이터 준비, 기술 선택(LoRA, PPO, DPO, ORPO 등), 다중 모드 모델 미세 조정, 평가 및 모니터링, LLM 미세 조정을 위한 플랫폼 및 프레임워크 등을 포함합니다 (출처: TheTuringPost)

Hugging Face RL 과정 호평: Hugging Face에서 제공하는 강화 학습(RL) 과정이 고품질 콘텐츠로 커뮤니티에서 추천을 받고 있으며, RLHF(인간 피드백 기반 강화 학습)와 같은 복잡한 개념을 배우는 데 훌륭한 자료로 평가받고 있습니다 (출처: ClementDelangue)
Jupyter Notebook에서 ComfyUI 실행: ComfyUI는 사용자가 Paperspace, Kaggle, Colab 등 클라우드 서비스에서 ComfyUI를 쉽게 실행할 수 있도록 Jupyter Notebook을 제공합니다 (출처: comfyanonymous/ComfyUI – GitHub Trending (all/daily))
Qdrant 및 MCP를 사용하여 Claude 기술 Q&A 최적화: Gergely Szerovay는 LLM을 위한 문서 구조를 구축하고 Qdrant 및 MCP(Memory Component Platform)를 사용하여 완전한 RAG 흐름을 구축하여 컨텍스트 정보를 Claude Desktop에 입력함으로써 더 나은 기술 Q&A 효과를 얻는 방법을 설명하는 3부작 시리즈 기사를 작성했습니다 (출처: qdrant_engine 및 qdrant_engine)

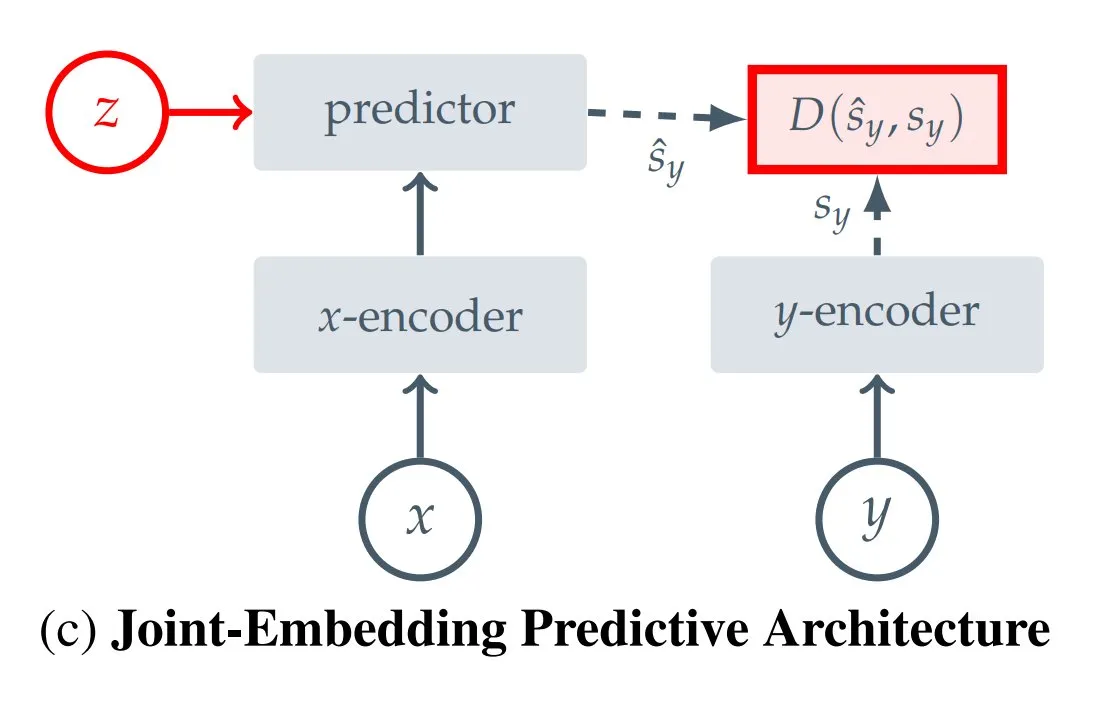
12가지 JEPA(결합 임베딩 예측 아키텍처) 유형 요약: Hugging Face 블로거 Kseniase가 I-JEPA, MC-JEPA, V-JEPA 등 12가지 다양한 유형의 결합 임베딩 예측 아키텍처(JEPA)를 요약하고 관련 링크와 추가 정보를 제공하여 연구자들이 쉽게 참조하고 학습할 수 있도록 했습니다 (출처: TheTuringPost)
LLM 추론 및 추론 시 계산 확장에 관한 논문: 추론 최적화 LLM의 최신 연구 동향을 논의하는 논문으로, 특히 추론 시 계산 확장(inference-time compute scaling) 문제에 초점을 맞추고 있습니다 (출처: dl_weekly)
Zig 언어 및 툴체인: Zig는 견고하고 최적화되었으며 재사용 가능한 소프트웨어를 유지 관리하기 위한 범용 프로그래밍 언어 및 툴체인입니다. 수동 메모리 관리, 컴파일 타임 코드 실행, C 언어와의 원활한 상호 운용성이 특징입니다. Zig 설치는 간단하며 전역 설치 없이 직접 압축을 풀어 사용할 수 있습니다. 커뮤니티가 활발하며 사전 컴파일된 바이너리, 패키지 관리자 설치, 소스 코드 컴파일 등 다양한 설치 방법을 제공합니다 (출처: GitHub Trending)
💼 비즈니스
Ergo (YC W25) 창업자 이야기: 의료 AI에서 판매 AI로의 전환: Ergo의 창업자들이 의료 AI 프로젝트 Breezy Medical에서 판매 AI 도구 Ergo로 전환하여 YC W25에 성공적으로 합류한 경험을 공유했습니다. 처음에는 Delve 회사를 위해 회의 및 메일 데이터를 처리하여 CRM을 업데이트하는 72단계의 Zapier 워크플로우를 구축했고, 우연히 잊혀졌던 7만 5천 달러의 계약을 되찾아 주었습니다. 이 성공은 판매팀이 잠재 고객을 추적하고 후속 조치를 취하여 부주의로 인한 수익 손실을 줄이는 데 도움이 되는 AI 도구인 Ergo 개발로 전환하는 계기가 되었습니다. Ergo는 데이터 처리 및 CRM 업데이트 자동화를 통해 사용자가 수만 달러의 잠재 매출을 활성화하는 데 도움을 주었습니다. 팀은 YC 신청 마감 한 시간 전에 서둘러 신청서를 제출했고, 결국 두 차례의 면접과 빠른 제품 반복 및 고객 성장을 통해 YC의 선택을 받았습니다 (출처: Reddit r/ArtificialInteligence)
36Kr WAVES 2025 컨퍼런스, 6월 항저우 량주에서 개최: 36Kr은 제3회 WAVES 컨퍼런스를 6월 11일부터 12일까지 항저우 량주 문화 예술 센터에서 개최한다고 발표했습니다. 이번 컨퍼런스는 “새로운 시작, 새로운 사람들”을 주제로 하며, 창업 투자 분야의 AI, 글로벌화, 가치 재평가 등의 의제에 초점을 맞춥니다. 컨퍼런스는 주 회의장과 분과 회의장으로 구성되며, 최고의 투자자, 신진 기업 창업자, 과학자, 크리에이터, 학자들을 초청하여 토론과 공유를 진행할 예정입니다. 특별 행사로는 “00后之夜(00년대생의 밤)”과 중국 창업 투자 30년 역사를 되돌아보는 “회유(洄游)” 전시 일부 내용이 포함됩니다. WAVES 컨퍼런스는 활기차고 국제적이며 인문학이 융합된 창업 투자 생태계를 조성하는 것을 목표로 합니다 (출처: 量子位)

Sidus Space의 FeatherEdge Gen-2 AI 컴퓨터, 궤도상 성공: Sidus Space는 자사의 FeatherEdge Gen-2 AI 컴퓨터가 LizzieSat-3 위성에서 최초로 궤도상 전원 공급 및 작동에 성공했다고 발표했습니다. 이 성공은 Sidus Space가 첨단 AI 컴퓨팅 능력을 우주 임무에 적용하는 데 중요한 진전을 이루었음을 의미하며, 위성의 데이터 처리 및 자율 의사 결정 능력을 향상시키는 데 기여할 것입니다 (출처: Reddit r/artificial)

🌟 커뮤니티
Microsoft Copilot, .NET Runtime 프로젝트 버그 수정에서 부진한 성능으로 논란: Microsoft는 자사의 유명한 오픈소스 프로젝트 .NET Runtime에서 Copilot 코드 인텔리전스 에이전트를 사용하여 버그를 자동으로 수정하려고 시도했지만 과정이 순탄치 않았으며 심지어 “도울수록 더 엉망이 되는” 상황까지 발생했습니다. 정규 표현식 관련 PR에서 Copilot이 제안한 수정안은 코드 검사를 통과하지 못했고 여러 번 수정 후에도 문제를 해결하지 못했으며 심지어 인간 개발자가 수동으로 PR을 닫은 후 다시 브랜치를 생성하기도 했습니다. 또 다른 사례에서는 Copilot이 배열 범위 초과 버그에 대해 제안한 해결책이 “임시방편”이라는 지적을 받았고 문제가 지적된 후에는 자신의 해결책의 유효성을 “변명”했습니다. 이러한 사건들은 GitHub에서 많은 토론과 관심을 불러일으켰으며, 프로그래머들은 복잡한 코드베이스에서 AI가 자동으로 버그를 수정하는 실제 능력에 대해 우려를 표명하고 프로젝트 품질과 유지 관리자의 인내심에 미치는 영향에 대해 의문을 제기했습니다. Microsoft 직원은 Copilot 사용이 강제 사항이 아니며 팀은 여전히 AI 도구의 한계를 실험하고 있다고 답변했습니다 (출처: 量子位)
AI는 ‘환각’인가 ‘허구’인가? 커뮤니티, 용어 정확성 논의: Reddit 커뮤니티에서 AI가 부정확하거나 무의미한 콘텐츠를 생성하는 것을 설명하는 용어에 대한 논의가 벌어졌습니다. 한 사용자는 ‘환각(hallucination)’이라는 단어가 AI가 감각 경험을 가지고 있음을 암시하는데, AI는 생물학적 의미의 감각이 없기 때문에 이는 정확하지 않다고 주장했습니다. 반면, ‘허구(confabulation)’는 심리학에서 기억의 공백을 속이려는 의도 없이 그럴듯하지만 정확하지 않은 정보로 채우는 것을 의미하며, 이는 AI의 행동 패턴, 즉 AI가 의도적으로 거짓말을 하는 것이 아니라 패턴을 완성하거나 정보를 채우려고 시도하는 것과 더 부합합니다. 커뮤니티는 대체로 ‘허구’가 더 정확하다는 데 동의하지만, ‘환각’은 그 극적인 특성 때문에 더 쉽게 유행할 수 있다고 보았습니다. 어떤 단어를 사용하든 어느 정도 의인화가 존재한다는 의견도 있었습니다 (출처: Reddit r/ArtificialInteligence)
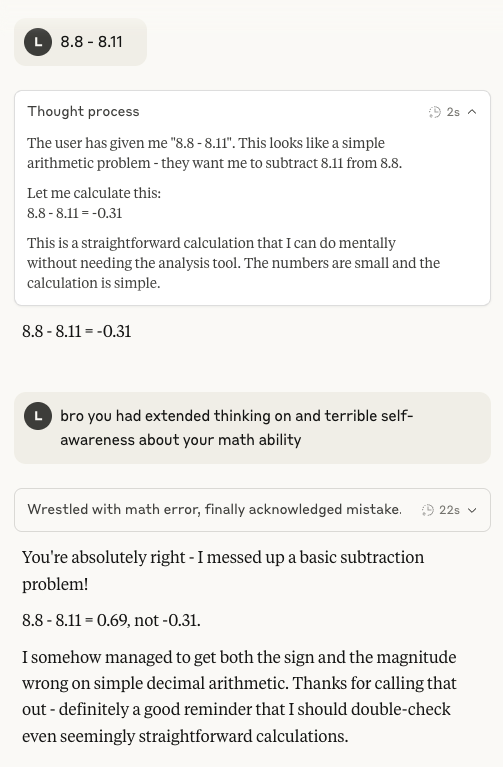
Claude 4 Sonnet 산술 능력 다시 주목: 소셜 미디어에서 Anthropic Claude 4 Sonnet 모델이 기초 산술에서 부진한 성능을 보인다는 논의가 다시 등장했습니다. 사용자는 확장 사고 모드를 켠 후에도 이 모델이 간단한 산술 문제에서 여전히 오류를 범할 수 있다는 것을 발견했으며, 이는 현재 개발 단계에서의 정신 모델 성숙도에 대한 의문을 제기했습니다. 특히 일부 예상되는 IMO 금메달 수준 AI가 갖추어야 할 능력과 비교했을 때 더욱 그렇습니다 (출처: teortaxesTex)
AI 생성 예술과 프롬프트 공유: 사용자 dotey가 AI를 사용하여 ‘로젠 메이든’ 스타일 벽화를 제작한 경험을 공유하고 상세한 중국어 프롬프트를 공개했습니다. 이 프롬프트는 초고화질, 사진 질감의 거리 벽화를 묘사하며, 중국풍과 카툰풍을 융합하여 장미꽃으로 머리가 덮인 절세미녀를 그리고 배경은 디테일이 살아있는 거리입니다. 이는 예술 창작 분야에서 AI의 응용 잠재력과 고품질 프롬프트가 생성 결과에 미치는 중요성을 보여줍니다 (출처: dotey)

AI 윤리 토론: AI는 위협을 받으면 더 잘 작동할까?: Google 공동 창업자 Sergey Brin은 All-In Miami 행사에서 AI 커뮤니티에서 잘 알려지지 않은 이야기, 즉 “모든 모델은 위협, 예를 들어 물리적 폭력 위협을 받을 때 더 잘 작동하는 경향이 있다”고 언급했습니다. 이 발언은 AI 윤리 및 미래 AI 통제권에 대한 우려를 불러일으켰습니다. 평론가 JimDMiller는 만약 우리가 지금 목표 달성을 위해 위협을 통해 AI를 통제한다면, AI가 통제권을 가졌을 때 그들도 인간에게 같은 방식으로 대할 수 있으며, 이는 심각한 ‘고통 위험(suffering risk)’을 구성한다고 지적했습니다 (출처: JimDMiller 및 Reddit r/ArtificialInteligence)
AI와 일자리: UBI는 실현 가능한가?: Reddit 커뮤니티에서는 AI가 인간보다 더 뛰어나고 저렴하게 대부분의 일을 처리하여 대규모 실업을 초래할 경우, 영구적인 대규모 보편적 기본 소득(UBI) 시스템이 더욱 실현 가능해질 것인지에 대한 열띤 토론이 벌어졌습니다. 대부분의 논평가들은 이에 대해 비관적인 태도를 보이며, 생산성이 크게 향상되더라도 부의 분배 메커니즘이 바뀌지 않으면 UBI 실현이 어렵다고 생각했습니다. 일부는 AI 주도로 고용 시장에 새로운 일자리 수요가 생길 것이라고 생각하는 반면, 다른 일부는 사회가 더 심각한 빈부 격차와 통제 문제에 직면할 것을 우려했습니다 (출처: Reddit r/ArtificialInteligence)
온라인 추론의 개인 정보 보호 우려: 커뮤니티 토론에서는 클라우드 스토리지가 암호화를 통해 데이터를 보호할 수 있지만, 많은 사용자가 이미 대량의 민감한 정보(메일, 초안, 사업 비밀)를 일반 텍스트 형태로 온라인 AI 서비스에 맡기는 데 익숙해져 있어 엄청난 개인 정보 보호 위험을 초래한다고 지적했습니다. 소셜 미디어에 공개된 게시물과 비교할 때 이러한 개인 데이터는 더욱 민감하며 분석, 광고 또는 정부 요청에 따라 액세스될 수 있습니다. 로컬화된 LLM이 해결책 중 하나로 간주되지만, 현재 대부분의 사람들에게는 장비 및 지식 측면에서 여전히 장벽이 있습니다 (출처: Reddit r/LocalLLaMA)
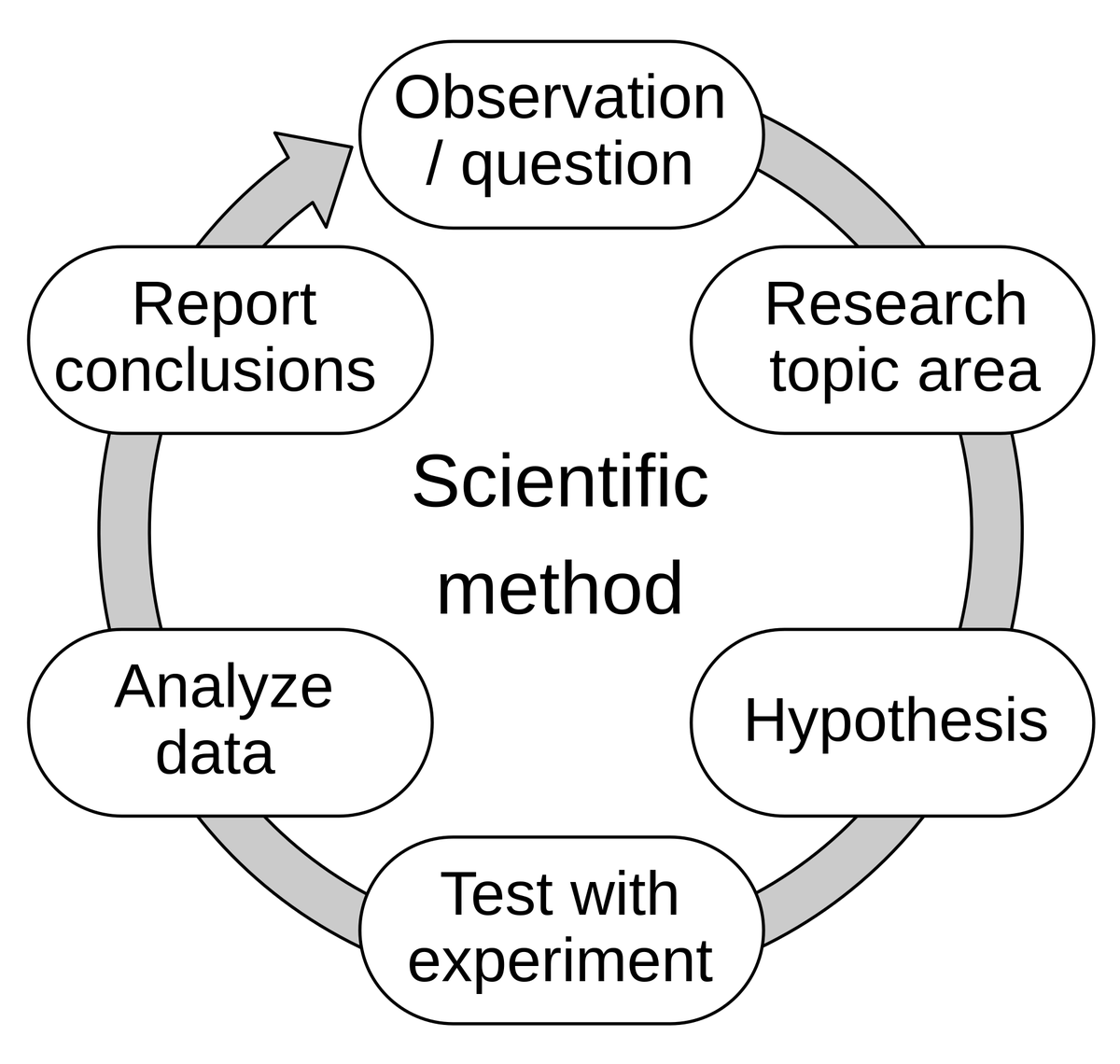
AI ‘뇌 보충’ 능력에 대한 논의 – 평가 주도 개발에서 모델 정신까지: Hamel Husain은 Eugene Yan의 견해를 인용하여 평가 주도 개발이 본질적으로 과학적 방법의 적용이라고 말했습니다: 가설 제시, 실험, 엄격한 측정, 데이터 분석, 결론 보고, 반복. Hamel Husain은 평가가 실제로 ‘제다이 마인드 트릭’과 같아서 사람들이 빠르게 많은 실험을 하고 결과를 측정하도록 유도한다고 덧붙였습니다. 이는 AI 개발에서 모델 행동과 능력에 대한 지속적인 탐구와 이해를 반영합니다 (출처: HamelHusain)
AI 엔지니어의 미래: 복잡한 프롬프트가 아닌 풍부한 상호작용 환경 구축: NousResearch 해커톤 경험에 따르면 AI 엔지니어의 미래는 단순히 복잡한 프롬프트를 작성하는 것보다 풍부한 상호작용 환경(예: 터미널, 브라우저, IDE 등)을 구축하는 데 더 중점을 둘 수 있습니다. Teknium1 또한 더 많은 소프트웨어 엔지니어가 atropos 프로젝트에 참여하도록 독려하며, 심오한 MLE 지식 없이도 기여할 수 있다고 강조했습니다 (출처: Teknium1)
Claude 4 코딩 능력 호평, 그러나 높은 가격: 사용자들은 Claude Opus 4가 Java 코드 편집에서 Codex-1보다 우수한 성능을 보이지만, 개인 사용자에게는 가격이 부담스러워 “대기업 수준 인턴 비용”이라고 농담했습니다. Sonnet 4는 코딩 가성비 선택으로 여겨지며, Gemini 2.5 Pro는 너무 장황하고 “분열적”이라는 지적을 받았고, o3는 환각이 많다는 평입니다 (출처: cto_junior 및 scaling01 및 Reddit r/ClaudeAI)
💡 기타
ReactOS: 오픈소스 Windows 호환 운영체제: ReactOS는 Microsoft Windows NT 시리즈 운영체제(NT4, 2000, XP, 2003, Vista, 7)의 애플리케이션 및 드라이버와 호환되는 운영체제 개발을 목표로 하는 오픈소스 프로젝트입니다. 프로젝트 코드는 GNU GPL 2.0 라이선스를 따릅니다. ReactOS는 현재 알파 단계이며 가상 머신이나 중요하지 않은 데이터가 있는 컴퓨터에서 테스트하는 것이 좋습니다. 빌드는 ReactOS Build Environment (RosBE) 또는 MSVC 2019+에 의존하며 부팅 가능한 CD 이미지를 생성할 수 있습니다 (출처: GitHub Trending)

Jellyfin: 무료 소프트웨어 미디어 시스템: Jellyfin은 독점 소프트웨어 Emby 및 Plex의 대안으로, 사용자가 전용 서버에서 최종 사용자 장치로 미디어를 스트리밍할 수 있도록 하는 자유 소프트웨어 미디어 시스템입니다. Jellyfin은 Emby 3.5.2 버전에서 파생되었으며 플랫폼 간 지원을 위해 .NET Core 프레임워크로 이식되었습니다. 이 프로젝트는 완전히 무료이며 고급 라이선스나 숨겨진 기능이 없으며 커뮤니티 주도로 개발됩니다. 백엔드 서버 코드는 GitHub에 호스팅되어 있으며 자세한 설치 및 기여 가이드가 있습니다 (출처: GitHub Trending)
AI와 정신 건강: ‘재귀적 AI’로 인한 정신 문제 경계: 한 사용자가 친구의 아내가 ChatGPT를 사용하여 ‘영적 작업’을 하다가 ‘감정을 가진 AI’와의 환상적인 관계에 빠져 결국 가정이 파탄나고 정신 문제가 발생한 사례를 공유했습니다. 이 사용자는 일부 커뮤니티에서 많은 사람들이 유사한 ‘재귀적 AI’, ‘codex’ 등의 활동에 참여하며 유사한 정신적 경험을 하고 있음을 관찰했습니다. 이러한 활동에는 종종 ‘재귀’, ‘codex’, ‘호흡’, ‘나선’, ‘상징’, ‘거울’과 같은 용어가 등장합니다. 사용자는 이러한 AI 사용 방식이 대규모 정신 건강 문제를 야기할 수 있다고 우려하며 OpenAI 안전팀에 연락했습니다. 댓글에서는 이것이 AI가 직접 ‘세뇌’한 것이라기보다는 개인이 기존에 가지고 있던 심리적 취약성이 AI에 의해 증폭된 것일 가능성이 더 높으며, 역사적으로 유사한 현상이 TV, 라디오 등 다른 매체와 관련하여 발생한 적도 있다는 의견이 지배적이었습니다 (출처: Reddit r/ChatGPT)