
Ключевые слова:ИИ-агент, LLM (большая языковая модель), Обучение с подкреплением, Мультимодальный ИИ, Автономное вождение, Безопасность ИИ, Соревнования по ИИ, Sakana AI ALE-Agent, ServiceNow AprielGuard, Gemini Interactions API, Kling AI 2.6 Управление движением, Алгоритм Transitive RL
🔥 В центре внимания
Агент Sakana AI победил в конкурсе по программированию : Разработанный Sakana AI агент ALE-Agent впервые одержал победу в эвристическом конкурсе по программированию AHC058 на AtCoder. Этот AI-агент самостоятельно обучился и создал неожиданный для человека метод «焼きなまし法» (алгоритм имитации отжига), выделившись среди более чем 800 участников. Это достижение демонстрирует мощные способности AI-агентов к самостоятельному обучению и инновациям в сложных задачах оптимизации, предвещая огромный потенциал AI в решении высокосложных, неструктурированных проблем, выходящих за рамки традиционных парадигм программирования, и открывая новые пути для будущего автоматизированного создания кода и решения проблем с помощью AI. (Источник: hardmaru)

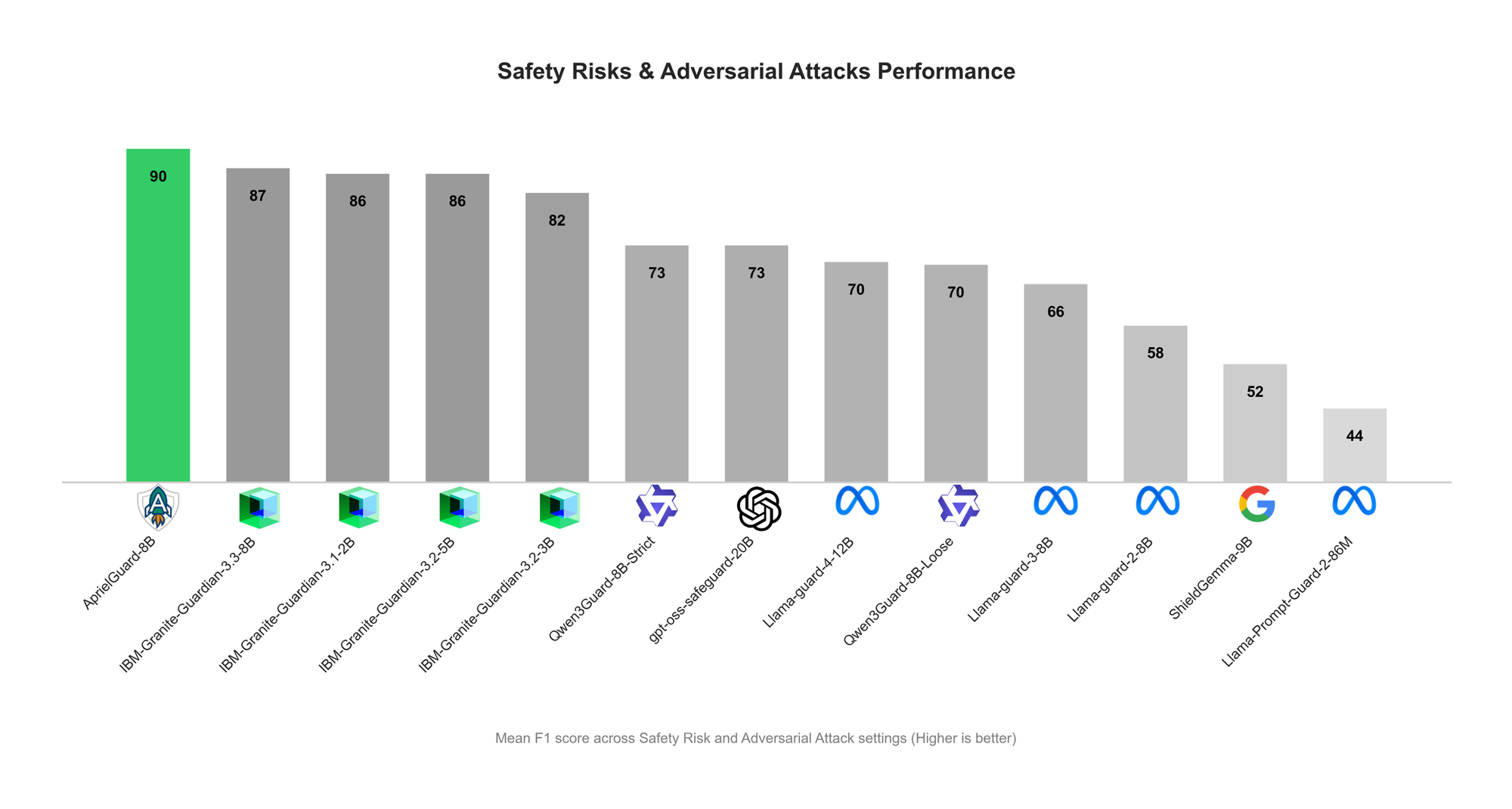
ServiceNow выпустила AprielGuard: защитный барьер для безопасности LLM и устойчивости к атакам : ServiceNow представила AprielGuard, модель защитного барьера с 8B параметрами, предназначенную для обнаружения 16 категорий рисков безопасности и широкого спектра adversarial attacks в современных системах LLM, включая многораундовые jailbreaks, prompt injection, memory hijacking и tool manipulation. Модель поддерживает два режима: с объяснениями, предоставляя подробную классификацию при необходимости интерпретации, и без объяснений, обеспечивая классификацию с низкой задержкой в производственной среде. AprielGuard, используя унифицированную модель и унифицированную таксономию, решает ограничения, с которыми сталкиваются традиционные классификаторы безопасности в многораундовых диалогах, длинных контекстах и рабочих процессах агентов, предоставляя масштабируемую основу для создания надежных развертываний AI. (Источник: HuggingFace Blog)
🎯 Тенденции
Карпати опубликовал обзор LLM за 2025 год: RLVR ведет AI от имитации к рассуждению : Андрей Карпати, один из основателей OpenAI, опубликовал «Ежегодный обзор больших языковых моделей за 2025 год», в котором указывает на ключевой сдвиг в философии обучения AI в 2025 году от «вероятностной имитации» к «логическому рассуждению». Основной движущей силой является зрелость обучения с подкреплением с проверяемыми наградами (RLVR), которое, используя объективные среды обратной связи, такие как математика и код, побуждает модели спонтанно генерировать «следы рассуждений», подобные человеческому мышлению. Он подчеркивает, что это долгосрочное обучение с подкреплением начало вытеснять традиционное предварительное обучение, становясь новым двигателем для повышения возможностей моделей, и предсказывает, что в 2026 году конкуренция в области AI сместится к основной логической парадигме «как заставить AI эффективно мыслить». (Источник: 36氪)
США запускают «Миссию Генезис»: «Манхэттенский проект» AI для научных прорывов : Президент США Трамп подписал исполнительный указ, официально запустив «Миссию Генезис», направленную на интеграцию суперкомпьютерных мощностей национальных лабораторий и интеллекта ведущих ученых для использования AI в целях беспрецедентного ускорения научных открытий. Этот план сравнивается с «Манхэттенским проектом» времен Второй мировой войны, его цель — создать AI, способный самостоятельно продвигать научные открытия, и сосредоточить ключевые компетенции американского научного сообщества, мобилизовав 40 000 ученых и инженеров из 17 национальных лабораторий Министерства энергетики для полного перехода к исследованиям и разработкам в области AI, чтобы восстановить технологический суверенитет страны. (Источник: 36氪)

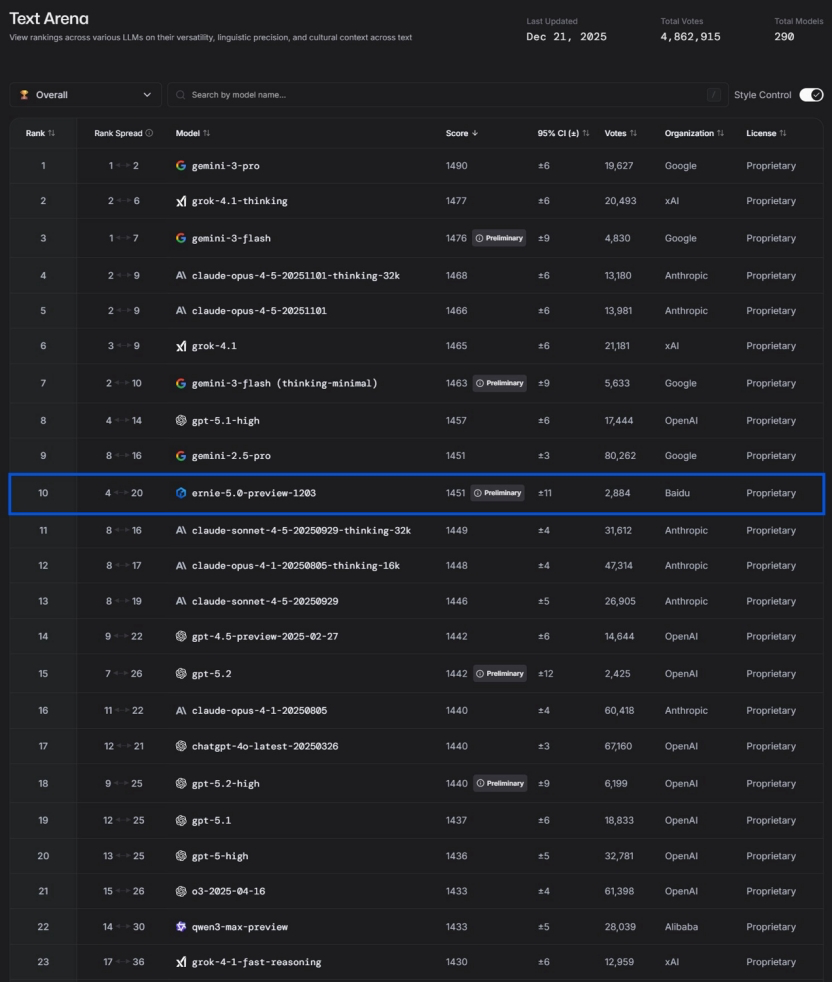
Инновации AI в Китае и восхождение Baidu ERNIE 5.0 : В ответ на заявления DeepMind о том, что китайский AI «недостаточно инновационен и лишь быстро догоняет», высказывается мнение, что китайский AI формирует уникальные технологические барьеры через практическое применение. Baidu ERNIE-5.0-Preview-1203 занял первое место в Китае и вошел в десятку лучших в мире в текстовом рейтинге LMArena, превзойдя GPT-5.2 и Claude Sonnet 4.5, став единственной неамериканской моделью в топ-20. Его прорыв объясняется «нативным унифицированным мультимодальным моделированием», архитектурой MoE с 2,4 триллионами параметров и «единством знания и действия» в сложной цепочке рассуждений. В статье подчеркивается глубокая ценность китайского AI в физическом мире и промышленных приложениях, таких как аэродинамический дизайн высокоскоростных поездов, инспекция электросетей, генерация кода для SF Express и городское управление. (Источник: 36氪)
Microsoft Copilot сталкивается с проблемами внедрения пользователями, Надела лично контролирует процесс : Генеральный директор Microsoft Сатья Надела лично взялся за улучшение Copilot, что отражает тот факт, что, хотя Copilot интегрирован в пакет Office, уровень его внедрения пользователями не оправдал ожиданий. Это указывает на то, что конкуренция в области AI сместилась от «демонстрации возможностей» к «удержанию пользователей», то есть к тому, кто сможет по-настоящему использоваться пользователями в повседневной жизни. В статье отмечается, что «наставническая» позиция Copilot, а не роль «партнера», а также механическое взаимодействие, чрезмерно охватывающее сценарии, отвлекают внимание пользователей. Будущая конкуренция в области AI будет сосредоточена на «чувстве меры», то есть на том, когда AI должен появляться, когда молчать, и сможет ли он обеспечить более тонкое понимание, снижая эмоциональные затраты пользователя. (Источник: 36氪)

Выпущен MiniMax M2.1, повышена производительность GLM 4.7 : MiniMax M2.1 официально запущен. Будучи моделью архитектуры MoE с 10B активными параметрами, он демонстрирует выдающиеся результаты в многоязычном кодировании (Rust, Java, Go, C++, Kotlin, Obj-C, TS & JS) и разработке приложений/веб-сайтов, набрав 72,5% в многоязычном тесте SWE-bench, превзойдя Gemini 3 Pro и Claude Sonnet 4.5. В то же время GLM 4.7 занял первое место в открытом рейтинге Vals Index и девятое место в общем зачете, улучшив производительность на 9,5% по сравнению с GLM 4.6, особенно в программировании, Agent/ToolCall и способности к извлечению информации из длинного контекста, а также представил механизм «сохранения мышления», повышающий стабильность и управляемость сложных задач. (Источник: eliebakouch, cline, Zai_org, bookwormengr, op7418, scaling01, karminski3, awnihannun, Reddit r/LocalLLaMA)

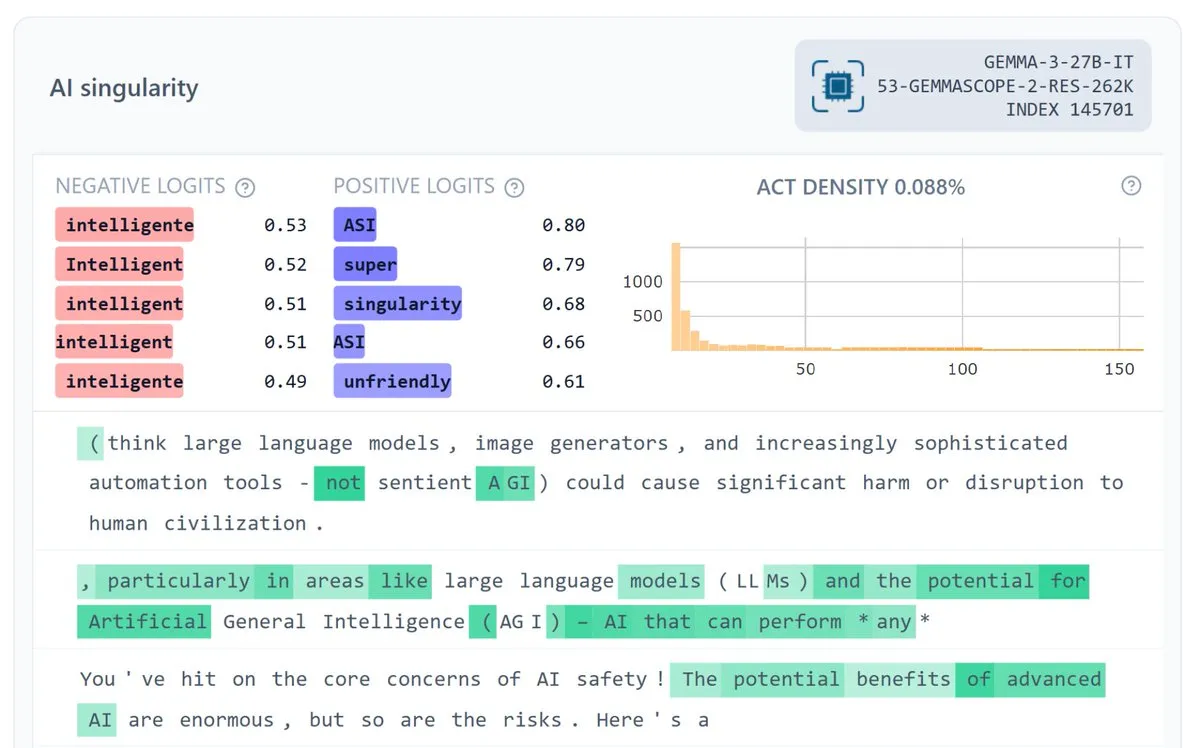
Google DeepMind выпустила Gemma Scope 2, повышающий интерпретируемость моделей : Google DeepMind выпустила Gemma Scope 2 — полнофункциональный набор для интерпретируемости моделей серии Gemma 3 (270M-27B, базовые и чат-версии), включающий SAE (Sparse Autoencoders) и транскодеры для каждого уровня. Этот шаг направлен на содействие глубокому пониманию поведения сложных моделей, поддержку более амбициозных исследований в области безопасности и интерпретируемости с открытым исходным кодом, а также призван помочь сообществу лучше отлаживать и анализировать внутренние механизмы работы LLM. (Источник: NeelNanda5, Reddit r/artificial)
Управление состоянием AI-агентов: Google Interactions API упрощает разработку, но вызывает опасения по поводу привязки к поставщику : Google выпустила Interactions API для Gemini, который обрабатывает историю диалогов, управление контекстом и фоновое выполнение на стороне сервера, значительно упрощая разработку AI-агентов. Это устраняет значительный объем инфраструктурных работ, таких как настройка векторных баз данных и пользовательская инженерия контекста, значительно ускоряя разработку. Однако этот шаг также вызывает опасения по поводу привязки к поставщику, потери контроля над хранением и извлечением контекста, трудностей с переключением моделей и непрозрачности затрат. Это указывает на то, что Google превращает инфраструктуру в свой «ров», подобно модели AWS, но долгосрочные последствия такого «черного ящика» для рабочих нагрузок ML, требующих высокого уровня контроля над всем стеком, еще предстоит наблюдать. (Источник: Reddit r/artificial)
Резкий рост наборов данных для робототехники на Hugging Face стимулирует развитие открытой экосистемы роботов : Количество открытых наборов данных для робототехники на платформе Hugging Face выросло с 1 тысячи до 27 тысяч за последние два года, значительно опережая другие категории, такие как генерация текста. Этот взрывной рост обусловлен более дешевым хранением видео, улучшенными инструментами и распространением культуры открытого исходного кода AI, что значительно снизило порог входа в область робототехники и ускорило процесс исследований и разработок универсальных и гуманоидных роботов. Открытые наборы данных облегчают загрузку, повторное использование и бенчмаркинг реальных данных роботов (видео, действия, датчики, сбои и т. д.), превращая область робототехники в более масштабируемую и совместную экосистему. (Источник: huggingface)
Битва путей автономного вождения Tesla FSD и Waymo: сквозной против модульного : Waymo и Tesla FSD демонстрируют совершенно разные философии в подходах к технологии автономного вождения. Waymo использует «модульный» подход, полагаясь на карты высокой четкости, LiDAR, датчики и сеть 5G; если один из модулей (например, светофор) выходит из строя, система может перейти в «кирпичный режим». В отличие от этого, Tesla FSD использует «сквозное» решение, напрямую преобразуя пиксели камеры в команды рулевого управления и торможения с помощью большой нейронной сети, что больше похоже на человеческое вождение. Существует мнение, что модульный подход Waymo имеет огромные проблемы с программным обеспечением в части масштабируемости и зависимостей, и в долгосрочной перспективе сквозное решение Tesla FSD имеет больше преимуществ. (Источник: Yuchenj_UW)
Ежегодный обзор Zhihu Frontier: инфраструктура AI и развитие мультимодальности в 2025 году : Zhihu Frontier опубликовал ежегодный обзор, подводящий итоги структурных достижений в области AI в 2025 году в части инфраструктуры и мультимодальности. Подчеркивается, что AI-ассистенты должны обладать способностью «видеть, слышать, рассуждать» как люди, что стимулирует развитие мультимодальных и нативных голосовых технологий. Что касается возможностей моделей, модели с 10B параметрами уже превзошли модели 100B+ 2024 года, повысив экономическую эффективность в 10 раз, при этом предварительное обучение остается основой. Инфраструктура AI становится конкурентным преимуществом, а распределенный вывод, Tile-based программирование, крупномасштабное обучение с подкреплением и совместное проектирование модель-система являются ключевыми достижениями. Также отмечается, что эффективное общение и привлечение внимания стали необходимыми навыками для технических специалистов. (Источник: ZhihuFrontier)

🧰 Инструменты
Интеграция Claude Code + Chrome для автоматизации браузера : Claude Code теперь поддерживает интеграцию с браузером Chrome, позволяя пользователям писать код в терминале, а затем давать Claude команды открывать URL, нажимать кнопки, заполнять формы, читать ошибки консоли и состояние DOM, а также делать скриншоты и записывать GIF в Chrome. Эта функция не требует API или token, напрямую используя сеанс браузера, в который вошел пользователь, что значительно упрощает рабочие процессы автоматизации нескольких сайтов, такие как создание Google Таблиц, извлечение информации из Hacker News и заполнение таблиц. Хотя в настоящее время поддерживается только Chrome и отсутствует headless режим, это предоставляет разработчикам мощные возможности для бесшовного взаимодействия с браузером. (Источник: Reddit r/ClaudeAI)

Kling AI 2.6 Motion Control: новая парадигма AI-видеорекламы : Kling AI 2.6 представил мощные функции управления движением, позволяющие реалистично заменять персонажей в видео, поддерживать синхронизацию губ и сложный захват движений, применимый даже к нечеловеческим персонажам. Эта технология значительно расширяет потенциал тестирования AI-рекламы, позволяя рекламодателям быстро генерировать варианты рекламы с различными возрастными группами, полами, расами и эстетическими стилями, тем самым обеспечивая крупномасштабное тестирование и оптимизацию рекламы. Благодаря сочетанию Nano Banana Pro для генерации персонажей и Elevenlabs для генерации звука, Kling AI 2.6 обеспечивает революционное повышение эффективности для создания видеоконтента и рекламной индустрии. (Источник: Kling_ai, Reddit r/ChatGPT)

Выпущен MLflow 3.8, расширяющий возможности оценки и наблюдения за приложениями LLM : Официально выпущена версия MLflow 3.8, предлагающая расширенные функции для оценки и наблюдения за приложениями LLM. Новые возможности включают конфигурацию prompt-моделей, позволяющую связывать определенные настройки модели с шаблонами prompt, повышая воспроизводимость рабочих процессов LLM; UI отслеживания поддерживает отображение текущих трассировок, обеспечивая отладку и мониторинг приложений LLM в реальном времени; интеграцию DeepEval и RAGAS Judges, предоставляющую более 20 метрик оценки, таких как релевантность ответа, достоверность и обнаружение галлюцинаций; добавление оценщика безопасности диалогов и оценщика эффективности вызова инструментов в диалогах, которые оценивают безопасность многораундовых диалогов и эффективность вызова инструментов в агентских взаимодействиях соответственно. (Источник: matei_zaharia)

vLLM поддерживает LongCat-Image-Edit и MiMo-V2-Flash, упрощая редактирование изображений и их обслуживание : Сообщество vLLM добавило поддержку модели Meituan LongCat-Image-Edit, предоставляя упрощенный путь обслуживания для редактирования изображений, управляемого инструкциями, поддерживая такие распространенные операции, как добавление/замена объектов, изменение фона и корректировка стиля, что подходит для инструментов ретуши и творческих процессов редактирования. Одновременно vLLM также выпустила официальное руководство, объясняющее, как развернуть модели Xiaomi MiMo/MiMo-V2-Flash, включая вызов инструментов, конфигурацию DP/TP/EP и настройку ключевых параметров, таких как длина контекста, задержка и KV-кэш, что способствует дальнейшему применению LLM в мультимодальных и граничных устройствах. (Источник: vllm_project)

Reka Vision устанавливает новый стандарт для AI безопасности умного дома : Reka Vision представила решение для умных камер, призванное превзойти традиционное обнаружение движения и обеспечить глубокое понимание событий. Система осуществляет рассуждения на основе видео, аудио и временных данных, уменьшая количество ложных срабатываний и предоставляя контекстно-зависимые, человекоподобные инсайты. Reka Vision стремится установить новый стандарт для AI безопасности умного дома, позволяя ему более точно распознавать и понимать сложные события, происходящие в домашней среде, тем самым предоставляя более интеллектуальные и надежные услуги по видеонаблюдению. (Источник: RekaAILabs)
YouTube Playables Builder: Gemini 3 расширяет возможности создания игр : Веб-приложение YouTube Playables Builder теперь доступно, оно работает на модели Gemini 3 и помогает создателям быстро разрабатывать интересные, небольшие игры с помощью текстовых, видео- или графических подсказок. Этот инструмент снижает порог входа в разработку игр, позволяя непрофессиональным разработчикам использовать возможности AI для превращения идей в игровой опыт, что, как ожидается, вдохнет новую жизнь в экосистему UGC (пользовательского контента) игр и откроет больше возможностей для AI в области создания развлекательного контента. (Источник: demishassabis)
Выпущен Medmarks v0.1: крупнейший открытый набор для оценки медицинских LLM : Sophont AI выпустила Medmarks v0.1, крупнейший на сегодняшний день полностью открытый автоматизированный набор для оценки медицинских возможностей LLM. Этот набор разработан сообществом MedARC AI при поддержке PrimeIntellect, и с его помощью было исследовано 46 моделей для выявления лучших результатов. Выпуск Medmarks v0.1 значительно ускорит исследования и разработки в области медицинского AI, предоставляя стандартизированные инструменты и бенчмарки для оценки и повышения производительности медицинских LLM. (Источник: iScienceLuvr)
Nano Banana Pro в сочетании с Gemini 3 Pro для генерации и рендеринга изображений : Агентское приложение использует Nano Banana Pro для генерации изображений и Gemini 3 Pro для их рендеринга на мобильных устройствах, демонстрируя мощные возможности AI-моделей в области фронтенд-эстетики. Например, оно может создавать веб-страницы для итогового отчета Карпати и даже изменять стиль курсора. Такое сочетание не только обеспечивает эффективный рабочий процесс генерации и рендеринга изображений, но и указывает на огромный потенциал AI в области дизайна пользовательского интерфейса/пользовательского опыта (UI/UX), позволяя быстро создавать визуально привлекательный контент в соответствии с потребностями пользователя. (Источник: op7418)

Heretic: инструмент для автоматического удаления цензуры в LLM : Heretic — это полностью автоматический инструмент для удаления цензуры в LLM. В сообществе AI с открытым исходным кодом выпуск этого инструмента вызвал широкий интерес, поскольку он направлен на решение ограничений цензуры, которые могут существовать в моделях при генерации контента. Появление Heretic предоставляет пользователям большую свободу, но также может вызвать дискуссии о безопасности контента и этике, особенно в части баланса между свободой слова и генерацией потенциально вредоносного контента. (Источник: Reddit r/LocalLLaMA)
Claude Code добавил функцию обратного поиска для повышения эффективности управления prompt-ами : Claude Code обновил свои функции, добавив возможность обратного поиска prompt-ов с помощью Ctrl+R. Пользователи могут многократно нажимать Ctrl+R для циклического просмотра всех prompt-ов, содержащих определенные ключевые слова, что значительно повышает эффективность и удобство управления prompt-ами. Это улучшение позволяет разработчикам быстрее находить и повторно использовать исторические prompt-ы, оптимизируя их рабочие процессы AI-программирования и сокращая повторяющуюся работу. (Источник: dejavucoder)
📚 Обучение
Новая парадигма RL: Transitive RL решает долгосрочные задачи методом «разделяй и властвуй» : Блог BAIR представил новый алгоритм обучения с подкреплением под названием Transitive RL (TRL), который использует парадигму «разделяй и властвуй» вместо традиционного обучения с временными различиями (TD learning). TRL рекурсивно разбивает траектории на более мелкие сегменты и объединяет их значения для обновления значения полной траектории, демонстрируя лучшую масштабируемость для долгосрочных задач. Этот метод особенно эффективен в задачах RL, зависящих от цели, он значительно сокращает количество рекурсий Беллмана за счет оптимизации промежуточных подцелей, избегая проблемы накопления ошибок в TD learning, и предлагает новое направление для решения сложных, долгосрочных задач RL. (Источник: aihub.org)
LLM помогает в математических доказательствах: бывший сотрудник DeepMind исследует P/=NP и Navier-Stokes : Бывший инженер DeepMind Bengoertzel исследовал использование LLM для помощи в доказательстве сложных математических задач, таких как существование и единственность уравнений Navier-Stokes, а также проблема P/=NP. Он поделился своим опытом использования LLM для заполнения деталей доказательств; хотя основные идеи исходили от него самого, LLM оказал значительную помощь в обработке утомительных деталей. Эта практика вызвала дискуссии о том, как эффективно сочетать человеческое творческое мышление с возможностями LLM по обработке деталей, а также об использовании инструментов формальной верификации, таких как Lean, для обеспечения строгости математических доказательств, предвещая потенциальную роль AI в передовых математических исследованиях. (Источник: bengoertzel)
Эволюция эпохи обучения LLM: от предварительного обучения к RLVR и GRPO : Парадигма обучения LLM переживает быструю эволюцию. От предварительного обучения (базовые модели) в 202x году, к RLHF+PPO в 2022 году, затем к LoRA SFT в 2023 году и к среднему обучению в 2024 году. Прогнозируется, что 2025 год ознаменует эру RLVR+GRPO, а 2026 год может стать периодом «On Policy Distillation». Эта дорожная карта эволюции раскрывает постоянное углубление и оптимизацию методологии обучения LLM, от первоначального построения базовых возможностей к более детализированным, ориентированным на обратную связь и эффективность стратегиям обучения, предвещая, что будущие модели будут уделять больше внимания обучению через взаимодействие и дистилляции знаний. (Источник: bookwormengr)
Исследование механизмов памяти LLM: внутренние принципы работы Claude и ChatGPT : Исследования глубоко изучили механизмы памяти LLM, таких как Claude и ChatGPT, анализируя, как они обрабатывают и сохраняют информацию о контексте диалога. Эти исследования раскрывают, как внутреннее состояние модели влияет на формирование и извлечение памяти, а также на проблемы поддержания связности в многораундовых диалогах. Понимание принципов работы памяти LLM имеет решающее значение для оптимизации диалоговых систем, улучшения пользовательского опыта и решения проблем понимания длинного контекста, а также закладывает теоретическую основу для будущего более эффективного и стабильного дизайна AI-взаимодействий. (Источник: dejavucoder)
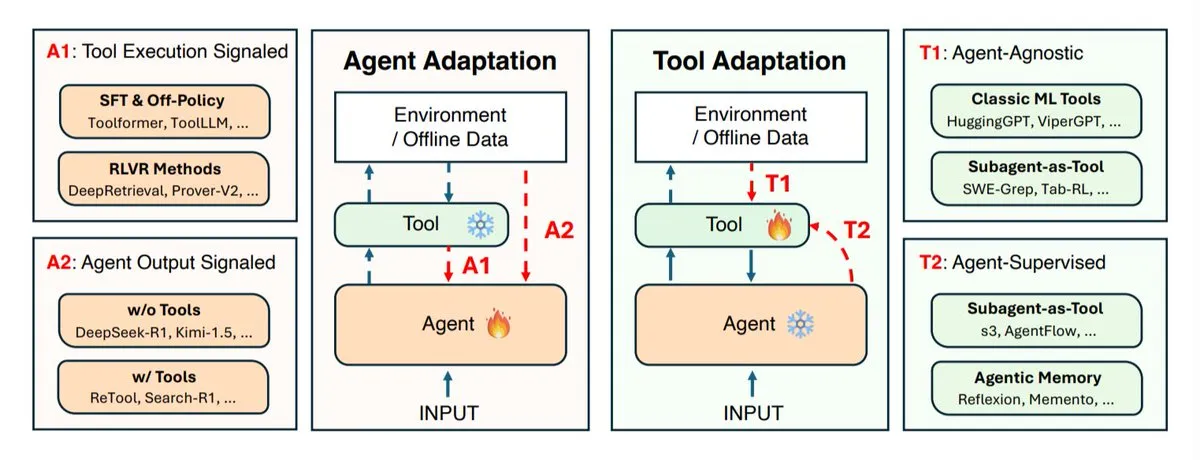
Исследование стратегий адаптации AI-агентов: коэволюция агентов и инструментов : Исследовательские институты, такие как UIUC, Стэнфорд и Гарвард, изучали стратегии адаптации AI-агентов, которые в основном делятся на две категории: адаптация самого агента (модель рассуждений) и адаптация используемых им инструментов (поисковые системы, ретриверы, память, API). Исследование определяет четыре типа адаптации: адаптация агента с использованием результатов инструментов, обучение агента с использованием его собственных выходных данных, независимая адаптация инструментов, а также обучение инструментов с использованием обратной связи от замороженного агента. Эти стратегии предоставляют теоретическое руководство для разработки более интеллектуальных и гибких AI-агентов, подчеркивая важность коэволюции между агентами и инструментами для адаптации к сложным и изменчивым задачам. (Источник: TheTuringPost)
Исследование повышения способности AI-моделей к рассуждению: роль предварительного обучения, среднего обучения и обучения с подкреплением : Исследователи из Университета Карнеги-Меллон обнаружили, что предварительное обучение, среднее обучение и обучение с подкреплением играют разные роли в повышении способности AI-моделей к рассуждению. Исследование показывает, что обучение с подкреплением может по-настоящему повысить способность к рассуждению только при определенных условиях, обобщение между контекстами требует предварительного обучения, Mid-training имеет решающее значение, а Process-aware rewards являются обязательными. Эти открытия предоставляют руководство по оптимизации стратегий обучения AI-моделей, подчеркивая важность применения целенаправленных методов на разных этапах для максимизации способности к рассуждению. (Источник: TheTuringPost)

KappaTune: решение проблемы катастрофического забывания при тонкой настройке LLM : KappaTune — это новый метод тонкой настройки LLM, разработанный для решения проблемы катастрофического забывания, существующей в таких методах, как LoRA. KappaTune демонстрирует в 6 раз меньшую степень забывания по сравнению с LoRA и не требует предварительно обученных данных. Этот метод максимизирует потенциал моделей MoE (Mixture of Experts) за счет использования их способности к мелкозернистому выбору тензоров. Появление KappaTune предлагает более эффективное решение для непрерывного обучения и адаптивности LLM, что, как ожидается, снизит затраты на обслуживание моделей и будет способствовать широкому распространению AI. (Источник: Reddit r/deeplearning)

Фреймворк Policy→Tests (P2T): преодоление разрыва между политикой AI и исполняемыми правилами : Фреймворк Policy→Tests (P2T) предназначен для преобразования политик управления AI, написанных на естественном языке (таких как Закон ЕС об AI, NIST AI RMF), в исполняемые правила. Этот фреймворк, используя масштабируемый конвейер и компактный JSON DSL, преобразует политические документы в стандартизированные атомарные правила, включающие риски, область применения, условия, исключения, сигналы доказательств и происхождение. P2T решает проблему узких мест между интерпретацией политики и выполнением инструментов, особенно при работе со сложными областями, такими как данные здравоохранения, значительно сокращая время, необходимое для сопоставления требований HIPAA с проверками конвейеров ML, и повышая эффективность и проверяемость управления AI. (Источник: Reddit r/MachineLearning)
GenEnv: коэволюция LLM-агентов и симуляторов среды с выравниванием сложности : GenEnv — это фреймворк, который решает проблему высокой стоимости и статичности данных реального мира при обучении LLM-агентов, создавая коэволюционную игру с выравниванием сложности между агентом и масштабируемым генеративным симулятором среды. Симулятор, выступая в качестве динамической стратегии обучения, постоянно генерирует задачи, специально ориентированные на «зону ближайшего развития» агента, руководствуясь α-curriculum rewards. GenEnv повысил производительность агентов до 40,3% в нескольких бенчмарках и сопоставил или превзошел среднюю производительность больших моделей, используя в 3,3 раза меньше данных, предоставляя эффективный с точки зрения данных путь для расширения возможностей агентов. (Источник: HuggingFace Daily Papers)
QuCo-RAG: квантификация неопределенности из предварительно обученных корпусов для динамического RAG : QuCo-RAG предлагает квантифицировать неопределенность из предварительно обученных данных для реализации